
Recommendation System: Từ con số 0 đến hoàn chỉnh có gì?
Bài đăng này đã không được cập nhật trong 6 năm
I. Introduction
Xin chào mọi người, cũng khá lâu rồi mình không chia sẻ được gì cho anh em viblo, phần vì mình lười viết, phần cũng vì cảm thấy kiến thức của bản thân còn hạn hẹp quá  . Nay cũng là ngày gần cuối mình ở Nhật, thời gian bắt đầu dư giả hơn nên quyết định viết bài này chia sẻ tới ae những gì mình học được trong khoảng thời gian ở đây, cũng là một cách để mình refresh lại sau một khoảng thời gian lặp đi lặp lại 1 việc. Như mọi người cũng biết là hầu như mọi trang web bán hàng hiện nay từ nhỏ cho đến lớn đều có chức năng recommend, tức gợi ý ra các sản phẩm đi kèm cho người dùng. Chắc không cần phải bàn đến công dụng của nó rồi, lý do là nó boost được purchasing consumption từ phía người dùng và người được lợi rất lớn từ việc đó là những nhà kinh doanh. Nhưng thực sự đằng sau những thuật toán đó nó hoạt động ra sao, chúng ta cũng nên tò mò chứ nhỉ, vì vậy ở bài viết này tớ sẽ tạo ra một sample và cố gắng chia sẻ chi tiết nhất có thể về một hệ thống recommendation từ lúc bắt đầu đến lúc ra sản phẩm đến với người dùng thì sẽ cần những gì nhé. Hihi, lẹt gâu!
. Nay cũng là ngày gần cuối mình ở Nhật, thời gian bắt đầu dư giả hơn nên quyết định viết bài này chia sẻ tới ae những gì mình học được trong khoảng thời gian ở đây, cũng là một cách để mình refresh lại sau một khoảng thời gian lặp đi lặp lại 1 việc. Như mọi người cũng biết là hầu như mọi trang web bán hàng hiện nay từ nhỏ cho đến lớn đều có chức năng recommend, tức gợi ý ra các sản phẩm đi kèm cho người dùng. Chắc không cần phải bàn đến công dụng của nó rồi, lý do là nó boost được purchasing consumption từ phía người dùng và người được lợi rất lớn từ việc đó là những nhà kinh doanh. Nhưng thực sự đằng sau những thuật toán đó nó hoạt động ra sao, chúng ta cũng nên tò mò chứ nhỉ, vì vậy ở bài viết này tớ sẽ tạo ra một sample và cố gắng chia sẻ chi tiết nhất có thể về một hệ thống recommendation từ lúc bắt đầu đến lúc ra sản phẩm đến với người dùng thì sẽ cần những gì nhé. Hihi, lẹt gâu!
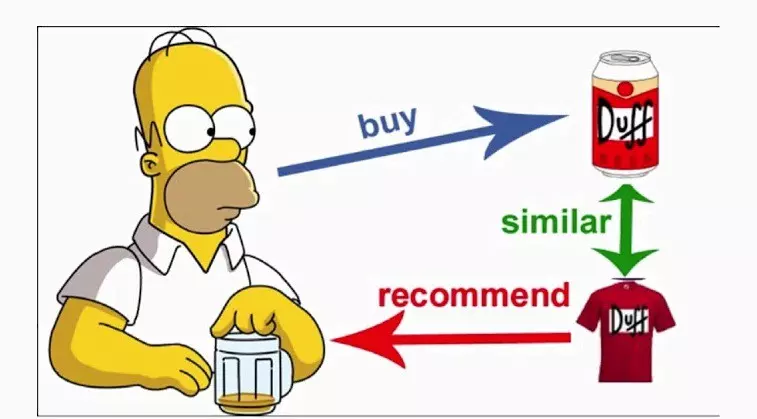
II. What is Recommendation System
Trước khi bắt đầu đi sâu hơn, mình sẽ nói sơ qua cho ae nào chưa rõ bài toán này là gì nhé. Thì nôm na hiểu đơn giản thế này thôi, hệ thống khuyến nghị là hệ thống có khả năng đưa ra những gợi ý cho người dùng những sản phẩm tương tự cho một sản phẩm mà họ đang xem. Ví dụ na: Quần áo, giày dép, đồ dùng gia đình, đồ ăn, đồ uống, ... vân vân mà mây mây, miễn là nó có xu hướng giống hoặc đi kèm với nhau thui.
Một hệ thống khuyến nghị truyền thống sẽ gồm có các cách chính sau để đưa ra gợi ý cho người dùng:
Cách 1: Người ta gọi là Content-Based Recommendation System. Cách này dựa vào thuộc tính của các sản phẩm, ví dụ như tên, nhà sản xuất, giá cả, chỉ số, mô tả... để đưa ra các sản phẩm tương tự nhau
Cách 2: Gọi là Collaborative Filtering Recommendation System cái này thì dựa vào behaviours của những users có xu hướng tương tự để gợi ý ra các sản phẩm cho ngừoi dùng. Có thể tưởng tượng dư này: Anh A mua sản phẩm X, Y, Z, anh B mua sản phẩm X, Y thì khả năng cao anh B cũng sẽ mua Z nên gợi ý Z cho anh B là hợp ní.
Cách 3: Là sự kết hợp của 2 cách trên lại gọi là Hybrid Recommendation System
Mọi ngừoi xem ảnh dưới đây để hiểu thêm nhé:
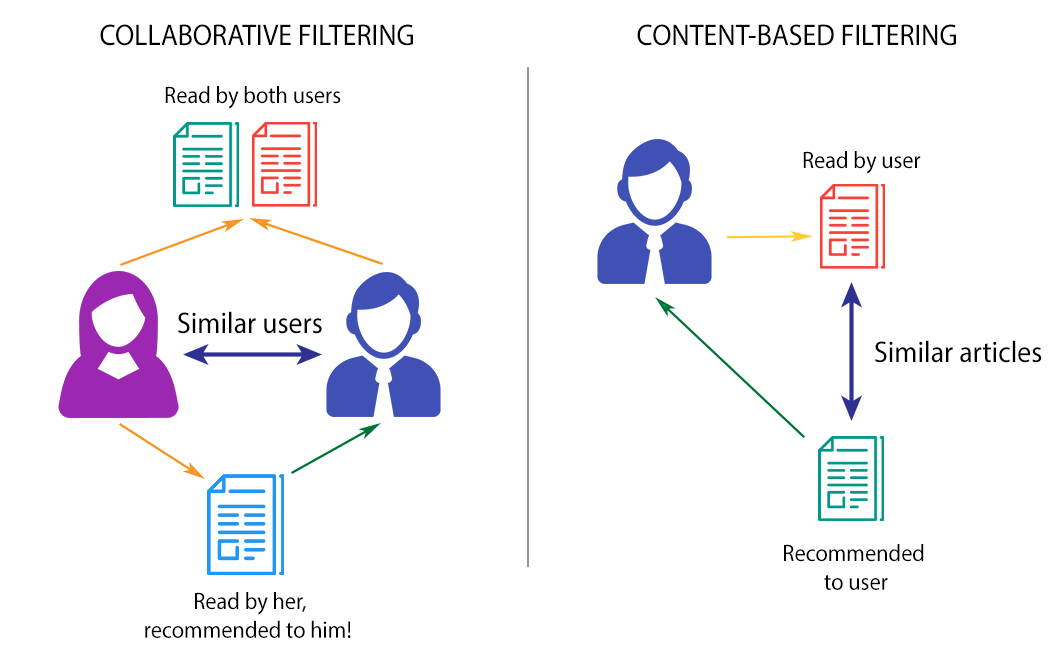
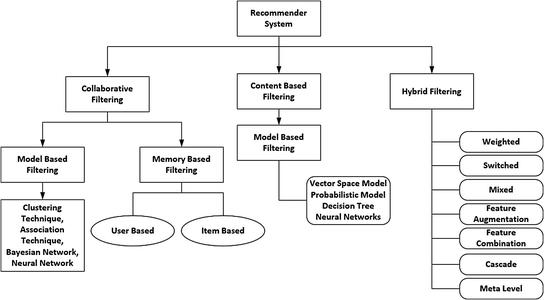
Các papers đã chỉ ra rằng, kết quả từ CF và hybrid là tốt hơn so với CB tuy nhiên nhược điểm của CF là cần phải có lịch sử behaviours của người dùng thì mới có thể xây dựng được. Vì vậy ở thời điểm bắt đầu, CB là một sự lựa chọn tốt, chúng ta có thể làm thêm chức năng lưu log hành vi người dùng để sau này có thể tuỳ chỉnh sang CF nà được.
III. Problem Summary
Bài toán chúng ta cần giải quyết là gợi ý ra các sản phầm rượu có sự tương đồng về mùi vị, giá cả...
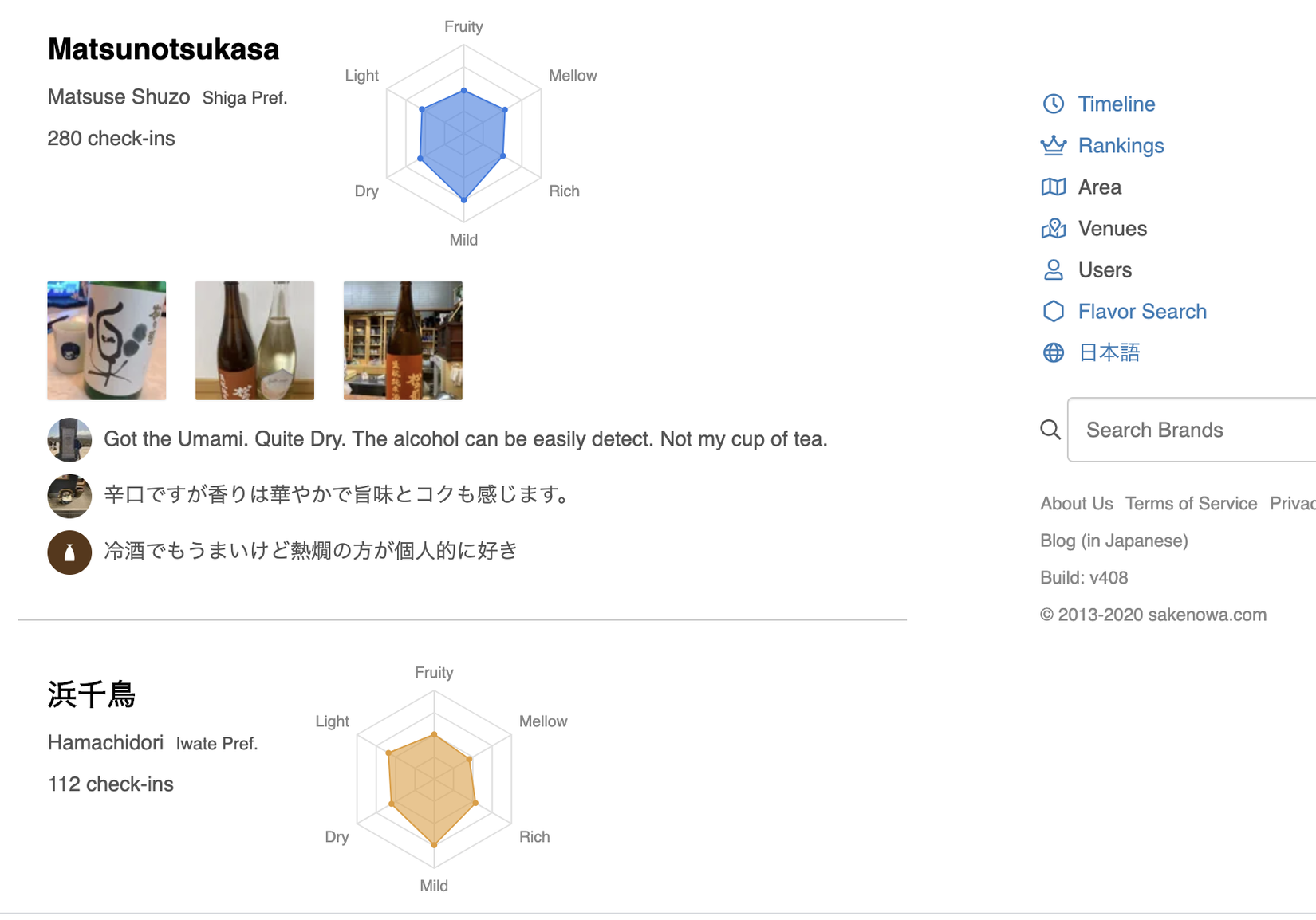
Ví dụ như này, cái này mình lấy trên trang https://sakenowa.com/en/flavor-search đây, nhiệm vụ là tìm ra các sản phẩm có các chỉ số (fruity, mellow, rich, mild, dry, light) giống nhau nhất có thể, để hiểu hơn chúng ta đến phần dataset luôn cho nó nóng nhé.
3.1 Dataset Crash
Thuận toán mình sắp đề cập tới đây có thể áp dụng cho nhiều bài toán khác nhau, nhiều loại rượu khác nhau, quan trọng là chúng ta hiểu được tư tưởng thuật toán thì sau đó có thể tuỳ biến được thui, hehe.
Dữ liệu tớ chuẩn bị được crawl ở trang https://sakenowa.com/ này về, là dữ liệu về rượu Sake, trang này mình thấy khá ổn và đã đi vào hoạt động được 1 thời gian rồi nên có thể coi là một nguồn dữ liệu tốt. Tuy nhiên làm thế nào để crawl được đống dữ liệu này về, ban đầu tớ định dùng scrapy vs splash để crawl, nhưng sau khi mò mẫm tớ thấy trang này có cung cấp API nên chúng ta chỉ cần làm đơn gỉan nhất có thể thôi, miễn sao có data dùng là được rồi, quan trọng gì. Code crawl như nè nha:
import urllib
import json
from pprint import pprint
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
from tqdm import tqdm
import csv
area = 1
count = 50
with open('liquor_data.csv', mode='w', encoding='utf-8') as csv_file:
fieldnames = ['name', 'intl_name', 'brand_name', 'brand_intl_name', 'year_month', 'rank',
'score', 'f1', 'f2', 'f3', 'f4', 'f5', 'f6',
'flavour_tags', 'checkin_count', 'pictures', 'similar_brands', 'id']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames, delimiter=',',
quotechar='"', quoting=csv.QUOTE_MINIMAL)
writer.writeheader()
while area <= 47:
url = 'https://sakenowa.com/api/v2/brands/ranking?areaId={}&count={}'.format(area, count)
print(url)
response = urllib.request.urlopen(url)
text = response.read()
data = json.loads(text)['ranking']
for i in tqdm(range(len(data))):
item = data[i]
year_month = str(item['yearMonth'])
score = float(item['score'])
ranking = int(item['rank'])
brand_summary = item['brandSummary']
id_ = int(brand_summary['brand']['id'])
name = str(brand_summary['brand']['name'])
pictures = [str(i['url']) for i in brand_summary['pictures']]
checkin_count = int(brand_summary['statistics']['checkinCount'])
similar_brands = [str(item['brand']['name']) for item in brand_summary['similarBrands']]
intl_name = None
if 'intlName' in brand_summary['brand'].keys():
intl_name = str(brand_summary['brand']['intlName'])
brand_area_name = None
brand_area_intl_name = None
if 'area' in brand_summary['brand']['brewery'].keys():
brand_area = brand_summary['brand']['brewery']['area']
brand_area_name = str(brand_area['name'])
brand_area_intl_name = str(brand_area['intlName'])
f1 = None
f2 = None
f3 = None
f4 = None
f5 = None
f6 = None
if 'simpleFlavorFeature' in brand_summary.keys():
flavour_feature = brand_summary['simpleFlavorFeature']
f1 = flavour_feature['f1']
f2 = flavour_feature['f2']
f3 = flavour_feature['f3']
f4 = flavour_feature['f4']
f5 = flavour_feature['f5']
f6 = flavour_feature['f6']
tags = ''
flavour_tags = brand_summary['flavorTags']
for tag_item in flavour_tags:
tags += '|{}'.format(tag_item['tag'])
writer.writerow({'name': name, 'intl_name': intl_name,
'brand_name': brand_area_name,
'brand_intl_name': brand_area_intl_name,
'year_month': year_month, 'rank': ranking,
'score': score, 'f1': f1, 'f2':f2, 'f3': f3,
'f4':f4, 'f5': f5, 'f6': f6,
'flavour_tags': tags, 'checkin_count': checkin_count,
'pictures': '|'.join(pictures),
'similar_brands': '|'.join(similar_brands),
'id': id_})
area += 1
Ở đây tớ chỉ lấy những fields mà tớ nghĩ là có ích cho bài toán của mình thui, bạn nào muốn dùng thêm phần nào thì thêm vào code nha. Cùng xem qua xem dữ liệu có gì nào.
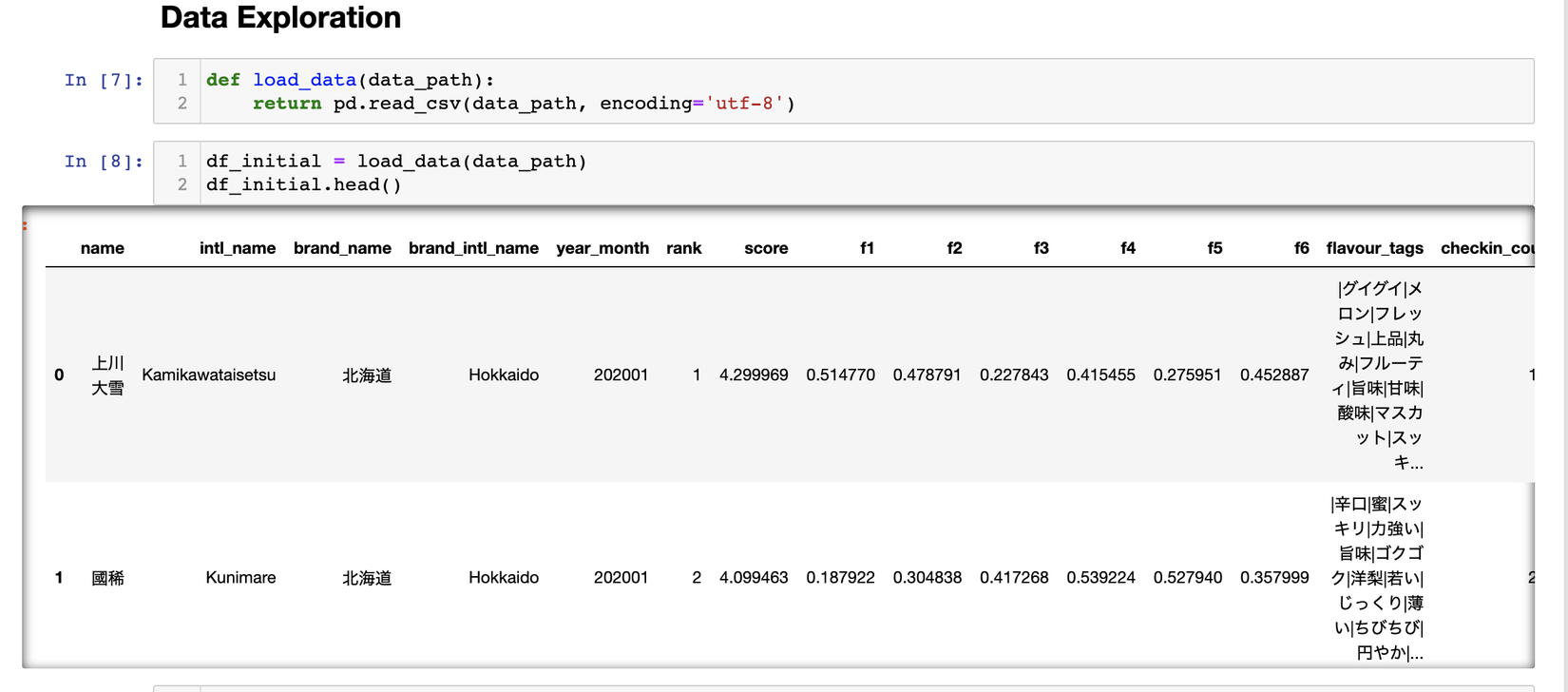
Mục tiêu của bài toán vẫn là gợi ý ra những sản phẩm giống nhau nhất có thể về mùi vị, tớ nhận thấy thẻ tags có liên quan đến các chỉ số mùi vị nên phần thuật toán của tớ sẽ xoay quanh 2 field chính là f1-f6 và flavour_tags.
3.2 Dataset Exploration
Đối với những bài content-based kiểu như thế này, việc hiểu dữ liệu là vô cùng quan trọng, vậy nên chúng ta cần có 1 cái nhìn tổng quát trước đã. Hãy xem ảnh bên dưới nhé:
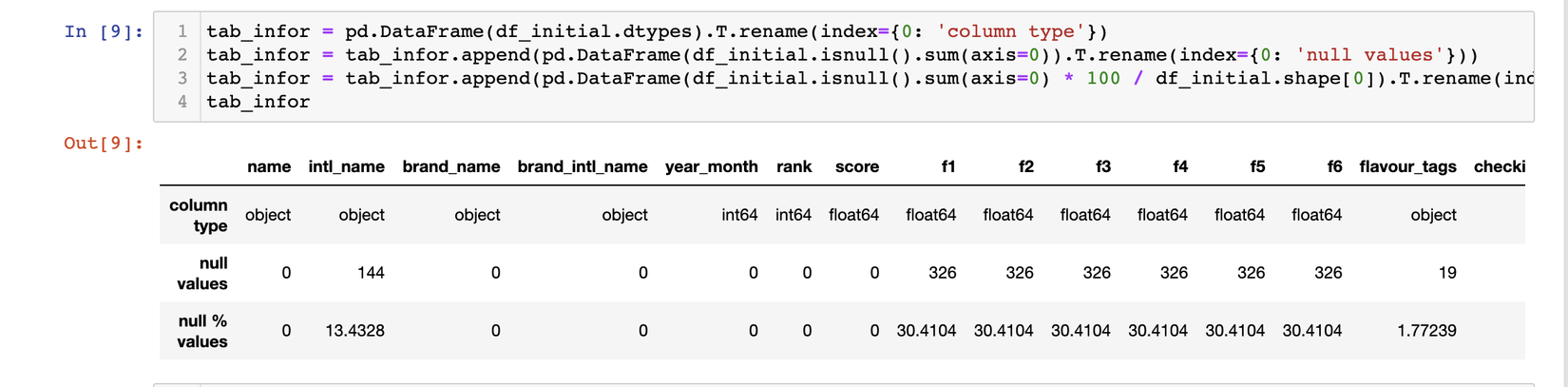
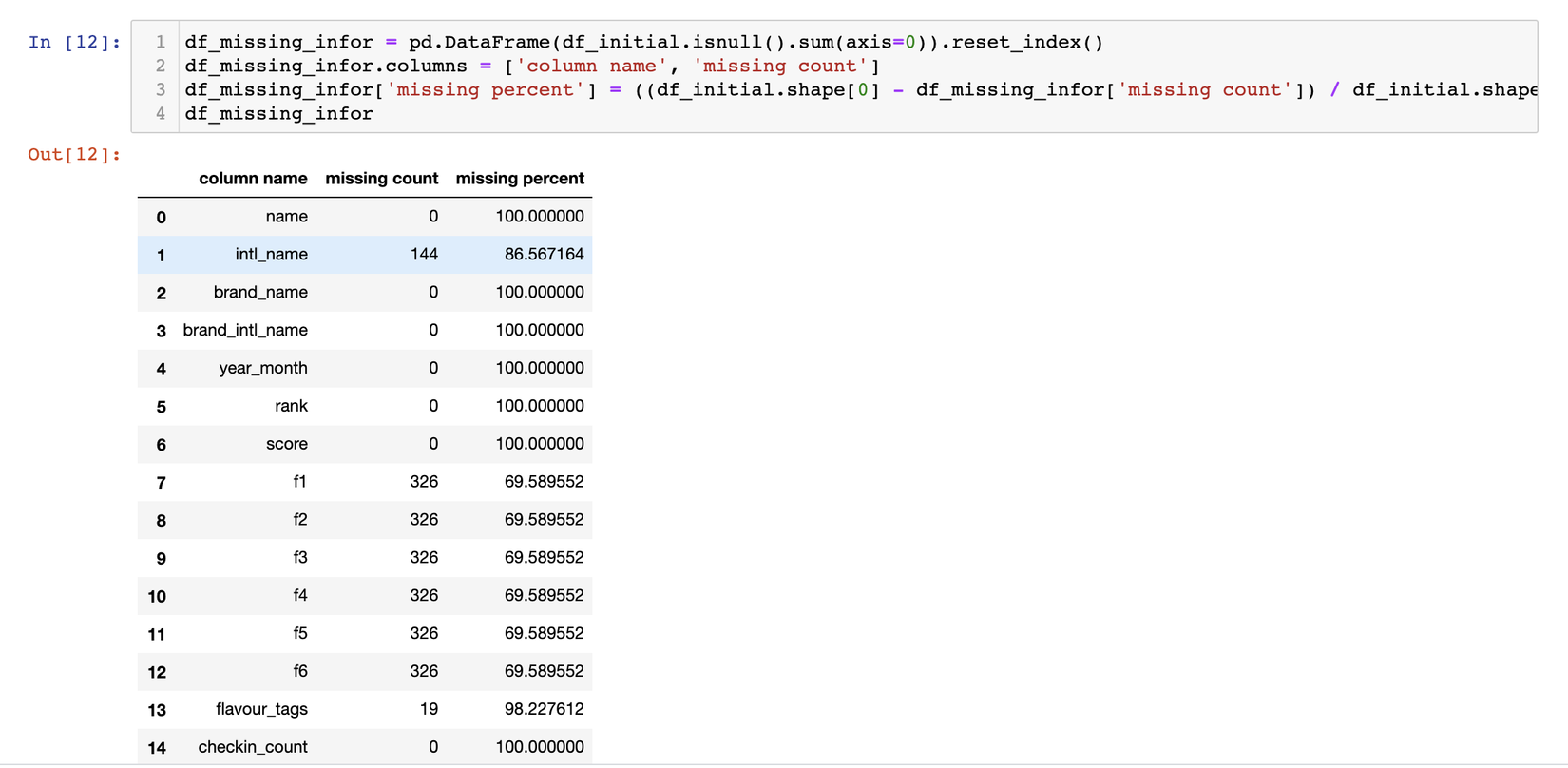
Chúng ta có khoảng hơn 1k bản ghi, nhưng f1-f6 và flavour_tags lại đang bị null đến hơn 30%, cách giải quyết sẽ là như thế nào, nếu bỏ qua tất cả những bản ghi này thì thật sự sẽ rất lãng phí. Qua quá trình quan sát, tớ nhận thấy những field nào có flavour_tags có phần giống nhau sẽ có xu hướng f1-f6 tương tự nhau, vì vậy chắc chắn chúng có mối quan hệ gì rồi. Chúng ta sẽ nói đến việc xử lý với chỗ dữ liệu null này như thế nào ở phần tiếp theo nhé.
3.3 Data Cleaning
Trước khi apply thuật toán vào, việc cần làm đó là phải đi clean lại đống data này đã. Có khá nhiều việc cần làm đối với một đống dữ liệu text, từ việc tokenization, stemming, find synonyms, xử lý duplicate, remove stopwords, filling missing data... Qua quá trình tìm hiểu, tớ tìm được một số tools khá tốt support cho việc xử lý tiếng Nhật, có thể kể đến như Mecab, Ginza, Janome, JapaneseTokenizer hay PorterStemmer của NLTK, và Scattertext để plot ra mức độ frequency của các từ.
Vì nội dung bài viết khá dài nên tớ sẽ bỏ qua 2 bước là remove stopwords và xử lý duplicate nha. Với bước remove stopwords thì trên kaggle và github cũng đã public source nên chúng ta có thể down về rồi thực hiện vòng lặp loại bỏ đi thui, còn bước xử lý duplicate thì tớ sẽ chọn cách remove đi những sản phầm trùng tên vì theo tớ nghĩ tên brand có thể trùng nhưng tên sản phầm thì phải khác, cái này thì tuỳ suy nghĩ của từng cá nhân nha.
Tiếp đến, phần việc tokenization là khá quan trọng vì nó là bước đầu tiên ảnh hưởng khá lớn đến các bước sau, nhưng tớ lại cũng không có khả năng verify vì k biết tiếng nhật, may mắn thay các thẻ tags này đã được extract sẵn rồi nên chúng ta cũng k cần làm gì nữa , trước khi đến các bước tiếp theo tớ sẽ viết 1 hàm để lấy tất cả các thẻ tags, và đếm số lượng xuất hiện của từng thẻ tags này trong toàn bộ dataset. Cùng xem ảnh bên dưới nhé:
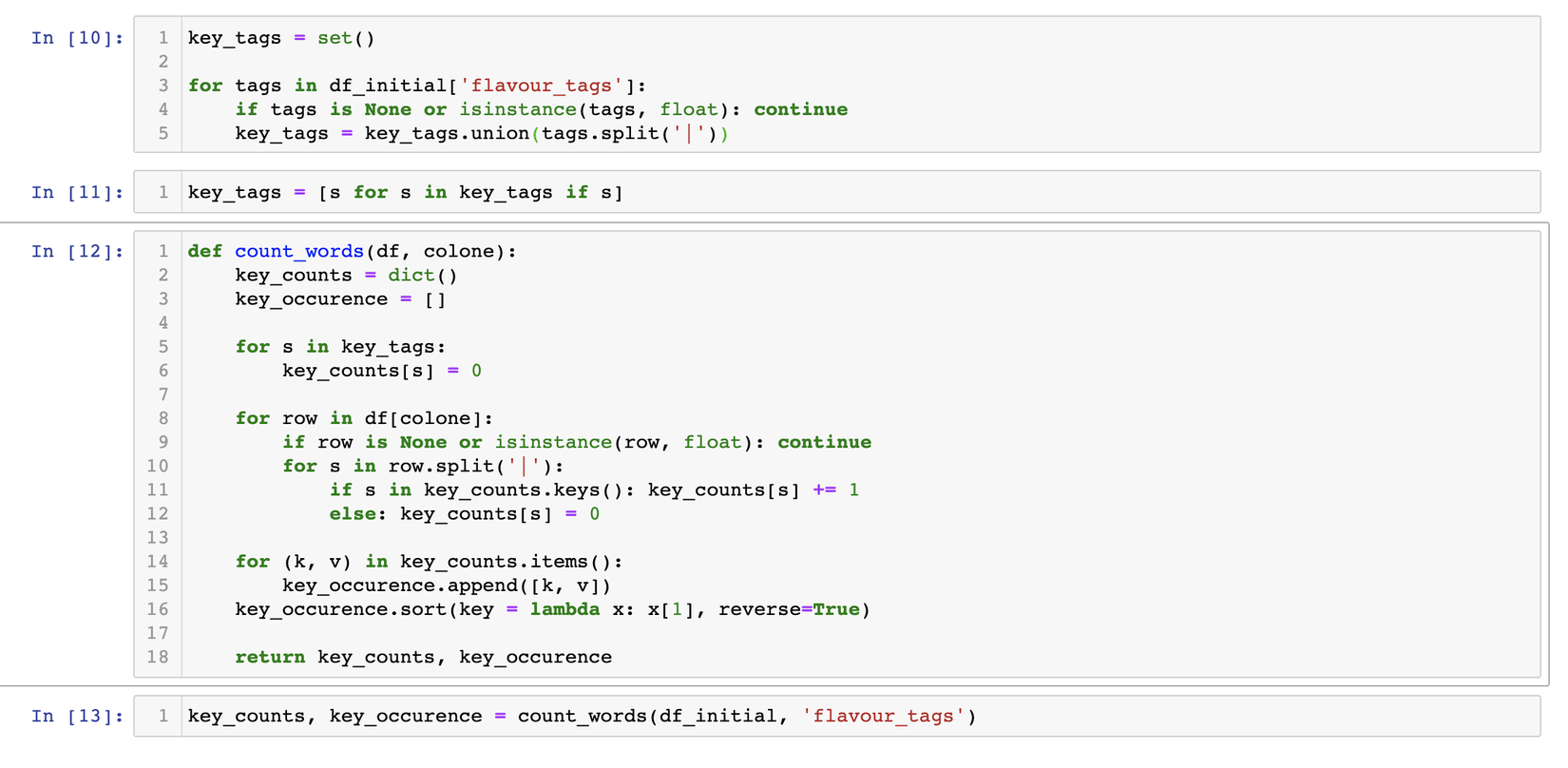
Từ đây tớ sẽ thực hiện việc stemming (stemming là công việc đưa 1 từ ở các trạng thái khác nhau về trạng thái ban đầu, ví dụ như: caresses => caress, died => die ...), cùng xem phương trình sau:
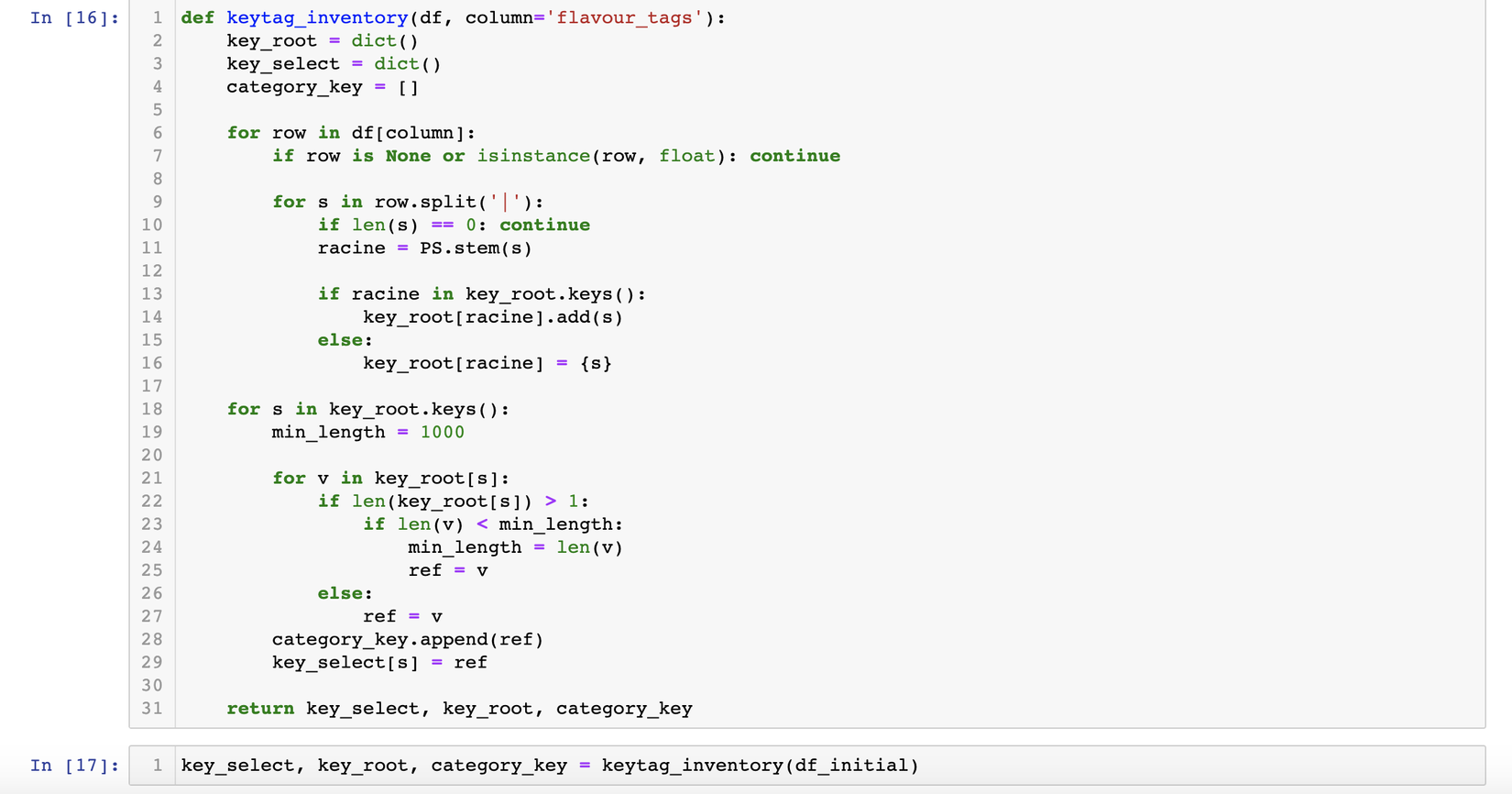
Giải thích một chút, trước khi thực hiện việc thay thế, t tạo ra 1 dict các từ được stemming về dạng chuẩn, các từ này sẽ đóng vai trò là keys trong 1 dict và có các values là danh sách các từ này trước khi được chuyển về dạng chuẩn là từ đó. Dễ hiểu đúng k nhỉ, có gì các bạn cứ comment bên dưới cho tớ nhé.
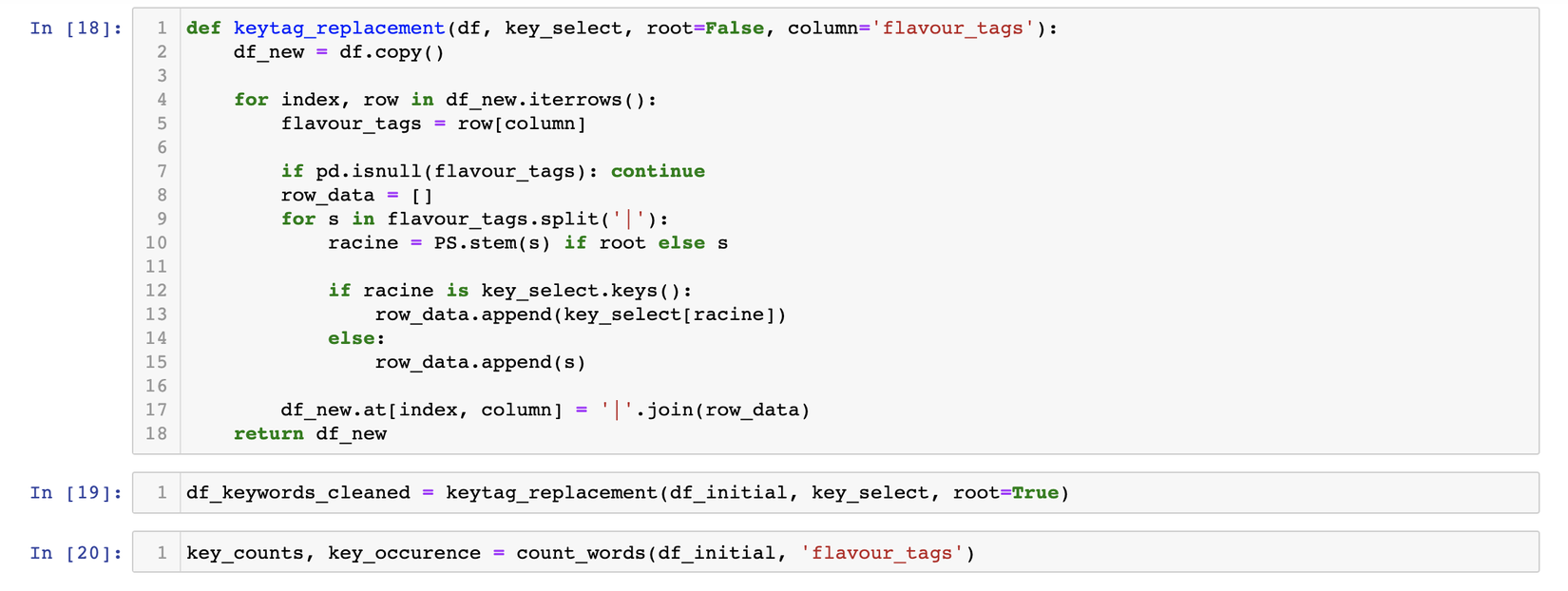
Phần tiếp theo chúng ta sẽ làm đó là tìm synonyms, ở phần này chúng ta cần tìm hiểu đến khái niệm lemmatization và pos, chúng ta sẽ cố gắng hiểu đơn giản, đối với pos là viết tắt của part of speech của từ, mỗi từ sẽ được categorized thành danh từ, tính từ, động từ, hay là phó từ, cái này tuỳ thuộc vào cấu trúc ngôn ngữ của mỗi quốc gia, còn lemmatization là phân tích hình thái từ, cụ thể hơn là trong từ điển các từ thì chắc chắn sẽ có những từ trong tuỳ bối cảnh sẽ có cùng nghĩa với nhau. Phần việc này đối với các đoạn văn bản mô tả sản phẩm là một bước rất quan trọng để tìm ra được những sản phẩm sát nghĩa nhất. Để hiểu hơn, cùng xem bảng dưới này nhé:
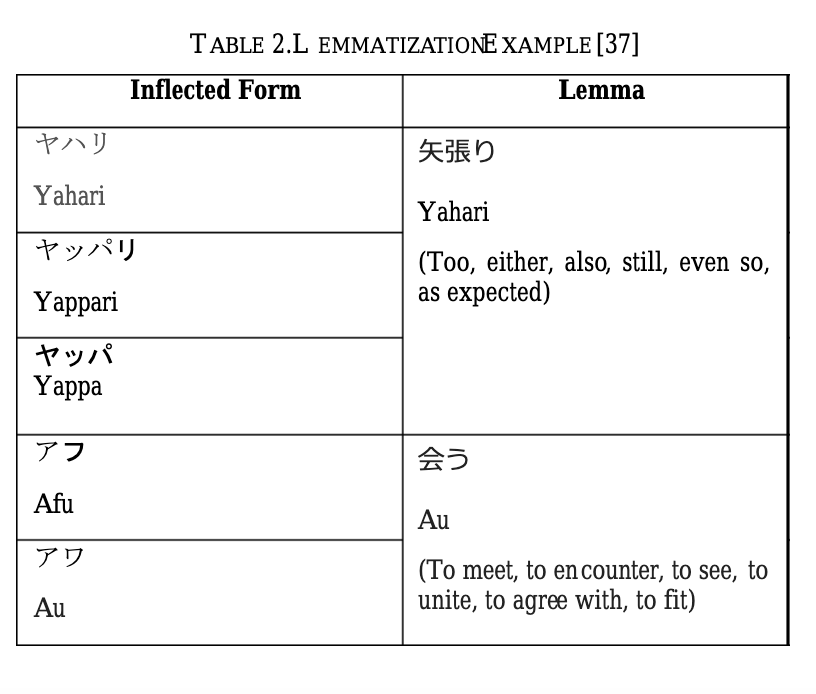
Phần code cho phần thay thế lemma này t xin phép bỏ qua nhé, ở phần này các bạn có thể dùng Ginza , mọi người đọc thêm ở đây nha.
Phần cuối cùng của phần data preprocessing này, tớ muốn đề cập là missing data filling. Như đã đề cập phần này từ trước, có đến hơn 30% là giá trị null của f1-f6 hoặc flavour_tags hoặc là cả 2, nếu không tận dụng thì sẽ rất phí. Qua quan sát tớ nhận ra những sản phẩm có phần giống nhau về tags sẽ có các dải giá trị f1-f6 khá tương tự nhau, nên t quyết định query ra những sản phẩm có flavour_tags nhưng bị null f1-f6, lặp từng sản phẩm này và lấy ra những sản phẩm có flavour_tags giống > 50% với flavour_tags của sản phẩm này, gom nhóm lại rồi lấy mean từng giá trị f1-f6. Hãy xem đoạn code sau nhé:
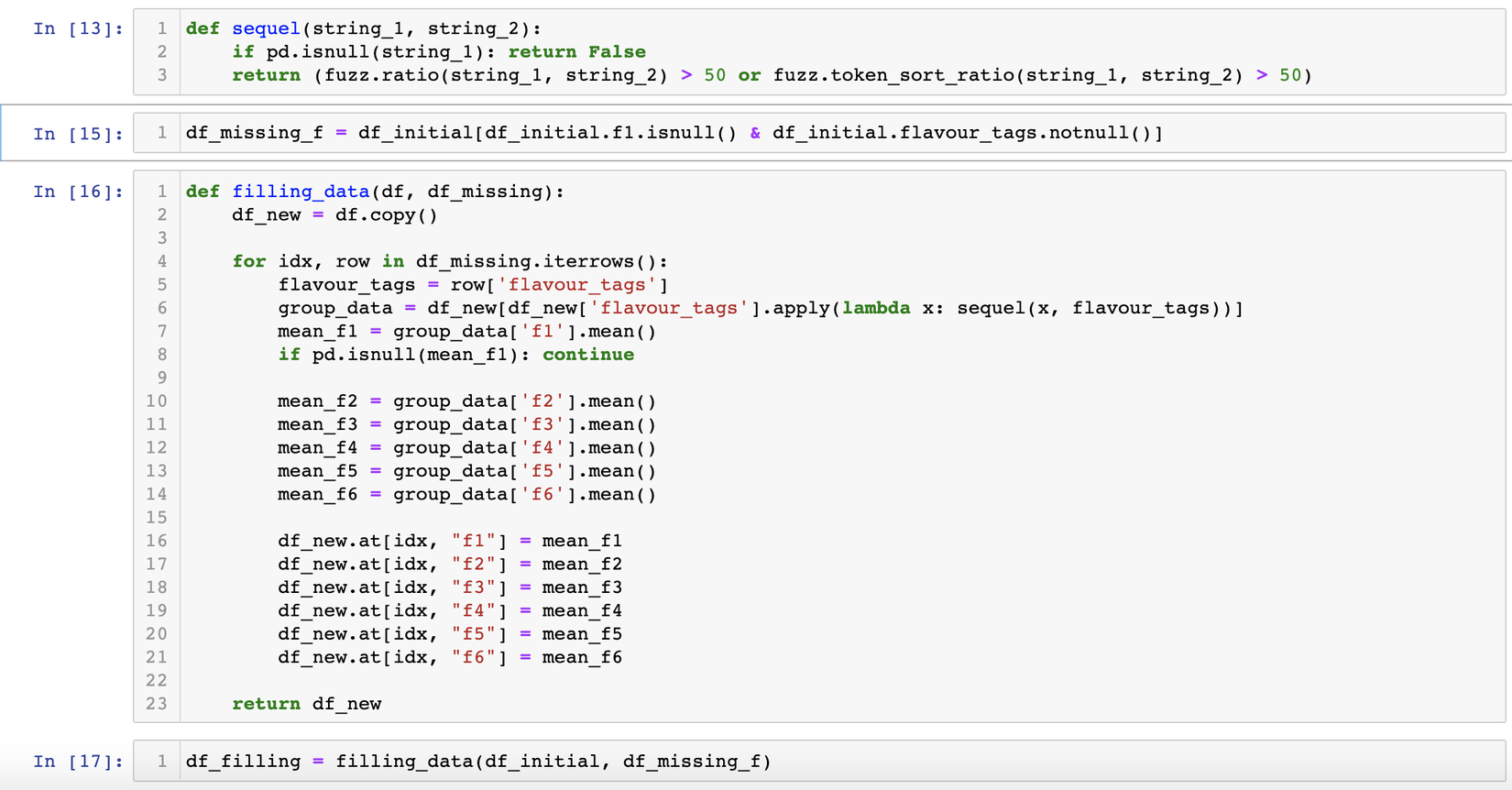
Có một cái hay ho ở đây là tớ dùng fuzz wuzzy để check độ tương đồng các chuỗi string. Đây là 1 package rất hay mọi ngừoi có thể tìm hiểu về nó nhé.
Tiếp đến có 2 case cần quan tâm là những bản ghi null cả flavour_tags và f1-f6, case này tớ bỏ luôn vì không có một mối liên hệ nào cả. Trường hợp f1-f6 có data nhưng flavour_tags null thì sao, chúng ta phải check thử mới biết được

Ở đây chỉ có 3 items, nên tớ cũng quyết định bỏ qua luôn. Bây giờ chúng ta sẽ đến phần thuật toán nhé.
IV. Implement Algorithm
Trước khi đi vào chi tiết, tớ muốn nói tóm tắt qua một chút về cách tớ sẽ thực hiện. Thuật toán mà t thực hiện sẽ được chia làm 2 bước:
Bước 1: Similarity based on tags: Tìm ra TOP N những sản phẩm giống nhau nhất về tags bằng việc build 1 matrix có dạng như sau:
| Liquor | Tag_1 | Tag_2 | Tag_3 | Tag_k | Tag_k+1 | Tag_m |
|---|---|---|---|---|---|---|
| liquor_1 | a11 | a12 | a1m | |||
| ... | ||||||
| liquor_j | aj1 | aj2 | ajk | ajm | ||
| ... | ||||||
| liquor_n | an1 | an2 | anm |
Ở matrix này, hệ số ajk sẽ có giá trị 0 hoặc 1 phụ thuộc vào giá trị ở column k và content flavour_tags ở cột j. Ví dụ: nếu tag_k trong flavour_tags của liquor_j thì ajk = 1, ngược lại = 0. Khi xây dựng xong matrix ta tính khoảng cách giữa các vector theo công thức:
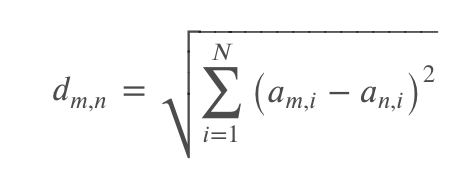
Sử dụng công thức này chúng ta có thể chọn ra Top N các liquor có độ similarity lớn nhất về tags. Cách làm này còn có 1 tên gọi khác là bag_of_word. Giờ cùng xem code nhé:

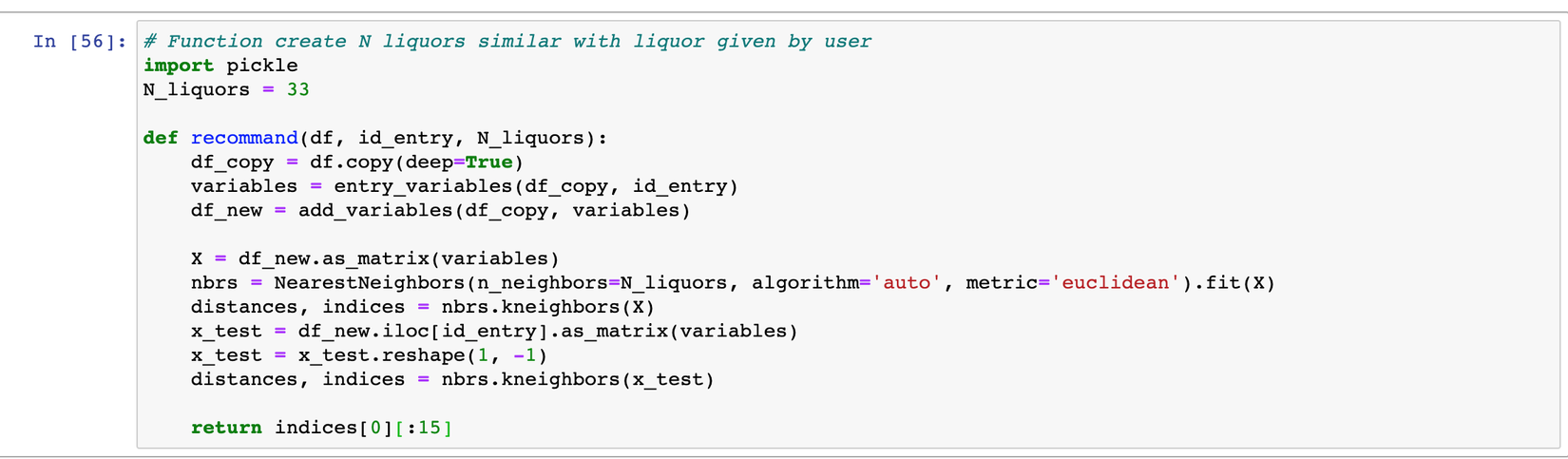
Ở đoạn code trên đây, t append thêm vào Dataframe input một matrix chỉ bao gồm 1 trong 2 giá trị là 0 hoặc 1, sau đó tớ đưa matrix này như là 1 tập data đưa vào KNN để train, mục đích dùng KNN là để tìm ra top N các vector giống nhất với vector đầu vào.
Bước 2: Similarity based on f1-f6 and other criteria: Lấy ra TOP 5 sản phầm cuối cùng dựa vào f1-f6 và 1 số chỉ số khác.
Sau khi có được Top N các phần tử giống nhau, nhiệm vụ tiếp theo của chúng ta cần làm là chọn ra 5 phần tử có chỉ số f1-f6 gần giống với liquor entry nhất. Nói đến đây cách đơn giản nhất mà mọi người thường nghĩ ngay đến là so sánh khoảng cách vector giữa các phần tử này, tuy nhiên đó không phải là 1 ý tưởng hay, tại vì sao. Có những kết quả được trả về bằng nhau giữa tổng bình phương hiệu các phần tử của 2 vecto nhưng vì nó có sự bù trừ giữa các chỉ số => có những phần tử bị sai lệch quá nhiều về 1 hoặc 2 chỉ số trong f1- f6 => cách hợp lý hơn cả là dùng 1 công thức tính weight để so sánh về mức độ tương đồng giữa các chỉ số f1 - f6.
Chúng ta có công thức sau:
score = 𝜙𝜎1,𝑐1 + 𝜙𝜎2,𝑐2 + (𝜙𝜎1,𝑐3 + 𝜙𝜎2,𝑐4 + ... + 𝜙𝜎n,𝑐n) x alpha
Trong đó 𝜙𝜎i,𝑐i là công thức guassian filter cho từng chỉ số f1-f6 và các thuộc tính khác, alpha là một hyper params
Công thức tính gaussian filter:
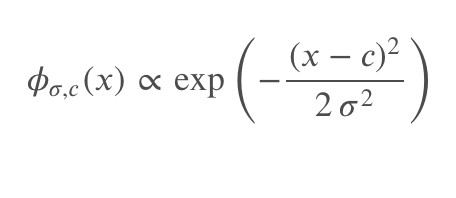
Với công thức này thì mọi người có thể tuỳ biến và không nhất thiết phải giống hệt như của mình, miễn sao các chỉ số phản ánh được độ quan trọng của từng thuộc tính và công thức phản ánh được mức độ liên kết giữa các thuộc tính với nhau. Bây giờ cùng đi chi tiết hơn vào code:
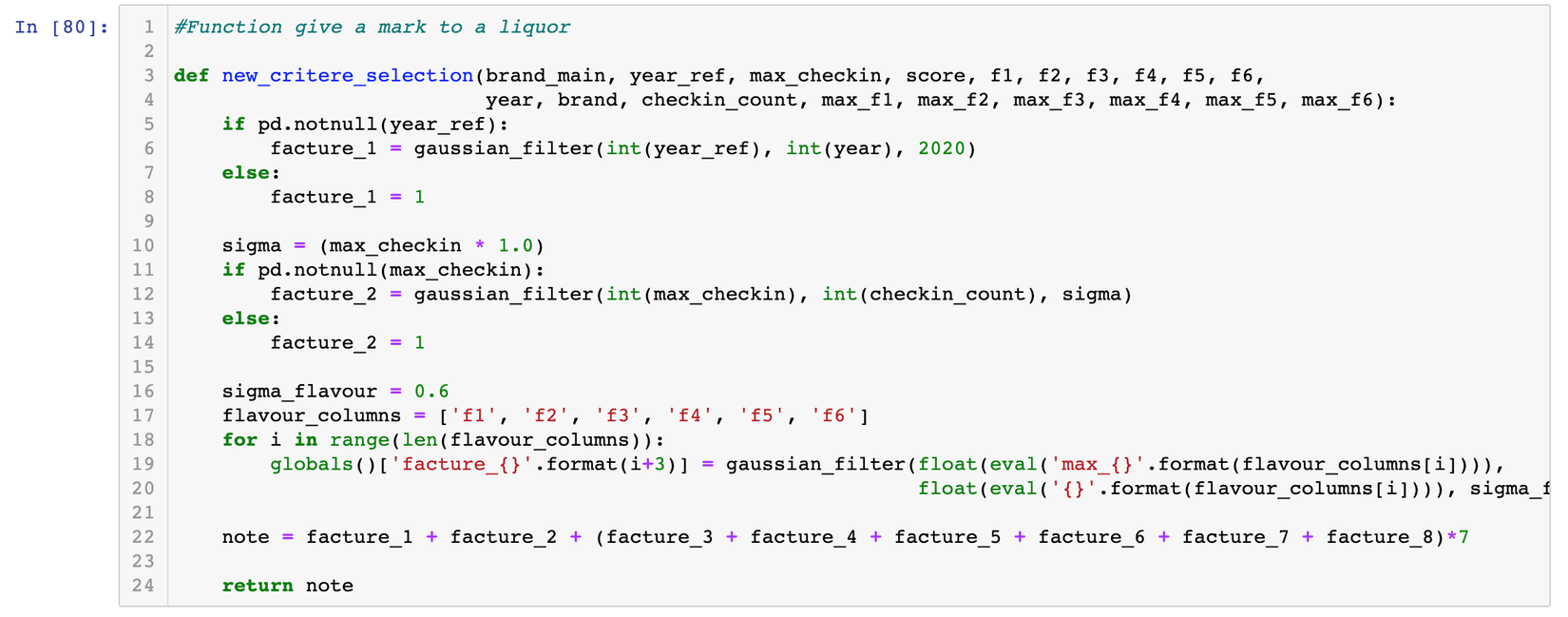
Function này có nhiệm vụ đánh mark cho 1 liquor
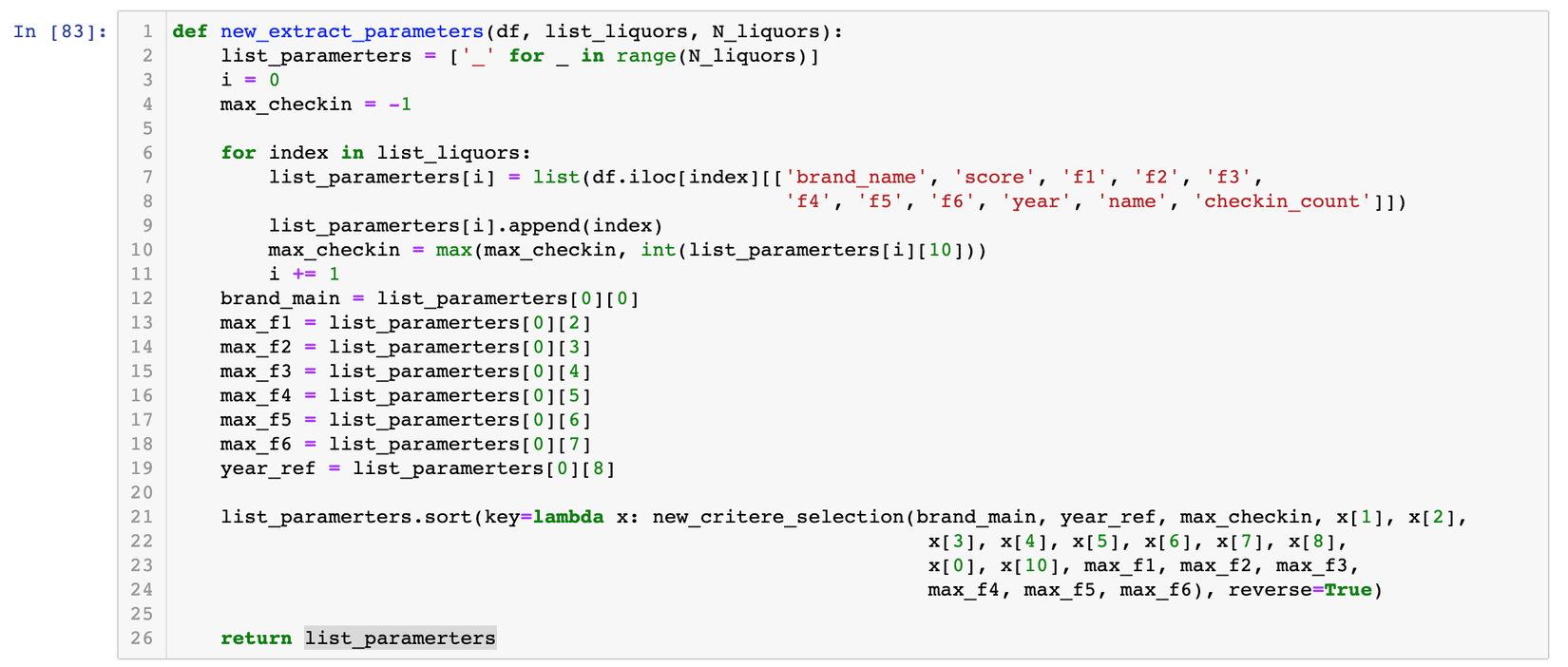
Function trả về danh sách đã được sort của các similarities

Function lấy ra top 5 sản phẩm giống nhất

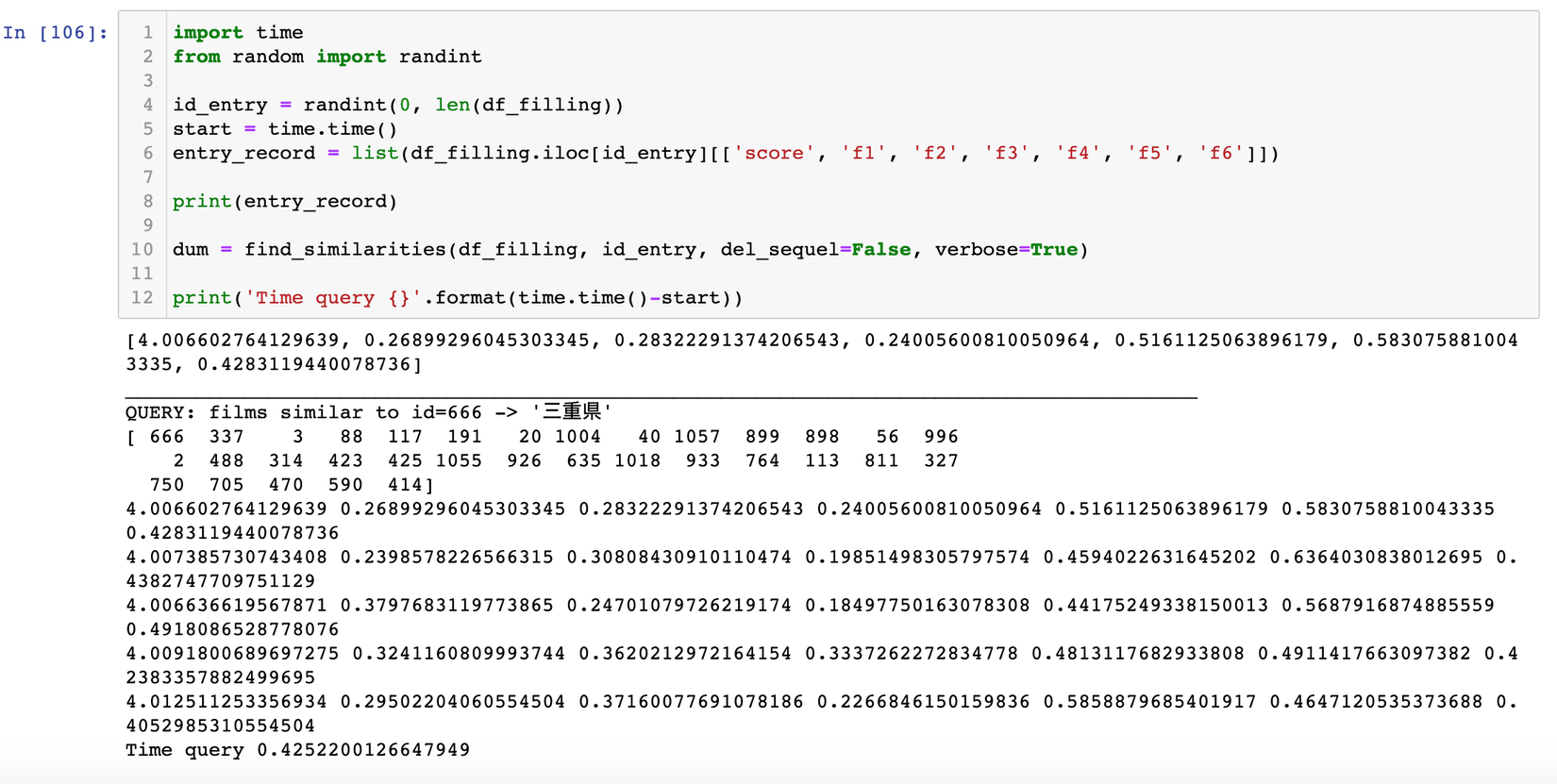
Đoạn code bên trên mô tả khá rõ các bước để tìm ra similarities của entry truyền vào sau khi có được TOP N similarities từ bước 1, ở đây ngoài các chỉ số f1-f6 tớ có dùng thêm các thuộc tính như là số lượng checkin, năm sản xuất...Nếu có thắc mắc gì các bạn cứ comment cho mình bên dưới hoặc mail cho mình nguyen.van.dat@sun-asterisk.com nhé.
Bây giờ chúng ta cần visualize kết quả một chút:
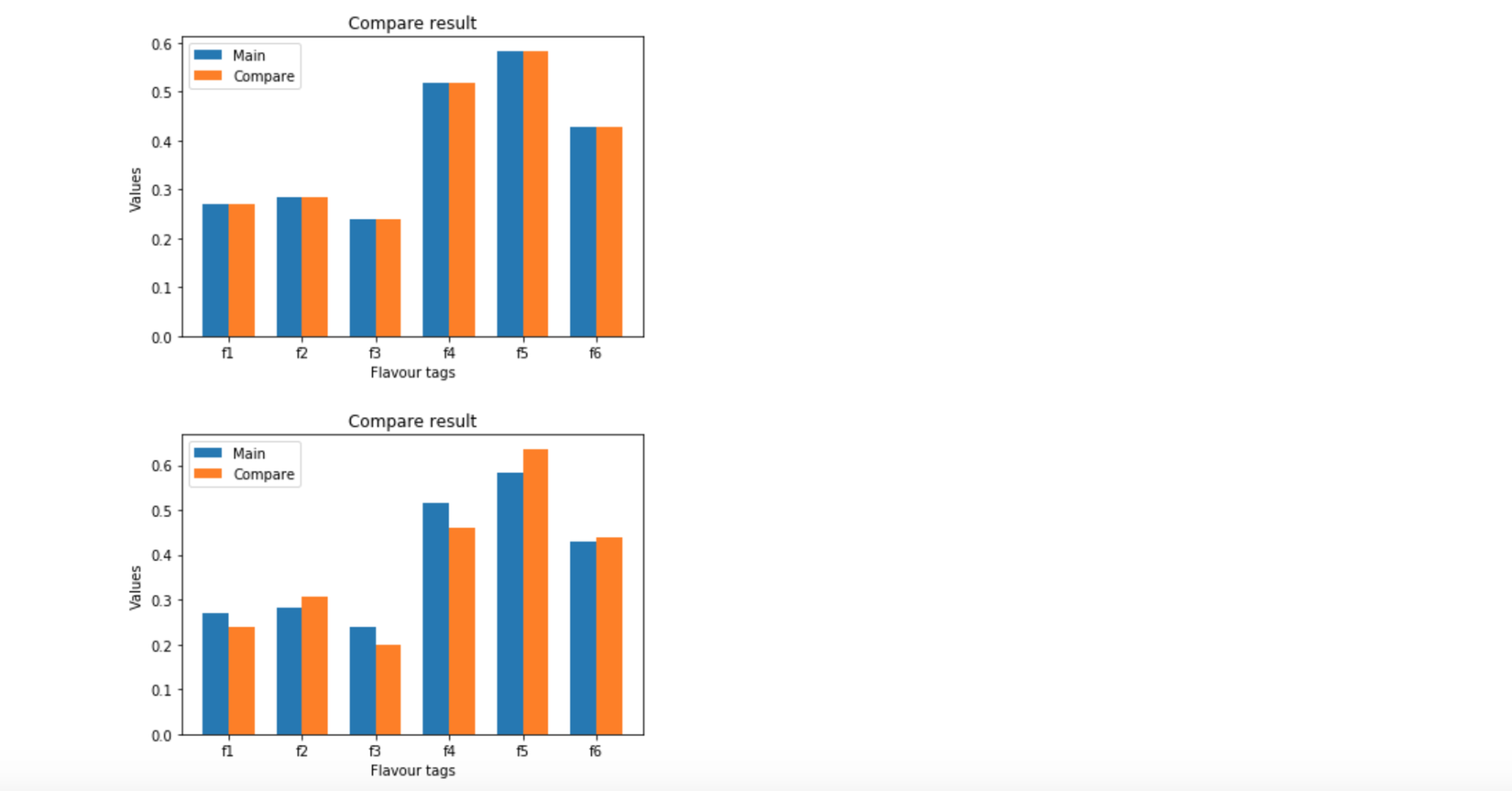
Có thể thấy kết quả khá ổn, tuy nhiên tớ chưa thực sự hài lòng về kết quả này và tớ muốn nó tốt hơn nữa, thì cách làm thế nào để tốt hơn, tớ sẽ nói ở phần tiếp theo đây.
V. Improvement and Future work
Thuật toán bên trên để thu được kết quả tốt hơn, chúng ta cần thử và thay đổi nhiều các thuộc tính hơn nữa + tìm ra các hyperparams để có được kết quả tối ưu nhất. Tuy nhiên nhược điểm tớ thấy còn ở đây là thời gian tính toán chưa thực sự nhanh, và có sự phụ thuộc giữa các bước nên kết quả ở bước sau ảnh hưởng rất nhiều từ bước trước. Nếu dữ liệu tags từ người dùng là sai thì kết quả phía sau cũng sẽ không thể đúng được.
Chúng ta có thể thử một cách khác là tìm similarities dựa trên 1 công thức có trọng số cho tags và f1-f6 và các chỉ số khác, trọng số nào quan trọng hơn sẽ được đánh cao hơn và ngược lại. Hiện tại tớ đã thử với cách này và thu được kết quả khá hài lòng, tuy nhiên tớ cần cải thiện thêm nên nếu có time tớ sẽ chia sẻ với mọi người sau.
VI. Model Management and Deploy to Production
Có lẽ phần này mức độ quan trọng cũng không kém gì bước xây dựng thuật toán nên mình sẽ dành 1 bài để nói về việc quản lý model và làm sao để deploy lên production nhé. Có thuật toán mà không có server và cách quản lý server deployment sao cho hiệu quả thì khi đến với người dùng hệ thống cũng không thể chạy ổn định được. Cảm ơn mọi người đã đọc đến đây, có vấn đề gì thì cứ comment bên dưới cho tớ biết nhé.
VII. References
https://sakenowa.com/flavor-search
https://machinelearningcoban.com/2017/05/17/contentbasedrecommendersys/
https://scikit-learn.org/stable/modules/neighbors.html
https://github.com/megagonlabs/ginza
http://nlp.ist.i.kyoto-u.ac.jp/EN/index.php?NLPresources
https://www.jaist.ac.jp/project/NLP_Portal/doc/LR/lr-cat-e.html
https://pypi.org/project/mecab-python3/
All rights reserved
