


![]() Bài viết được ghim
Bài viết được ghim

Độ hot của Langchain
Langchain là một framework vô cùng hot hit trong thời gian gần đây. Nó được sinh ra để tận dụng sức mạnh của các mô hình ngôn ngữ lớn LLM như ChatGPT, LLaMA... để tạo ra các ứng dụng trong thực tế. Dù mới được phát triển cách đây khoảng 6 tháng (10/2022) và vẫn được cập nhật liên tục hàng ngày nhưng trên Github Langchain đã nhận được những tương tác khủng với lượng star lê...

Tất cả bài viết
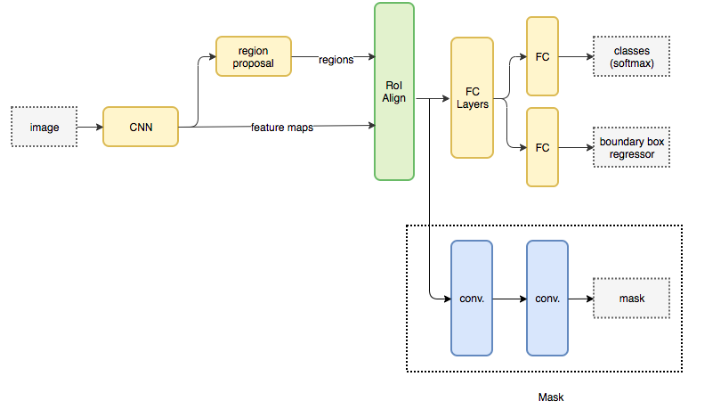
I.Overview
- Mask RCNN là một state-of-the-art cho bài toán về segmentation và object detection
- Chúng ta sẽ cùng tìm hiểu cách mà MaskRCNN hoạt động như thế nào
- Cùng nhau thực hiện các bước triển khai MaskRCNN cho bài toán segmatation II.Introduction Kết thúc chuỗi bài về RASA chatbot với các bài viết về Tập tành làm Rasa chatbot hay viết hàm custom action trong xử lý hội thoại chuỗi của ch...
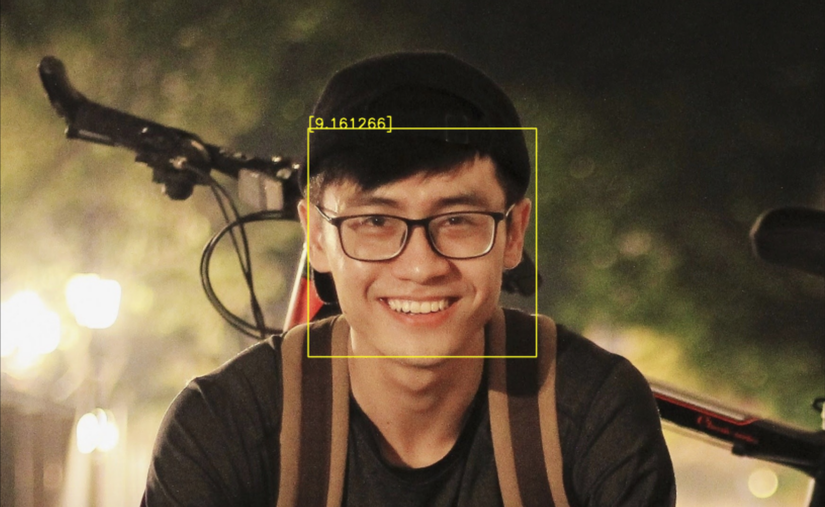
Làm thế nào để bạn biết mình đẹp trai, xinh gái ra sao nếu không dựa vào người khác đánh giá???
Và câu trả lời là AI sẽ làm điều đó cho bạn, hôm nay mình sẽ giới thiệu đến các bạn cách xây dựng một bài toán rất hay và thú vị mang tên “Beaty Evaluate”. Sử dụng deep learning train với bộ dữ liệu SCUT-FBP5500 để ra được model “tối thượng” để dự đoán được độ đẹp zai xinh gái của bạn như thế nào, c...

Lời giới thiệu Xin chào các bạn. Đây là series mà mình đã ấp ủ rất lâu nhưng vì cứ mải việc này việc kia mà chưa có thời gian thực hiện. Chúng ta đã biết rằng có rất nhiều người muốn tìm hiểu về lĩnh vực AI nhưng việc phải đọc các paper và tìm hiểu các lý thuyết của nó thực sự không phải là điều đơn giản. Có rất nhiều lý do cho vấn đề này nhưng mình thấy thường là có một số lý do khá cơ bản như...

TL;DR Feature Locality và Translational Invariance.
Mở bài Tại sao mình lại viết bài này? Lúc đó, mình đang đọc bài này của một bạn team mình, và bỗng nhiên mình đặt ra câu hỏi:
Tại sao mạng/lớp tích chập lại hoạt động hiệu quả?
Nhiều lúc mình cũng nghĩ về chuyện này, rồi tự nhủ mình hiểu rồi, để rồi sau này lại tự hỏi bản thân mình đã thực sự hiểu chưa. Cụ thể, câu hỏi to nhất mà mình có là...
I. Introduction
Xin chào mọi người, cũng khá lâu rồi mình không chia sẻ được gì cho anh em viblo, phần vì mình lười viết, phần cũng vì cảm thấy kiến thức của bản thân còn hạn hẹp quá  . Nay cũng là ngày gần cuối mình ở Nhật, thời gian bắt đầu dư giả hơn nên quyết định viết bài này chia sẻ tới ae những gì mình học được trong khoảng thời gian ở đây, cũng là một cách để mình refresh lại sau mộ...
. Nay cũng là ngày gần cuối mình ở Nhật, thời gian bắt đầu dư giả hơn nên quyết định viết bài này chia sẻ tới ae những gì mình học được trong khoảng thời gian ở đây, cũng là một cách để mình refresh lại sau mộ...
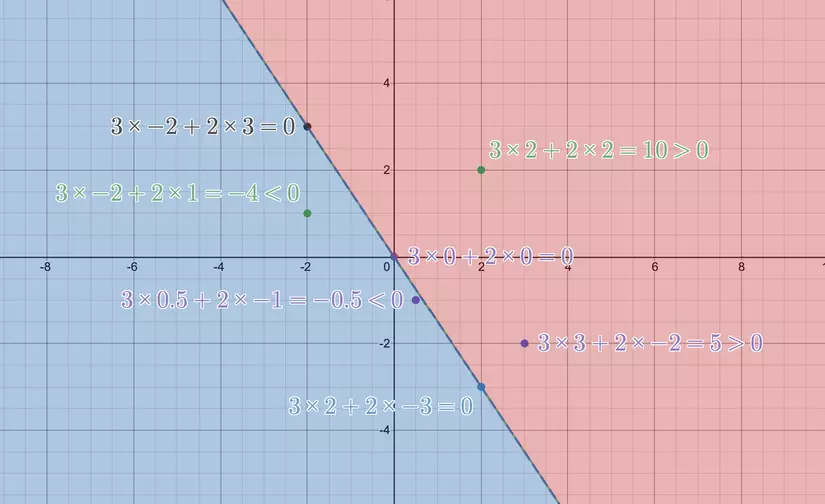
Câu hỏi được đặt ra Sau một thời gian đi hóng phỏng vấn của các tay to trong team thì một câu hỏi hay được đặt ra để phân biệt giữa người hiểu lơ mơ và người hiểu không lơ mơ lắm chính là câu hỏi trên đề bài:
Phân biệt sự khác nhau giữa hồi quy tuyến tính và phân lớp tuyến tính?
Vậy thì bài viết này sẽ giải thích cụ thể sự khác nhau đó nhé, kèm tất cả những gì liên quan đến cả 2 mô hình trên....
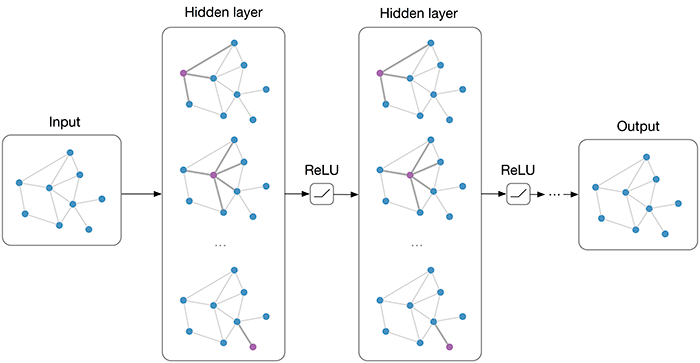
Visualizing neural network(Trực quan hoá mạng lưới thần kinh) là gì? Một khái niệm quá quen thuộc với deep learning đó chính là DNNs (deep neural network) , trong computer vision nó được áp dụng cực kỳ nhiều với các tác vụ như: phân loại, phát hiện, segmentation. Yep chúng ta biết DNNs đã làm điều đó, nhưng bằng cách nào, hay nói rõ hơn bên trong các layers hay nó đã xử lý để đưa ra quyết định ...

Các phần nội dung chính được đề cập trong bài blog lần này
-
Giới thiệu về Kuzushiji Recognize
-
Hướng tiệp cận
-
Text detection - Image Segmentation
-
Quá trình hậu xử lý mô hình - Post processing
-
Text recognition - Image Classification
-
Demo với streamlit
-
Triển khai model với tensorflow serving
-
Đóng gói model với Docker / docker-compose
-
Kết quả thu được sau bài blog này
và
- L...
Xin chào tất cả các bạn, corona thật sự đang rất ảnh hưởng đến cuộc sống của mỗi chúng ta đặc biệt là việc phải làm remote ở nhà với một cái màn hình máy tính thì thật là không vui chút nào. Nhớ những ngày được đi làm còn có đồng nghiệp hỏi han nhưng nay thui thủi chỉ ta với chiếc máy thì biết làm sao bây giờ. Thôi thì làm một ứng dụng tự chơi oẳn tù tì với máy cho vui vậy. Ứng dụng ngày hôm na...
- Tổng quan về Rasa Trước tiên, để bắt đầu đi vào quy trình xây dựng một chatbot bằng Rasa, mình nghĩ các bạn sẽ cần biết Rasa là gì và Rasa có những ưu điểm vượt trội gì để được lựa chọn cho việc xây dựng chatbot.
Nếu các bạn là người bắt đầu muốn nghiên cứu về chatbot, hay chỉ đơn giản là nảy ra một ý tưởng xây dựng một chú "bot" thú vị có thể "chat", hoặc cập nhật tin tức, hoặc làm một tác...
Vậy là đã tròn 6 tháng mình không viết bất cứ bài chia sẻ nào trên Viblo cả, kể cũng buồn và hơi nhớ. Một phần lý do là mình lười (phần quan trọng nhất, chiếm khoảng 90% ), phần còn lại là bị cuốn bởi 2 nền tảng khác của Viblo là Viblo Code và Viblo CTF nên tự dưng sao đãng Viblo Sharing.
Nhưng thôi, mình đã quay lại rồi và để kỉ niệm con số 6 tháng khá đẹp này thì mình lại kiếm 1 cái gì đó để...

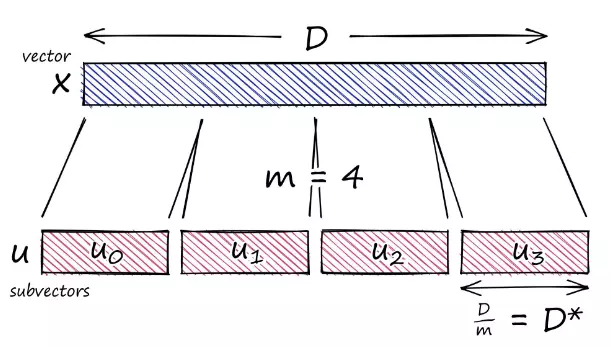
I. Introduction Faiss Facebook AI Similarity Search (Faiss) là một thư viện sử dụng similiarity search cùng với clustering các vector. Faiss được nghiên cứu và phát triển bởi đội ngũ Facebook AI Research; được viết trong C++ và đóng gói trên môi trường Python. Bộ thư viện bao gồm các thuật toán tìm kiếm vector đa chiều trong similarity search
Similarity search Hiện nay, phương pháp phổ biến nh...
Lời mở đầu
Với những ai từng làm chatbot cho Tiếng Việt chắc đều biết phần tiền xử lí thời gian là phần cực kỳ mệt và hiện giờ tôi đang làm phần này đây  . Vì khuôn khổ bài viết có hạn, tôi sẽ chỉ nêu ra một số vấn đề xảy ra trong khi xử lí ngày tháng Tiếng Việt và cách giải quyết vấn đề đó, nếu còn thiếu sót nhờ các bạn góp ý thêm.
. Vì khuôn khổ bài viết có hạn, tôi sẽ chỉ nêu ra một số vấn đề xảy ra trong khi xử lí ngày tháng Tiếng Việt và cách giải quyết vấn đề đó, nếu còn thiếu sót nhờ các bạn góp ý thêm.
Vấn đề bạn chắc chắn gặp phải Như các bạn đã biết, khi làm c...
Việc áp dụng Machine Learning vào kinh doanh đang trở nên rất phổ biến. Với các lĩnh vực như ngân hàng hay dịch vụ, bên cạnh đưa ra dự đoán hay phân loại vào các lớp, một mô hình có thể diễn giải được (interpretable) cũng rất quan trọng. Ví dụ, đối với một ngân hàng, ngoài việc dự đoán khả năng khách hàng A mở tài khoản tiết kiệm, ngân hàng này sẽ muốn mô hình đưa ra những yếu tố quan trọng nhấ...
Bài viết này trong series Chatbots are cool. Let's build a chatbot!
- Rasa Custom Actions Tiếp tục chuỗi bài về Rasa Chatbot hôm nay mình xin giới thiệu các bạn một phần không thể thiếu để xử lý những cuộc hội thoại phức tạp. Trước khi bước vào bài đọc mình nghĩ các bạn nên nắm chắc các định nghĩa cũng như cách tạo các intent, entities, slot...trong bài viết "Tập tành Rasa Chatbot " của mình :...
TL;DR: Code đây. https://github.com/ngoctnq-1957/rasa-chatwork-echo
Mở bài Nếu bạn là người đi làm chatbot như mình, chắc hẳn bạn đã dùng Rasa. Với các ưu điểm vượt trội như là hoàn toàn local không sợ mất thông tin, một dialog handler xịn cùng các connector (cho dù bắt entity hơi ngu), Rasa là sự lựa chọn số 1 của các dự án cần tính bảo mật/hay cần mọi thứ trong 1 gói. Đồng thời, nếu bạn làm ...
Xin chào các bạn, có lẽ một trong những tiêu điểm của những tháng đầu năm 2020 đó chính là dịch viêm phổi cấp do chủng mới của virus corona gây ra. Theo ước tính cho tới thời điểm hiện tại ngày 15/2/2020 đã có trên 60.000 lượt nhiễm bệnh và gần 2000 người chết trên khắp thế giới. Để có thể có thêm một kênh thông tin cập nhật real time tình hình dịch bệnh thì hôm nay mình xin phép được hướng dẫn...
Hello mn lại thêm một tháng nữa trôi qua =))), hôm nay mình sẽ chia sẻ về handle với Missing data trong data analysis. Như mọi người đã và đang làm việc với dữ liệu thực tế thì vấn đề missing data khá là phổ biến, vì vậy việc giải quyết vấn đề missing value là cần thiết để góp phần giúp cho bài toán của chúng ta được cải thiện một cách đáng kể hơn. Trong bài viết lần này mình sẽ trình bày một ...
Bài viết nằm trong series Chatbots are cool. Let's build a chatbot!
Tuần trước mình có tham gia vào một dự án của công ty, một trong những nhiệm vụ của mình đó làm ra một trợ lý chatbot, sau một thời gian tìm hiểu và được sự suppor nhiệt tình của anh Phạm Hữu Quang thì hôm nay mình xin chia sẻ một số kinh nghiệm của mình với RASA - một NLU framework hỗ trợ chúng tôi tạo ra chatbot với mục ti...
Lý Thuyết ANNOY là gì ? Các thuật toán Tree-based là một trong những thứ được dùng khá nhiều khi nhắc đến ANN(Mạng neural nhân tạo) . Chúng ta xây dựng các rừng cây từ dữ liệu bằng cách cấu trúc lại nó thành những tập con dữ liệu. Một trong những giải pháp nổi bật nhất là Annoy.
Annoy: Approximate Nearest Neighbors Oh Yeah là một thư viện C ++ với các ràng buộc Python để tìm kiếm các điểm tron...
