


![]() Bài viết được ghim
Bài viết được ghim

Độ hot của Langchain
Langchain là một framework vô cùng hot hit trong thời gian gần đây. Nó được sinh ra để tận dụng sức mạnh của các mô hình ngôn ngữ lớn LLM như ChatGPT, LLaMA... để tạo ra các ứng dụng trong thực tế. Dù mới được phát triển cách đây khoảng 6 tháng (10/2022) và vẫn được cập nhật liên tục hàng ngày nhưng trên Github Langchain đã nhận được những tương tác khủng với lượng star lê...

Tất cả bài viết
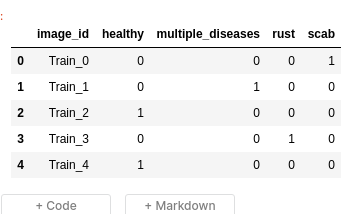
Bài viết này mình sẽ viết về cách phân loại bệnh của lá cây dựa dữ liệu mình lấy từ Plant Pathology Challenge của kaggle.
Dataset Ở đây BTC cung cấp một tập dữ liệu lá được chụp từ cây táo và yêu cầu phải xác định được bệnh của bức ảnh đó. Tập ảnh bao gồm 4 loại lá : healthy, scab, rust và có nhiều hơn một loại bệnh. Dataset bao gồm:
-
file train.csv
Trong file train.csv chứa 5 cột: im...

- Lời mở đầu
Bài toán xác định góc (corner detection) được sử dụng khá nhiếu trong các bài toán về computer vision như image matching, object detection, ...
Ứng dụng của nó trong xử lý ảnh như thế nào ?. Trong các bài toán image matching, hai ảnh bên dưới là hai ảnh chụp cùng một cảnh với nhiều góc khác nhau. Khi ta muốn tìm điểm tương tự (feature point) của hai ảnh để nối ảnh, chúng ta t...

Các phần nội dung chính sẽ được đề cập trong bài blog lần này
- Object Detection task
- Giới thiệu về Zalo AI Hackathon
- Phân loại các thuật toán về Object Detection
- Faster-RCNN
- RPN (Region Proposal Network)
- Loss Function (RPN)
- RoI Pooling
- Detection model
- Loss Function (Faster-RCNN)
- Metric Evaluation
- Huấn luyện mô hình
- Kết quả đánh giá và thực nghiệm
- Kết luận
- Other
- Refe...
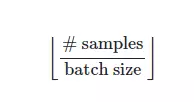
Ở bài viết này mình sẽ viết về cách tạo Data Generator với Keras như thế nào. (nhạt quá =)) )
Mình sẽ viết gì ở bài này?
- Tại sao lại là Data Generator
- Thực Hành
- Kết Luận
- Reference
Tại sao lại là Data Generator Trên thực tế không phải ai cũng có đủ tiền mua máy khủng và dữ liệu mình cần train chiếm nhiều Ram hơn dung lượng RAM th...

- Lời mở đầu Ở phần 1 về chủ đề Edge Detection, mình đã trình bày về tiêu chuẩn đánh giá một detector như thế nào là một detector tốt cũng như thuật toán Sobel Edge Detection và ví dụ cụ thể. Các bạn có thể xem lại ở đây. Ở phần 2 này, mình xin tiếp tục trình bày về thuật toán Canny Edge Detection. Đây là một thuật toán xác định cạnh được sử dụng phổ biến và hiệu quả trong các bài toán về thị ...
- Lời mở đầu Edge Detection hay bài toán phát hiện cạnh được ứng dụng rất nhiều trong các bài toán về thị giác máy tính. Ví dụ như trong các bài toán như extract information, recognize object, .... Cạnh là nơi mã hóa nhiều thông tin ngữ nghĩa(semantics information) và hình dạng(shape) trong một bức ảnh. Sau đây tôi xin giới thiệu hai thuật toán phổ biến được sử dụng trong phát hiện cạnh(edge...
Các tính chất cơ bản của Quantum Mechanic
Quantum mechanics (QM; also known as quantum physics, quantum theory, the wave mechanical model and matrix mechanics), including quantum field theory, is a fundamental theory in physics describing the properties of nature on an atomic scale. Dịch nghĩa: Cơ học lượng tử, bao gồm cả lý thuyết trường lượng tử là một nền tảng của vật lý nhằm miêu tả các th...
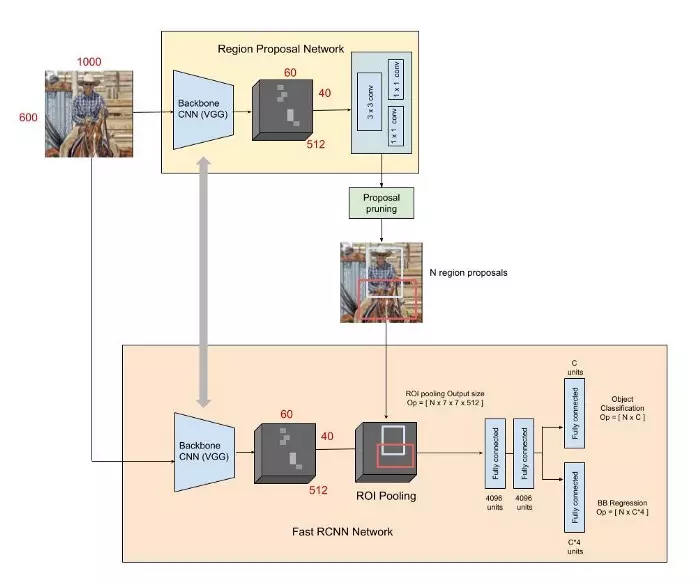
Giới thiệu về mạng Faster R-CNN
- Faster R-CNN là mô hình tốt nhất của họ nhà R-CNN, được công bố đầu tiên vào năm 2015. Phiên bản đầu tiên của Faster R-CNN là R-CNN, với nguyên lí đơn giản. ( Bài này mình sẽ không đi sâu tìm hiểu về R-CNN,bạn đọc có thể tham khảo ở đây. )
- Trong các bài báo của các mạng họ R-CNN, sự phát triển giữa các phiên bản dựa vào hiệu năng tính toán (tích hợp c...

- Introduction 1.1 Competition
Trước tiên mình mình giới thiệu qua về cuộc thi "Global wheat detection" trên kaggle. Hiện tại kaggle đang tổ chức 1 cuộc thi với chủ đề nhận dạng bông lúa mì trong các bức ảnh. Link cuộc thi: global-wheat-detection. Việc nhận dạng lúa mì có ý nghĩa rất lớn đối với các nghiên cứu trong nông nghiệp. Người ta có thể xác định được số lượng, mật độ, kích thước bông ...
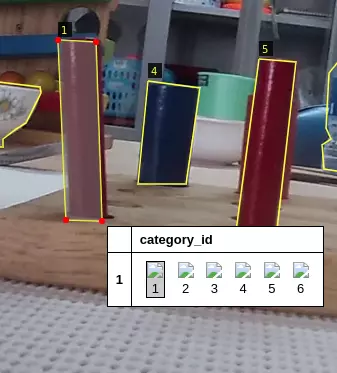
I. Introduction
Xin chào các bạn, để tiếp nối chuỗi bài về Segmentation thì hôm nay mình xin giới thiệu tới các bạn cách để custom dataset và train lại model Mask RCNN cho bài toán segmentation. Trong bài trước mình có giới thiệu tới các bạn về các bước triển khai Mask RCNN cho bài toán segmentation khá chi tiết, các bạn có thể tham khảo thêm theo đường dẫn dưới đây:
https://viblo.asia/p/m...
- Lời nói đầu Bài toán multitask có thể thực hiện đồng thời nhiều task được ứng dụng nhiều trong computer vision. Ví dụ như phân tích khuôn mặt đưa ra dự đoán tuổi, cảm xúc, giới tính hay dự đoán một bông hoa là loại nào? đã được trồng bao nhiêu năm?, .... Tuy nhiên những bài toán multitask thường yêu cầu nhiều nhãn dán trên tập dữ liệu huấn luyện mà chúng ta thường gặp khó khăn trong việc tì...

- Tổng Quan:
Việc đọc reasearch paper ( từ sau mình sẽ dùng là paper cho ngắn ) rất quan trọng nếu bạn muốn hiểu sâu về một phương pháp hoặc một thuật toán nào đó trong Machine Learning hay Deep Learning. Đây là một công việc nghe như đơn giản những thật sự lại không đơn giản một chút nào hết. Một số người khi mới làm quen với 2 lĩnh vực này, chưa có kinh nghiệm chọn lựa paper để đọc hoặc các...
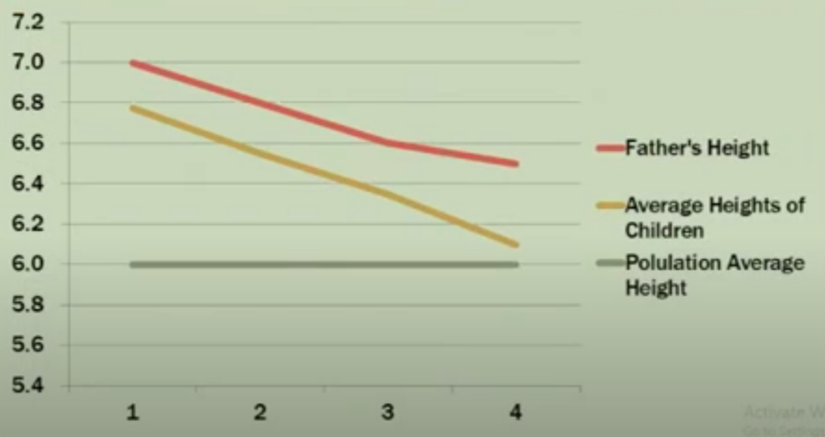
- Regression
Sau khi đọc lại rất nhiều lần bài viết này. Mình bắt đầu tự hỏi tại sao lại có cái tên regression (hồi quy). Cùng với việc tìm tòi wiki và những điều mình học hỏi được trong khóa học gần đây mình được tham gia; mình đã đúc kết ra được nguồn gốc của những cái tên sơ khai nhất trong Machine Learning.
Phân tích hồi quy (regression analysis) là một trong những phương pháp phổ biế...
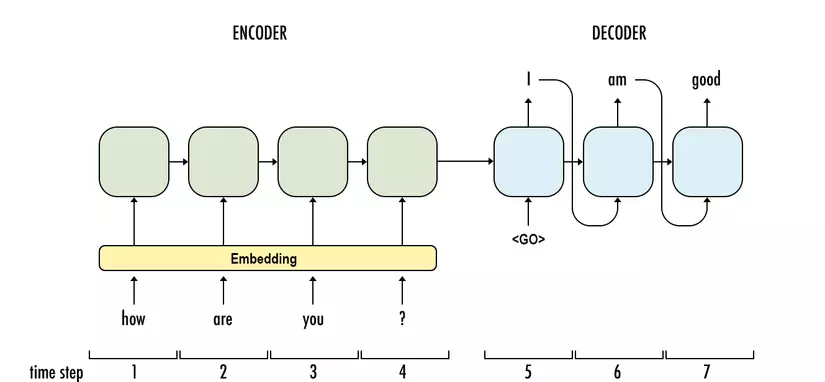
Giới thiệu
Trước khi Google công bố bài báo về Transformers (Attention Is All You Need), hầu hết các tác vụ xử lý ngôn ngữ tự nhiên, đặc biệt là dịch máy (Machine Translation) sử dụng kiến trúc Recurrent Neural Networks (RNNs). Điểm yếu của phương pháp này là rất khó bắt được sự phụ thuộc xa giữa các từ trong câu và tốc độ huấn luyện chậm do phải xử lý input tuần tự. Transformers sinh ra để gi...

Mở bài
Sau khi mình đọc bài này của bạn Sơn team mình về đánh giá điểm khuôn mặt, đến đoạn bắt xem vùng nào chứa khuôn mặt trên ảnh, thì mình chợt nhận ra là mình không biết gì về cái này cả  Sau khi search trên Viblo về Haar Cascade cũng thấy chục bài, tuy nhiên các bài cũng giải thích không được dễ hiểu lắm, nên mình viết thêm một bài nữa cho các bạn càng thêm khó hiểu : )
Sau khi search trên Viblo về Haar Cascade cũng thấy chục bài, tuy nhiên các bài cũng giải thích không được dễ hiểu lắm, nên mình viết thêm một bài nữa cho các bạn càng thêm khó hiểu : )
<sub>Bạn có thể ...

I. Introduction
Xin chào mọi người, trước khi đi vào nội dung bài viết, mọi người cùng xem một vài hình ảnh sau đây trước nhé:
Đây là hình ảnh về các món ăn và đã được phân vùng và nhận biết về loại của nó, cụ thể ở đây chúng ta có cơm, cá hồi, mì ý và bơ... trông khá cool và hay ho phải không mọi người. Thực ra đây là một cuộc thi, challenge về nhận biết các món ăn trên CrowAI trong một ngày...
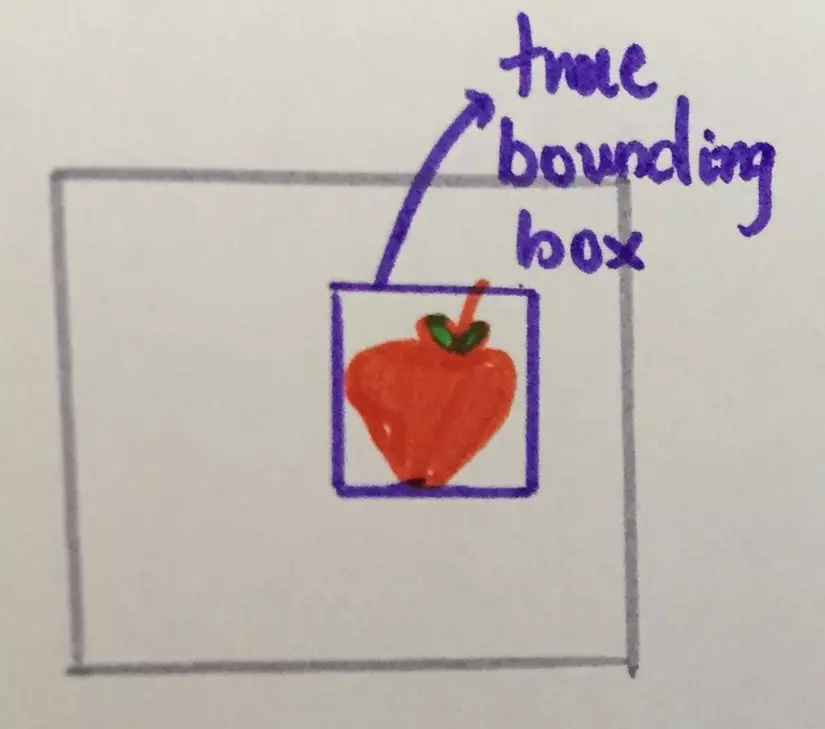
Mục tiêu bài viết: Mang tính thảo luận Đối tượng: begginers về Object Detection I . Intuition
Puzzle 1: Tìm táo. Tưởng tượng bạn muốn có một AI program có khả năng xác định vị trí của quả táo trong ảnh, biết mỗi bức chỉ chưa một quả , và kích thước các quả trong các bức gần bằng nhau. Như sau:
Vị trí của vậy được diễn tả với bounding box, một hình chữ nhật bao sát vật đó.
Khá đơn giản đúng k...

Các nội dung sẽ được đề cập trong bài blog lần này
-
What is Saliency Prediction?
-
Usecases cụ thể
-
1 số tập dữ liệu về saliency prediction
-
Mô hình thuật toán
-
Các phương pháp đánh giá
-
Áp dụng vào bài toán (flower) image search retrieval
-
Tổng kết
-
Tài liệu tham khảo
-
Link github: https://github.com/huyhoang17/flowers102retrievalstreamlit
What is Saliency Prediction?!
- Khi nhìn và...
[IMG]
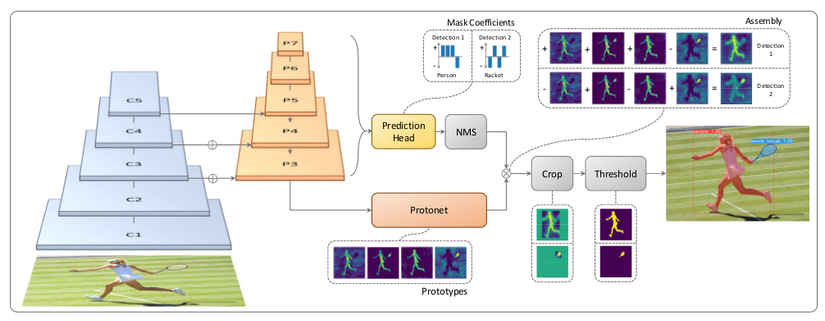
- Introduce Image Segmentation - bài toán gán nhãn/label cho pixel luôn là một chủ đề hot trong Computer Vision - Deep learning. Trong đó, Image Segmentation chia làm 2 nhánh:
- Semantic segment: gán nhãn từng pixel với label là class mà đối tượng thuộc về.
- Instance Segment: là bài toán nâng cao hơn semantic segment - có thể phát hiện, phân biệt từng đối tượng riêng lẻ trong 1 nhóm các đối...
I. Introduction
Xin chào mọi người, chúng ta vẫn tiếp tục sống trong những ngày tháng nhàn nhã nhất trong lịch sử do ảnh hưởng của virus corona, người work remotely, người study online, người tận dụng thời gian này để có 1 kỳ nghỉ holiday, cũng có người chọn cách nâng cao khả năng ngoại ngữ của mình...tớ chọn cách đọc sách và viết viblo nhiều hơn. Sau bài trước về việc làm thế nào để xây dựn...
