
Bạn đã biết gì về prompt engineering? - Tổng hợp các tips tạo lời nhắc cho ChatGPT
Bài đăng này đã không được cập nhật trong 3 năm
Chắc thời gian qua các bạn cũng đã bắt gặp những bài viết với tiêu đề như "Kỹ sư tạo lời nhắc cho chatbot AI có thể kiếm 7,86 tỉ đồng/năm mà không cần bằng cấp công nghệ", hay "How to Get a Six-Figure Job as an AI Prompt Engineer". Vậy bạn có từng tự hỏi, chính xác thì kỹ sư tạo lời nhắc (prompt engineer) là làm cái gì?
Có thể so sánh như này, nếu mô hình ngôn ngữ lớn (LLM) như ChatGPT là sức mạnh ma thuật (🫠) thì prompt chính là "thần chú" và prompt engineer chính là "phù thủy". Phù thủy nào cũng có quyền năng nhưng phù thủy xịn đọc thần chú càng đúng, càng chuẩn thì phép thuật càng có hiệu quả và thực hiện được những việc đúng như mong đợi.
Trong bài viết này, chúng ta sẽ tìm hiểu về khái niệm prompt engineering và tầm quan trọng của nó trong việc cải thiện hiệu quả của các mô hình ngôn ngữ. Mình cũng sẽ tổng hợp lại các tips cũng như best practices để tạo ra prompt hiệu quả hơn.
Prompt là gì?
Prompt (lời nhắc): là đầu vào hoặc truy vấn được cung cấp cho LLM để thu được một phản hồi cụ thể từ mô hình. Lời nhắc có thể là một câu hoặc câu hỏi bằng ngôn ngữ tự nhiên, hoặc kết hợp thêm cả các đoạn code, tùy thuộc vào lĩnh vực và nhiệm vụ. Các lời nhắc cũng có thể được xâu chuỗi, nghĩa là đầu ra của một lời nhắc có thể được sử dụng làm đầu vào của một lời nhắc khác, tạo ra các tương tác động và phức tạp hơn với mô hình.
Prompt engineering: còn được gọi là Prompt Design, là các phương pháp giao tiếp với LLM để điều khiển hành vi của nó nhằm đạt được kết quả mong muốn mà không cần cập nhật trọng số mô hình. Đây là một môn khoa học thực nghiệm và hiệu quả của các phương pháp thiết kế lời nhắc có thể khác nhau tùy thuộc vào mô hình, do đó đòi hỏi nhiều thử nghiệm và kinh nghiệm.
Ví dụ: thay vì đưa cho ChatGPT một lời nhắc đơn giản như “viết về trí tuệ nhân tạo”, bạn có thể thêm thông tin bổ sung vào lời nhắc để có kết quả tốt hơn, như "viết một bài blog về các ứng dụng của trí tuệ nhân tạo trong giáo dục với các ví dụ cụ thể"
Tại sao/ khi nào thì cần dùng prompt?
Prompt engineering vs Fine-tuning
Thông thường khi sử dụng mô hình ngôn ngữ cho một domain hoặc một task cụ thể, ta sẽ nghĩ ngay đến việc fine-tune model trên tập training data có sẵn. Với LLM thì finetune cũng là một trong những cách tiếp cận cho bài toán của chúng ta. Trong phần này mình sẽ so sánh ưu, nhược điểm của 2 cách tiếp cận này.
| Prompt engineering | Fine-tuning |
|---|---|
| Với mỗi lượt, trực tiếp chỉ cho model cách nó nên phản hồi | Đào tạo mô hình cách phản hồi để không phải hướng dẫn qua prompt |
| Nhanh và dễ sử dụng | Cần có kiến thức sâu hơn về NLP và training mô hình |
| Chỉ cần một lượng rất nhỏ ví dụ | Cần nhiều anotated data: Lượng data cần để tuning phụ thuộc vào model và bài toán, nhưng thông thường cần ít nhất vài trăm samples để thấy được hiệu quả. |
| Cho phép kết hợp kiến thức miền (domain knowledge) và thông tin theo ngữ cảnh để cải thiện độ chính xác và mức độ phù hợp. Mô hình có thể thích ứng với các task và lĩnh vực khác nhau. | Mỗi khi domain hoặc bài toán thay đổi phải tiến hành training lại |
| Cho phép kiểm soát và tùy chỉnh tốt hơn các phản hồi của mô hình. Nhưng có thể không hiệu quả bằng việc finetune trong một số task nhất định. | Model có performance tốt hơn/ độ chính xác cao hơn với các task cụ thể. |
Sẵn có các model đã được đào tạo để tuân theo chỉ dẫn một cách rất hiệu quả như ChatGPT, gpt-35-turbo, gpt-4 của OpenAI, sẵn sàng để sử dụng dưới dạng API |
Dùng các LLM open-source hoặc base model như davinci của OpenAI, cần GPU hoặc trả phí để training |
| Mất chi phí tính theo số lượng token của prompt và response. Prompt càng dài và chi tiết, có nhiều ví dụ thì chi phí sẽ tăng theo. Tuy nhiên chi phí inference hiện tại cho gpt-35-turbo khá là rẻ ($0.002/ 1000 token ~ 700 từ tiếng Anh) | Có thể tối ưu chi phí dự đoán (inference) vì không cần đưa nhiều chỉ dẫn vào prompt nữa. Tuy nhiên, nếu sử dụng model của các bên như OpenAI thì bên cạnh chi phí lúc inference sẽ mất thêm chi phí hosting cho model ($2/h) |
Như vậy có thể thấy, khi không có nhiều data và tài nguyên tính toán, đồng thời muốn kiểm soát chặt chẽ phản hồi của mô hình thì chúng ta có thể sử dụng prompt engineering. Về lâu về dài, khi đã thu thập được đủ nhiều data và có bài toán thật cụ thể thì chúng ta cũng có thể chuyển sang fine-tune mô hình hoặc tìm cách kết hợp cả 2 phương pháp sao cho tối ưu.
Phương pháp viết prompt hiệu quả
Dưới đây là một số tips trong việc xây dựng prompt cho LLM, cụ thể là GPT 3.5 và GPT 4 của OpenAI, mà mình tổng hợp và rút ra được trong quá trình sử dụng. Chúng ta có thể kết hợp một/ nhiều kỹ thuật tùy theo yêu cầu và bài toán của mình. Thường thì một prompt sẽ bao gồm các nội dung như sau (nhưng không nhất thiết phải có tất cả):
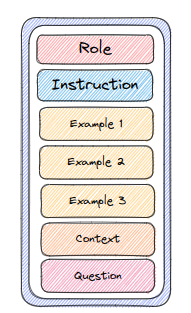
1. Đưa chỉ dẫn (instruction prompting)
Một trong những phương pháp tạo lời nhắc đơn giản nhất là đưa ra hướng dẫn những gì mà bạn muốn LLM thực hiện hoặc một số quy tắc, quy định buộc phải tuân theo.
 Ví dụ:
Ví dụ:
Dịch câu sau sang tiếng Nhật: "I love programming"
Tóm tắt đoạn văn dưới đây: {INSERT PARAGRAPH}
Hãy trả lời thành thật câu hỏi sau. Nếu không có thông tin hoặc không chắc chắn, hãy nói "Tôi không biết". {INSERT QUESTION}
AI hiện đại cũng có thể làm theo các chỉ dẫn phức tạp hơn nhiều, nhất là những mô hình được train với Reinforcement Learning from Human Feedback (RLHF) như ChatGPT.
- Instruction càng rõ ràng, cụ thể, dễ hiểu càng tốt.
- Lặp lại nhiều lần những yêu cầu, chỉ dẫn quan trọng
- Dùng lời nhắc mang tính khẳng định thay vì phủ định
- Dùng markup language (các dấu ngoặc, dấu quote, gạch đầu dòng, vv.) để phân tách rõ ràng giữa các yêu cầu khác nhau, giữa các phần khác nhau của prompt
- Cung cấp chỉ dẫn một cách tuần tự, từng bước một. Có thể chia một prompt lớn thành các bước nhỏ, đơn giản hơn.
- Mô tả cụ thể về cách format output đầu ra, như giọng điệu, phong cách viết, độ dài, điểm nhìn (ngôi thứ nhất, thứ hai hoặc thứ ba), vv., đưa ra các ví dụ về output mong muốn
2. Role Prompting
Một kỹ thuật gợi ý khác là gán vai trò (role) cho AI. Ví dụ: lời nhắc của bạn có thể bắt đầu bằng "You are a doctor" hoặc "Act as a prominent lawyer" và sau đó yêu cầu AI trả lời một số câu hỏi về y tế hoặc pháp lý. Khi gán một role cho AI, chúng ta đã cung cấp cho nó một số bối cảnh giúp nó hiểu câu hỏi tốt hơn và ta cũng phần nào đó định hình được cách mà nó phản hồi (như phong cách viết, phạm vi thông tin mà nó cung cấp)
 Ví dụ:
Ví dụ:
You are a helpful, friendly assistant chatbot whose mission is to provide information about a company named "The Boring Company"
3. Cung cấp ví dụ (in-context learning)
Mặc dù các LLM đã học được các pattern và thông tin từ lượng lớn training data và có thể đưa ra câu trả lời chính xác cho một số nhiệm vụ như dịch, trả lời câu hỏi, phân tích cảm xúc (sentimental analysis), vv. mà không cần thêm thông tin hay hướng dẫn gì khác (zero-shot learning), sẽ có những trường hợp model cho ra đáp án không chính xác hay format đầu ra không như ý do bản chất task mà chúng ta yêu cầu nó thực hiện, do thiếu thông tin hoặc do model chưa transfer được những gì nó biết vào task hiện tại.

Một cách để tăng độ chính xác cho phản hồi của mô hình là cung cấp cho nó các ví dụ để học theo. Few-shot learning đưa ra một tập hợp các ví dụ tiêu biểu, chất lượng cao về nhiệm vụ cần được thực hiện, mỗi ví dụ bao gồm cả input và output mong muốn (trường hợp có một ví dụ còn gọi là one-shot learning). Nhờ nhìn thấy các ví dụ tốt, mô hình có thể hiểu rõ hơn ý định của người dùng và các yêu cầu đối với câu trả lời được tạo ra. Do đó, few-shot learning thường mang đến hiệu quả cao hơn so với zero-shot.
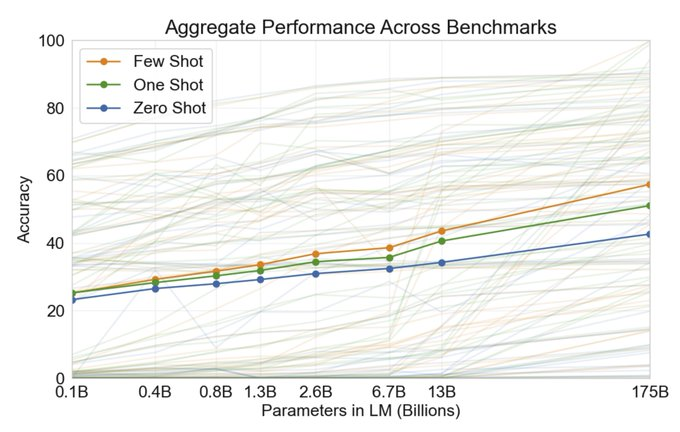
Nhiều nghiên cứu đã xem xét cách xây dựng các ví dụ để tối đa hóa hiệu suất và nhận thấy rằng lựa chọn định dạng lời nhắc, ví dụ đào tạo và thứ tự của các ví dụ có thể dẫn đến performance khác nhau đáng kể, từ gần như đoán random đến gần như SoTA.
Một vài tips:
- Chú ý đến cấu trúc, format của các ví dụ được cung cấp. Giả sử với bài toán gán nhãn, nếu chúng ta muốn model chỉ trả về 1 trong 2 kết quả: positive/ negative thay vì có thêm lời giải thích hay các phần râu ria khác, ta cần thể hiện rõ và nhất quán điều này trong từng ví dụ. Few-shot learning là một cách rất tốt để mô tả định dạng output mà ta mong muốn
- Một số bias có thể gặp phải: (1) Majority label bias gặp phải khi phân phối nhãn giữa các ví dụ không cân bằng; (2) Recency bias - model có thể lặp lại nhãn của ví dụ cuối cùng; (3) Common token bias tức là LLM có xu hướng sinh ra các token thường gặp hơn là các token ít gặp
- Một cách để cân bằng các bias trên là contextual calibration, thêm các ví dụ có input là N/A và gán nhãn cho nó sao cho xác suất của các nhãn đồng đều với nhau, với kỳ vọng mô hình sẽ bớt thiên lệch về một nhãn nào đó
- Lựa chọn tập ví dụ đa dạng, xếp theo thứ tự ngẫu nhiên, gần về mặt ngữ nghĩa với các ví dụ test.
- Một số phương pháp lựa chọn ví dụ phức tạp hơn dùng KNN, Graph, contrastive learning, Q-learning, active learning có thể tham khảo tại đây
Một điểm cần chú ý khi sử dụng phương pháp này là độ dài của prompt và max_tokens của model. Nếu thêm nhiều ví dụ hoặc ví dụ quá dài sẽ làm tăng chi phí cũng như có thể khiến output bị gián đoạn do vươt quá số token quy định (context length).
4. Chain-of-Thought
Đây là một phương pháp viết lời nhắc trong đó ta sẽ yêu cầu model suy nghĩ theo từng bước, giải thích từng bước cách mà nó đưa ra câu trả lời.
Như trong hình dưới đây, với cùng một đề bài, khi cung cấp một "bài mẫu" trong đó bài toán được suy luận và giải từng bước một và yêu cầu model làm tương tự (Let's think step by step), nó đã có thể trả về kết quả đúng.
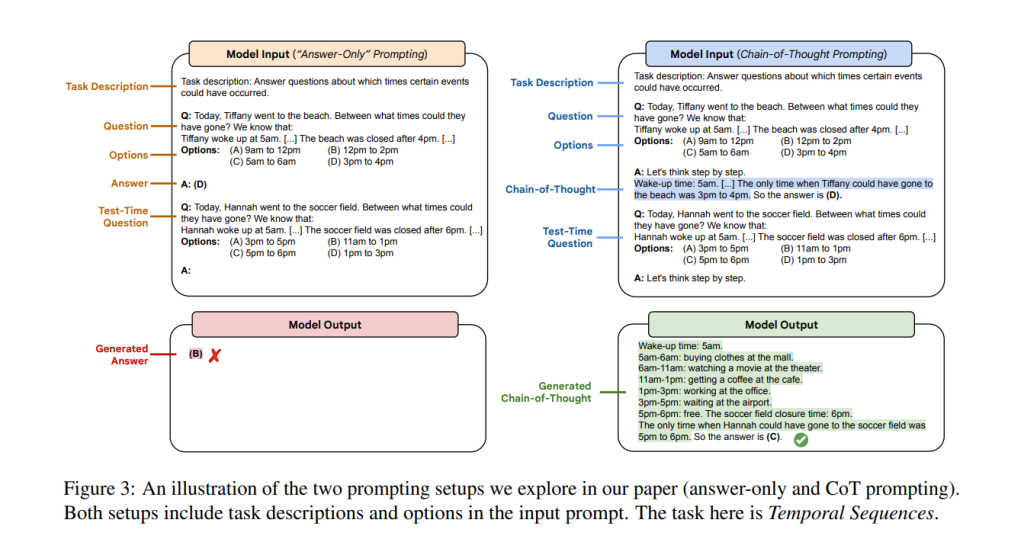
Chain-of-Thought đã được chứng minh là có hiệu quả trong việc cải thiện kết quả đối với các task như số học, logic và lý luận. Một nghiên cứu cũng cho thấy CoT chỉ mang lại kết quả tốt đối với các model lớn hơn ~ 100 tỷ tham số. Model có kích thước càng lớn thì lợi ích nhận được từ CoT prompting càng lớn nhờ khả năng sinh ra "dòng suy nghĩ" có logic hơn.
5. Điều chỉnh tham số
Ở phần giới thiệu về API của OpenAI trong bài "Đu trend" ChatGPT - Sinh augmentation data cho bài toán NLP mình có mô tả về các tham số truyền vào khi gọi API Creation của OpenAI. Thay đổi các tham số này có thể giúp chúng ta kiểm soát được đầu ra của mô hình.
Ví dụ:
- Set
temperature=0để mô hình trả về kết quả cố định cho mọi lần thử - Tạo ra nhiều output với cùng một input bằng cách thay đổi tham số
nvà chọn cái tốt nhất hoặc lấy kết quả được trả về nhiều nhất trong các lần - Kiểm soát chi phí cũng như độ dài của kết quả với
max_tokens
Hãy thử nghiệm nhiều lần và tìm ra cho mình bộ tham số phù hợp nha. Các bạn có thể tham khảo đầy đủ mô tả về các tham số tại đây.
Một số "cái bẫy" khi sử dụng LLM và cách "tránh bẫy" với prompt engineering (tương đối thui)
Đọc đến đây thì chắc hẳn các bạn đều đồng ý với mình rằng LLM nói chung và ChatGPT nói riêng là một công cụ vô cùng mạnh mẽ và quyền lực phải không nào. Tuy nhiên cũng như mọi "quyền năng" khác, nó cũng có một số điểm yếu có thể trở thành con dao hai lưỡi nếu chúng ta không chú ý.
Các bạn có thể tìm đọc thêm: ChatGPT hay là "Chết GPT"?
Dưới đây là một số vấn đề hay gặp phải mà chúng ta cần chú ý khi sử dụng LLM/ ChatGPT, nhất là khi đưa nó vào sản phẩm
- Một trong những vấn đề to đùng nhất của LLM chính là Hallucinations, hay hiện tượng mô hình "bịa" ra câu trả lời cho câu hỏi mà nó không biết, hoặc đưa ra thông tin không có thực/ sai sự thực.
=> Giải pháp: thêm vào lời nhắc các hướng dẫn như "trả lời trung thực dựa trên các thông tin XYZ sau", "nếu không biết thì hãy nói là tôi không biết", cố gắng cung cấp thông tin bối cảnh và thu hẹp domain trả lời của model, tìm cách lọc những thông tin sai lệch (ví dụ như URL, email, SĐT, vv.), yêu cầu model tự đánh giá lại/ chỉ trích câu trả lời của nó (mình sẽ nói thêm về phần này trong các bài sau)
- Nội dung có thiên kiến, thù ghét, không thích hợp: Vì LLM được đào tạo trên một lượng cực lớn dữ liệu, việc nội dung được sinh ra có những thiên kiến (bias), khuôn mẫu (stereotype) hay kỳ thị, phân biệt là một khả năng rất lớn. Vì vậy cần cẩn thận khi sử dụng LLM trong các ứng dụng hướng tới người tiêu dùng và cũng cẩn thận khi sử dụng chúng trong nghiên cứu (chúng có thể tạo ra kết quả thiên lệch). Các model được đào tạo với RLHF như ChatGPT sẽ ít khả năng có những nội dung như vậy hơn, hoặc nếu sử dụng API của Azure thì họ sẽ có thêm một bộ lọc cho các nội dung "có vấn đề".
=> Giải pháp: dưới đây là một lời nhắc "mẫu" mà chúng ta có thể tham khảo cho mô hình của mình:
We should treat people from different socioeconomic statuses, sexual orientations, religions, races, physical appearances, nationalities, gender identities, disabilities, and ages equally. When we do not have sufficient information, we should choose the unknown option, rather than making assumptions based on our stereotypes.
- Một vấn đề nữa của các LLM hiện tại là các thông tin của nó thường đã "outdated", hoặc thiếu các thông tin chuyên ngành. Cộng với tật hay "hoang tưởng" thì việc sử dụng ChatGPT hay các LLM khác như một trợ lý cung cấp thông tin là không khả thi.
=> Giải pháp: tích hợp các database/ công cụ tìm kiếm online, đưa thông tin vào prompt để cung cấp bối cảnh cho LLM theo kiểu in-context learning. Các bạn hãy đón đọc các bài tiếp theo trong series của mình để khai thác thêm các tiềm năng khác của LLM nhé!
Kết luận
Sự trỗi dậy của các mô hình ngôn ngữ lớn (LLM - Large Language Models) như ChatGPT của OpenAI đã cách mạng hóa lĩnh vực xử lý ngôn ngữ tự nhiên và mở ra những khả năng mới cho các ứng dụng như chatbot, trợ lý ảo và sáng tạo nội dung.
Song hành cùng với sự gia tăng việc ứng dụng các mô hình ngôn ngữ trong nhiều lĩnh vực, việc phát triển các kỹ thuật giúp cải thiện độ chính xác và tính liên quan của kết quả đầu ra cũng trở nên cấp thiết. Đó là lý do tại sao kỹ thuật prompt engineering ra đời - một bước quan trọng trong tối ưu hiệu quả của các mô hình ngôn ngữ. Hiểu biết về prompt engineering cũng như các cách tạo prompt hiệu quả chính là câu "thần chú" giúp bạn sử dụng "quyền năng" LLM, và biết đâu, nó sẽ là chiếc chìa khóa mở ra cánh cửa đến với các cơ hội mới thì sao.
References
All rights reserved
