


![]() Bài viết được ghim
Bài viết được ghim

Độ hot của Langchain
Langchain là một framework vô cùng hot hit trong thời gian gần đây. Nó được sinh ra để tận dụng sức mạnh của các mô hình ngôn ngữ lớn LLM như ChatGPT, LLaMA... để tạo ra các ứng dụng trong thực tế. Dù mới được phát triển cách đây khoảng 6 tháng (10/2022) và vẫn được cập nhật liên tục hàng ngày nhưng trên Github Langchain đã nhận được những tương tác khủng với lượng star lê...

Tất cả bài viết

Lời mở đầu: Vượt qua giới hạn của PTQ
Trong đợt "xuất quân" trước, chúng ta đã cùng nhau giải mã cấu trúc đồ thị tính toán của YOLO và các bài toán lượng tử hóa căn bản. Nếu bạn vô tình lướt qua hoặc muốn ôn lại nội dung cốt lõi, hãy đọc ngay tại đây nhé:
🔗 Đọc lại bài viết trước: PHẦN 1: Tối ưu hóa "thần tốc" YOLO – Nghệ thuật ép cân từ FP32 xuống INT8 và giải mã cấu trúc đồ thị tính toán. ...

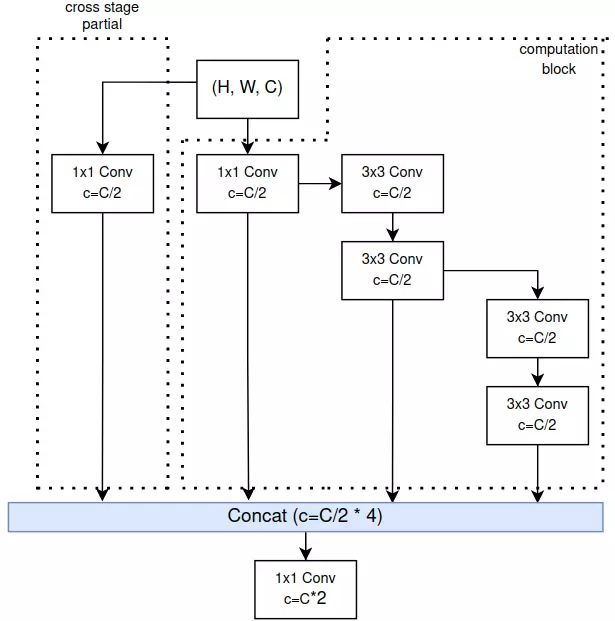
Lời mở đầu: Trận chiến sống còn trên thiết bị Edge
Hãy tưởng tượng bạn vừa huấn luyện xong một mô hình YOLOv8 hoặc YOLO11 "vực sâu không đáy" với độ chính xác (mAP) cao ngất ngưởng. Bạn tự hào mang nó đi deploy lên các thiết bị phần cứng giới hạn (Edge Devices) như NVIDIA Jetson, camera thông minh, hay thiết bị nhúng. Nhưng... Bùm! FPS tụt dốc không phanh, thiết bị nóng rực, và độ trễ (latency...

Lời mở đầu
- Tiếp nối phần 1, chúng ta sẽ cùng trao đổi tiếp tại phần 2 này nhé
- 💡 LightRAG — Dual-Level Graph Retrieval
Reference: Guo et al. (HKUST), "LightRAG: Simple and Fast Retrieval-Augmented Generation", arXiv:2410.05779, Oct 2024 GitHub: HKUDS/LightRAG (22k+ stars)
Ý tưởng cốt lõi
Vấn đề của RAG truyền thống: Vector search tìm được các đoạn text "ngữ nghĩa gần" nhưng không hiểu m...

Mở đầu
- RAG là một công nghệ mình đã đi cùng nó khá lâu, từ RAG truyền thống, GraphRAG rồi AgenticRAG. Các dự án về chatbot cũng không phải là ít nên thời điểm này từ góc độ mình nó vẫn là một công nghệ tiềm năng, chẳng qua là mình cải tiến nó đủ sâu đến đâu, mang nó đi được tới đâu trong hệ thống của khách hàng.
- Nhân dịp May Fest + sắp tới phát triển hơn về RAG + đã lui về ở ẩn khá lâu, mìn...

- Lời mở đầu
Xin chào mọi người, lại là tôi đây. Trong bài viết này mình sẽ giới thiệu về XTTS của Coqui AI, một mô hình ứng dụng trong việc clone giọng nói của người khác, đầu vào là file audio mình muốn clone và text mà mình muốn nói bằng giọng đó, kết quả trả ra sẽ là đoạn âm thanh mong muốn.
Ok thì câu hỏi đặt ra là tại sao lại là voice clone, thì đợt này mình đang làm đồ án tốt nghiệ...

- Giới Thiệu
Xin chào mọi người, lại là tôi đây. Trong bài viết này mình xin giới thiệu về Mem0, một phương pháp quản lý Long Term Memory trong hệ thống AI Agents. Bài này mình chủ yếu đọc từ paper và trình bày cấu trúc theo paper: Mem0
Mọi người có thể đọc paper gốc để nắm được chi tiết.
Mem0 sẽ tập trung vào vấn đề chính là phần Long Term Memory trong hệ thống AI Agents. Thì trước tiên...

1. Spec Driven Development (SDD) là gì? Mục tiêu và lợi ích trong thực tế
Spec Driven Development (Phát triển hướng Đặc tả) là một phương pháp phát triển phần mềm đặt đặc tả (specification) lên hàng đầu. Thay vì viết mã ngay, nhóm phát triển đầu tiên soạn thảo một tài liệu đặc tả chi tiết mô tả cái gì cần xây dựng và tại sao, rồi mới quyết định như thế nào để thực hiện. Đặc tả này đóng vai ...

Lời mở đầu Chắc hẳn bạn đã từng ao ước có thể "thổi hồn" vào những bức ảnh tĩnh, biến chúng trở nên sống động và biết nói? Hay bạn đang tìm kiếm một công cụ đột phá để tạo ra những video độc đáo, thu hút cho các dự án của mình mà không cần đến kỹ năng quay dựng phức tạp? Nếu câu trả lời là có, thì bạn đã tìm đến đúng nơi rồi đấy
Trong thế giới kỹ thuật số không ngừng phát triển, trí tuệ nhân t...

Lời mở đầu Xin chào mọi người, lại là tôi đây. Trong thế giới AI ngày nay, một trong những thách thức lớn nhất không chỉ là xây dựng những mô hình mạnh mẽ, mà còn là làm thế nào để mô hình có thể giao tiếp, hiểu và phối hợp hiệu quả với các công cụ, dữ liệu, hay dịch vụ bên ngoài. Đây chính là lý do Model Context Protocol (MCP) ra đời.
Trong bài viết này, chúng ta sẽ cùng nhau đi sâu vào khám ...

Sơ đồ hoạt động của hệ thống: Dưới đây là sơ đồ hoạt động của hệ thống digital human:
Nhìn vào kiến trúc tổng thể, ta thấy rằng để hiển thị Digital Humans một cách sống động, chúng ta cần đồng bộ hóa giữa hình ảnh video và âm thanh, và đẩy cả hai vào một luồng stream duy nhất. Nhưng đó mới chỉ là một nửa câu chuyện. Trải nghiệm sẽ chẳng thể trọn vẹn nếu người dùng không thể tương tác trực tiếp...

Mở đầu. Hiện tại đang là 31/5🫠, mình về quê, chưa biết làm gì cả, thôi thì viết thêm một bài nữa kết thúc tháng 5 nào 😉.
Thì 3 bài trước đó mình đã viết loanh quanh về khả năng của LLM. Vậy thì chính xác model LLM đã làm gì, điều gì khiến nó trở lên lên thông minh như vậy ? Tại sao nó làm được nhưng điều tưởng chừng chỉ có con người mới làm được ? Liệu LLM đã thật sự suy luận hay AGI đang đến ...


Introduction Trong quá trình triển khai mô hình machine learning/deep learning lên sản phẩm thực tế, những thách thức lớn không chỉ nằm ở việc huấn luyện mô hình, mà còn nằm ở khâu triển khai (serving) sao cho nhanh chóng, ổn định và dễ bảo trì. Trước kia, rất nhiều người bắt đầu bằng cách tự viết Flask hoặc FastAPI để dựng API cho mô hình, kết hợp với Docker nhằm mục đích đóng gói. Nhưng khi s...

Mở đầu. Ở phần 1 mình đã nói khá nhiều về các khái niệm của các dạng LLm, cách hoạt động và hình thành, đồng thời nói về các cách tạo nên reasoning của LLMs và phần 2 thì mình có nói đến một paper nói rằng :
- RLVR chưa phải là một cách đột phá trong việc khiến base model tìm kiếm ra được những reasoning path vượt ra khỏi ngưỡng kiến thức của mô hình base. và việc tạo ra dataset gồm nhiều reas...

Overview Trong các bài viết trước đây, mình đã lần lượt giới thiệu đến các bạn hai công cụ cho quá trình tăng tốc xử lý dữ liệu và triển khai mô hình Deep Learning là NVIDIA DALI và Triton Inference Server. Mình xin phép nhắc lại thông tin cơ bản một chút.
NVIDIA DALI Với NVIDIA DALI (Data Loading Library), mình đã trình bày các khái niệm nền tảng về thư viện này với mục đích tối ưu hóa khâu t...

Overview Trong bài viết lần trước , mình đã đề cập đến những thông tin cơ bản nhất của NVIDIA DALI, bao gồm khái niệm tổng quan về thư viện này, mục đích sử dụng cũng như những ưu điểm nổi bật mà nó mang lại trong quá trình xử lý dữ liệu hình ảnh và video cho các mô hình học sâu. Bên cạnh đó, mình cũng đã giới thiệu sơ lược về cách tích hợp DALI vào pipeline huấn luyện, giúp tăng tốc độ tiền xử...

Introduction Khi huấn luyện các mô hình deep learning, chúng ta thường dành nhiều sự quan tâm đến kiến trúc mô hình, lựa chọn loss function phù hợp, optimizer, tuning hyperparameters,... Nhưng có một thứ cũng khá quan trọng mà ta thường không quan tâm nhiều đó là hiệu suất xử lý dữ liệu đầu vào.
Multi-stage data preprocessing pipelines bao gồm loading, decoding hay augmentations là bước không ...


Giới thiệu
Nói chung LangGraph là một thư viện được xây dựng dựa trên LLM và LangChain, giúp ta đơn giản hóa việc xây dựng các Agent tự động hóa các tác vụ trong thế giới thực.
Vì sao cần LangGraph?
Ta thấy rằng LangChain cho phép chúng ta xây dựng code bằng LCEL( LangChain Expression Language ). Về cơ bản LCEL xây dựng các Chain, để dễ hiểu ta hãy xét một Chain cơ bản sau:
Có thể thấy, một...

Introduction Bối cảnh Human-in-the-loop (HITL) trong LangGraph thật ra khá là đơn giản, chính cái tên dường như đã giúp bạn hình dung phần nào về định nghĩa của nó. Khi chúng ta cần sự tích hợp của con người vào quá trình xử lý của mô hình AI, hay nói cách khác là ta đang cố gắng kiểm soát chúng, hiệu chỉnh và xác nhận kết quả. Điều này khá quan trọng trong các hệ thống sử dụng LangGraph, đặc b...
