
Haar Cascade là gì? Luận về một kỹ thuật chuyên dùng để nhận biết các khuôn mặt trong ảnh.
Bài đăng này đã không được cập nhật trong 6 năm
Mở bài
Sau khi mình đọc bài này của bạn Sơn team mình về đánh giá điểm khuôn mặt, đến đoạn bắt xem vùng nào chứa khuôn mặt trên ảnh, thì mình chợt nhận ra là mình không biết gì về cái này cả  Sau khi search trên Viblo về Haar Cascade cũng thấy chục bài, tuy nhiên các bài cũng giải thích không được dễ hiểu lắm, nên mình viết thêm một bài nữa cho các bạn càng thêm khó hiểu : )
Sau khi search trên Viblo về Haar Cascade cũng thấy chục bài, tuy nhiên các bài cũng giải thích không được dễ hiểu lắm, nên mình viết thêm một bài nữa cho các bạn càng thêm khó hiểu : )
Bạn có thể thử chấm điểm khuôn mặt mình trên trang https://beauty.sun-asterisk.ai nhé!
Haar Cascade là gì?
Về cơ bản là sử dụng các đặc trưng loại Haar và sau đó sử dụng thật nhiều đặc trưng đó qua nhiều lượt (cascade) để tạo thành một cỗ máy nhận diện hoàn chỉnh. Vẫn khó hiểu phải không? Vậy chúng ta nhảy vào từng khái niệm một nhé.
Đặc trưng Haar
Nếu bạn đã làm việc với xử lý ảnh hoặc Convolutional Neural Networks rồi thì chắc bạn cũng không còn lạ gì với các bộ lọc trong xử lý ảnh nữa cả — nếu không, bạn có thể đọc phần này trong một bài của mình về CNN để hiểu thêm. Các ví dụ bộ lọc được liệt kê ở dưới, trong đó a) là các bộ lọc bắt các cạnh trong ảnh, và b) bắt các đường thẳng trong ảnh, tương tự như các bộ lọc đã được mình nhắc tới trong bài trên. Ngoài ra, còn có các bộ lọc Haar khác, như ví dụ c) về đặc trưng 4-hình vuông dưới đây,
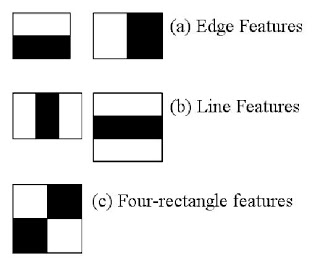
hoặc đặc trưng nằm gọn trong trung tâm một vùng như ví dụ 3. trong ảnh dưới đây:
Tuy nhiên, cách áp dụng các bộ lọc này khác một chút so với các cửa sổ bộ lọc bên CNN. Ở CNN, bộ lọc chiếm toàn bộ cửa sổ trượt, trong khi ở đặc trưng Haar, bộ lọc chỉ chiếm một phần trong cửa sổ trượt thôi. Điều đó được minh hoạ trên ảnh sau:

Trong hình trên, cửa sổ trượt được đặt ngay ngắn vừa gọn để nhìn được toàn bộ ảnh. Các bạn có thể nhận ra rằng bộ lọc đầu trong đó đang tìm một "cạnh" phân cách giữa mắt/lông mày với mũi, vì ở đoạn đọc có chênh lệch về màu đáng kể; và ở bộ lọc sau, mô hình đang tìm đường sống mũi, vì ở đó sẽ có màu sáng hơn so với 2 bên (vì nó cao hơn dễ bắt sáng). Và như đã nói trên, bộ lọc Haar chỉ nhìn cụ thể vào một vùng trong cửa sổ để tìm thôi: trong khuôn mặt thì mũi lúc nào cũng ở chính giữa chứ không ở các góc, nên không cần nhìn các góc để làm gì cả.
Để tăng tốc tính toán khi tính các bộ lọc trên, chúng ta thường sử dụng integral image. Mục này bạn có thể tham khảo thêm trong bài viết này của Hải Hà Chan để biết thêm chi tiết nhé.
Làm sao mà biết được bộ lọc Haar nào tốt? Nhìn cái nào cũng như nhau...
Đúng vậy, chúng ta có tầm 160k+ các bộ lọc như vậy cơ! Tuy nhiên, chúng ta có thể sử dụng Adaboost (adaptive boosting) để kết hợp các bộ lọc trên như sau:
Ảnh trên là minh hoạ của quá trình boosting: khi bạn có các classifier yếu khác nhau, kết hợp chúng để tạo thành một classifier mạnh. Việc kết hợp như các bạn thấy khá đơn giản, chỉ là các khối logic AND/OR phụ thuộc vào kết quả được đưa ra. Câu trả lời là một lớp perceptron đơn giản! Một tổ hợp tuyến tính đơn giản đã có thể tính được kết hợp các đầu ra quyết định trên, bạn có thể tìm hiểu thêm ở mục ngoài lề này trong bài về linear classifier mình đã viết.
Vậy đó là boosting rồi, còn adaptive ở đây là gì? Ở boosting thường thì các classifier yếu trên có tiếng nói ngang nhau, bình đẳng và dân chủ; nhưng sau khi qua Adaboost, nhưng classifier khôn hơn thì tiếng nói sẽ có trọng lượng cao hơn. Sau đây là một hình ảnh minh hoạ khác để giúp bạn dễ tưởng tượng hơn chút:

Kết quả là 2 bộ lọc ở mục trên là những bộ lọc tốt nhất theo như Adaboost.
Về thuật toán Adaboost, bạn có thể tham khảo thêm ở bài này của bạn Phạm Minh Phương.
Các đặc trưng trên bắt gì chả được đâu chỉ mỗi mặt?
Đúng như vậy, các bộ lọc Haar kể cả sau Adaboost như trên vẫn chỉ bắt được những đặc trưng rất cơ bản, và để nhận ra một khuôn mặt thì chúng ta cần tầm 6000 các đặc trưng như vậy! Vậy chúng ta cần có một cách để vote xem cửa sổ đó có chứa mặt không, mà vẫn phải xử lý đủ nhanh cho cả 6000 đặc trưng đó: câu trả lời là Cascade of Classifiers, được đề xuất bởi Paul Viola và Michael Jones vào năm 2001.
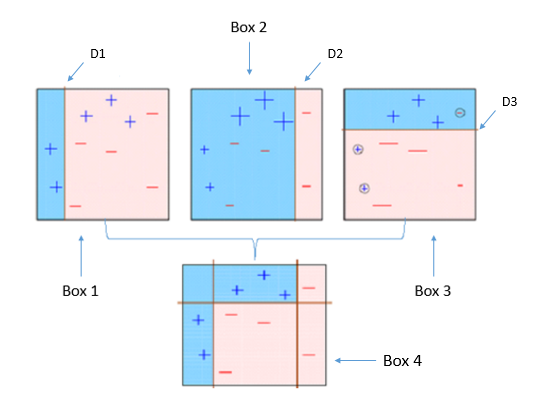
Việc cascade đó được thiết kế như sau: trong 6000+ đặc trưng đó, chia chúng ra thành rất nhiều bước. Trong đó, mỗi lần cửa sổ trượt qua một vùng bước ảnh, từng bước một sẽ được xử lý: nếu bước 1 nhận đó là mặt, chúng ta chuyển qua bước 2; và nếu không thì chúng ta bỏ qua vùng đó và trượt cửa sổ đi chỗ khác. Nếu một vùng pass toàn bộ các bước test mặt đó thì cửa sổ đó có chứa mặt người.

Các vùng không chứa mặt sẽ bị vứt vào hộp đỏ kia và không bao giờ được nhớ tới nữa, và các vùng có mặt sẽ được đưa vào hộp xanh để xử lý tiếp.
Chúng ta có thể chia kết quả ra làm 4 loại:
| Tên | Đáp án đúng | Đáp án của chúng ta |
|---|---|---|
| True positive | True | True |
| True negative | False | False |
| False positive | False | True |
| False negative | True | False |
Trong đó, nếu dự đoán đúng rồi thì không cần bàn cãi, nhưng nếu chúng ta dự đoán sai một bước sẽ có thể không qua các bước còn lại. Vì vậy, trong quá trình train, mô hình sẽ lựa chọn các classifier tốt nhất với độ tự tin hợp lý để ưu tiên việc false negative không được phép tồn tại — vì nếu chúng ta gặp false positive, các bước sau sẽ loại ví dụ đó cho chúng ta sau. Trong mô hình nhận mặt người, bước đầu tiên đúng có 2 bộ lọc trên, với tỉ lệ false negative rất gần 0, và tỉ lệ false positive là 40%.
Sau đó các cửa sổ nằm trong ô xanh sẽ được trả lại làm các ô chứa mặt: nếu có các ô đè lên nhau cùng chứa một mặt, các toạ độ các góc sẽ được cộng vào lấy trung bình.
Cái việc cộng vào lấy trung bình các ô trùng nhau trên kia các bạn không biết mình phải tìm bao lâu mới ra đâu ._.
Nhiều chữ quá! o_O
Vậy thì xem video này để có thêm cảm giác về cách hoạt động của Haar Cascade nhé!
Vậy dùng như thế nào đây?
Về mục này thì có khá nhiều bài đã viết rồi, trong đó thì đây là một bài khá cụ thể mình tìm được của bạn Ngô Văn Tiến. Ngoài ra, bạn có thể đọc link này của OpenCV nếu bạn muốn đọc bản gốc bằng tiếng Anh. Mình sẽ copy luôn đoạn code trên trang chủ của OpenCV tại đây:
import numpy as np
import cv2, sys
prefix = '/usr/local/lib/python3.7/site-packages/cv2/data/'
face_cascade = cv2.CascadeClassifier(prefix + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(prefix + 'haarcascade_eye.xml')
img = cv2.imread(sys.argv[1])
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Hãy thay đổi prefix với nơi bạn cài OpenCV, và đưa đường dẫn ảnh bằng param đầu tiên lúc gọi file này nhé. Chúng ta có kết quả của hàm này như sau:

Kết quả không được tốt lắm, nhưng ăn liền thế là tốt rồi... Chúc càng bạn thành công, và have fun!
Disclaimer cuối bài cho càng nhiều chữ này: tất cả những bài mình viết đều theo ý mình sau khi đọc nhiều tài liệu trên mạng. Tất cả citations đều được link bằng hyperlink trong các phần trong bài. Nếu bạn nào thấy mình viết còn hời hợt, mình xin lỗi và cảm ơn bạn vì nhận xét đó để cải thiện bài viết tiếp theo. Còn bạn nào bảo mình đạo văn và chỉ đi dịch bài về thì xin bạn chỉ mình những bài đó để mình tranh luận về cáo buộc đó của bạn. Cảm ơn các bạn đã đọc bài của mình : )
All rights reserved
