
[Paper Explain] YOLOv7: Sử dụng các "trainable bag-of-freebies" đưa YOLO lên một tầm cao mới (phần 3)
Bài đăng này đã không được cập nhật trong 3 năm
Mở đầu
Trong phần 1 của series giới thiệu YOLOv7, mình đã nói qua về các khái niệm, kĩ thuật sẽ xuất hiện trong YOLOv7, các bạn có thể đọc lại ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-1-zXRJ8BGOVGq
Và phần 2 của series này mình đã tập trung nói về Label Assignment (LA), một vấn đề khá là khó nhưng lại cần thiết cho Object Detection thời hiện đại, đồng thời giải thích luôn LA của YOLOv7, các bạn có thể đọc lại ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-2-0gdJz0YEVz5
Và trong phần cuối của series này, mình sẽ nói về toàn bộ những thay đổi của YOLOv7 mà mình biết. Hiện paper của YOLOv7 vẫn còn khá mới và còn khá nhiều điều chưa được giải thích, tuy nhiên, mình nghĩ những gì mình viết hiện tại cũng sẽ khá là đầy đủ và mình sẽ bổ sung vào chính post này sau khi YOLOv7 được làm rõ hơn. Nếu có thắc mắc gì các bạn có thể góp ý cho mình ở phần comment, rất cảm ơn những đóng góp của các bạn.
Kiến trúc
YOLOv7 sử dụng:
- Backbone: ELAN (YOLOv7-p5, YOLOv7-p6), E-ELAN (YOLOv7-E6E)
- Neck: SPPCSPC + (CSP-OSA)PANet (YOLOv7-p5, YOLOv7-p6) + RepConv
- Head: YOLOR + Auxiliary Head (YOLOv7-p6)
Backbone
ELAN Block
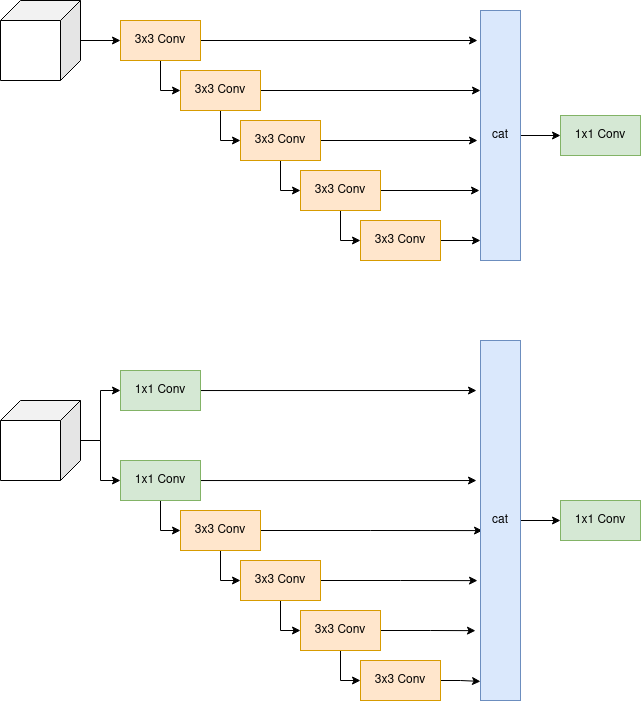
YOLOv7 sử dụng backbone là ELAN (Efficient Layer Aggregation Network). Vì paper ELAN được nhắc tới trong YOLOv7 là một paper ẩn nên mình xin phép không phân tích sâu về backbone của YOLOv7 ở thời điểm hiện tại. Khi nào ELAN được public thì mình sẽ quay lại đây về phân tích kĩ về nó. Backbone của YOLOv7 được tạo từ các ELAN block (Hình 1)
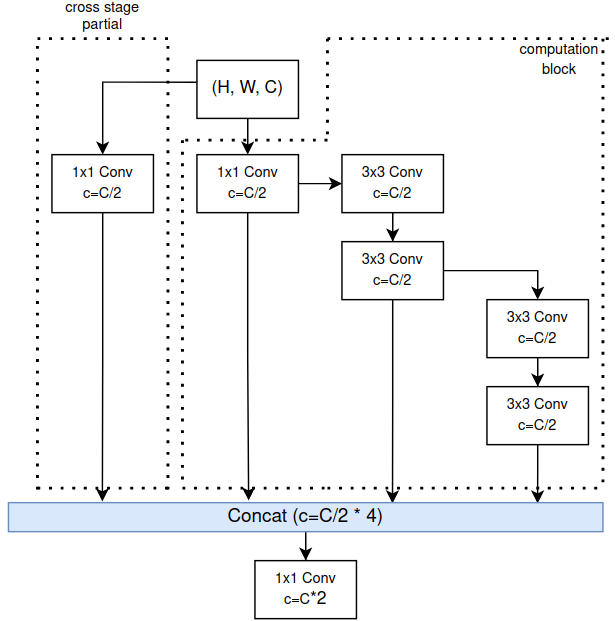
Một ELAN block gồm 3 phần: Cross Stage Partial, Computation Block và phép PointWiseConv. Thiết kế của ELAN Block chịu ảnh hưởng từ 2 nghiên cứu trước đó là CSPNet và VoVNet. Ý tưởng CSP hóa (CSP-ized) một block đã xuất hiện từ YOLOv4, các bạn có thể xem lại ở đây. CSP hóa một block là việc tạo thêm một nhánh "cross stage partial" như trên Hình 1. Computation Block là block chứa các lớp Conv được tính toán để sinh ra các feature mới thông qua các Conv. Cuối cùng, các feature maps được tổng hợp lại ở cuối sử dụng toán tử concatenate trên chiều channel như VoVNet, và đưa qua PointWiseConv ( Conv). Nếu chưa rõ về VoVNet, các bạn có thể đọc ở đây.
Transition Block
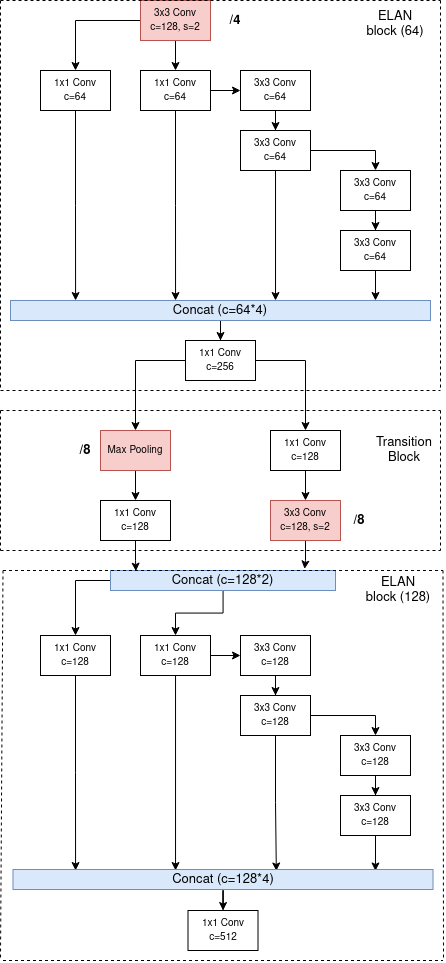
Các ELAN Block được kết nối với nhau thông qua các Transition Block (Hình 2). Mỗi Transition Block là một lần giảm kích cỡ của feature maps đi 2 lần.
Stem
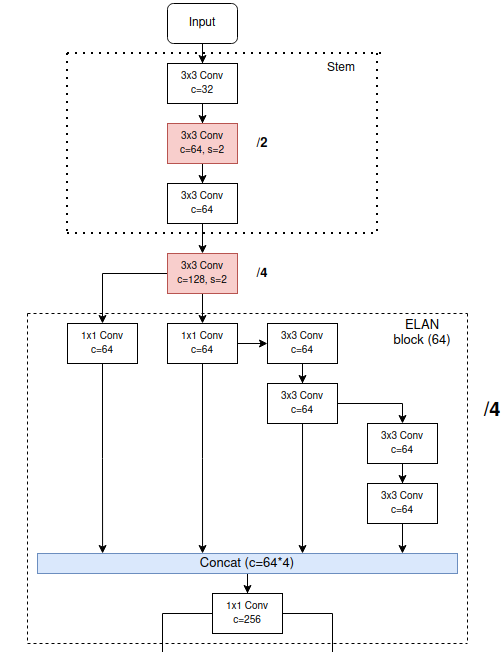
Trước khi tiến vào ELAN Block đầu tiên trong backbone, ảnh đầu vào sẽ đi qua Stem Block (Hình 3).
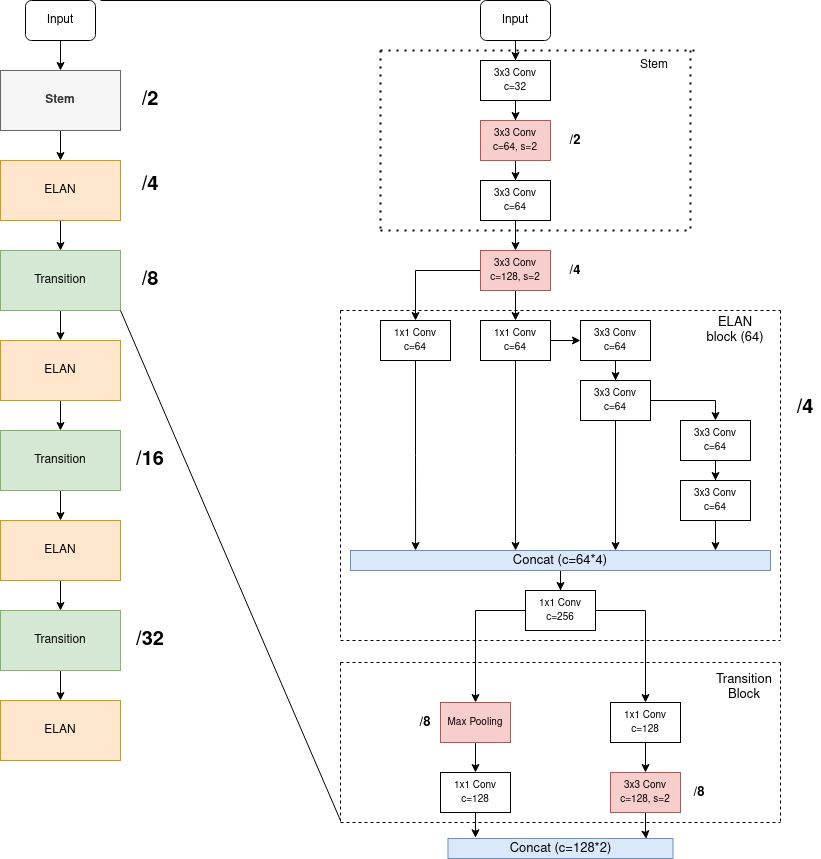
Backbone hoàn chỉnh của YOLOv7 là tập hợp của các ELAN Block và các Transition block, cụ thể như Hình 4.
Neck
SPPCSPC
SPP lần đầu được áp dụng vào YOLOv4, và được cải tiến thành SPPF ở trong YOLOv5. Nếu không nhớ về SPP và SPPF, các bạn có thể đọc lại ở đây: https://viblo.asia/p/tong-hop-kien-thuc-tu-yolov1-den-yolov5-phan-3-63vKjgJ6Z2R.
Còn trong YOLOv7, SPP tiếp tục được CSP hóa, kiến trúc của SPPCSPC ở Hình 5.
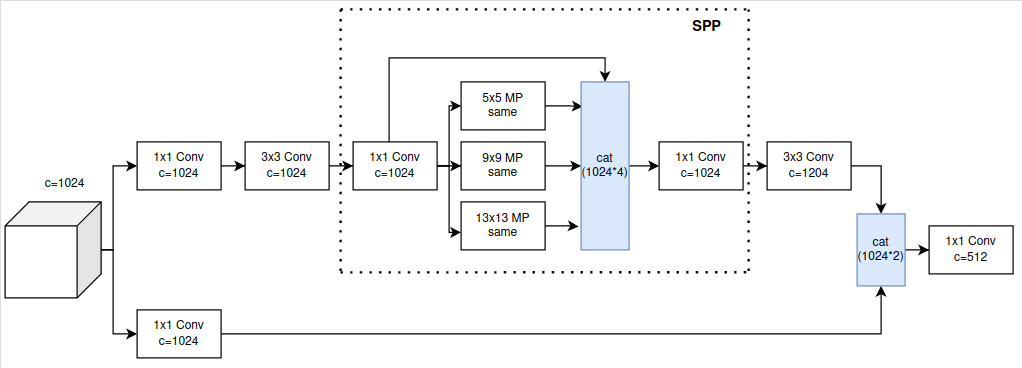
Có 1 điều khá lạ ở SPPCSPC đó chính là 2 đường đều có số channels bằng với số channels trong feature maps ban đầu, thay vì là một nửa như CSP thông thường.
Mình cũng đã có thử nghiệm đo Params, FLOPs và tốc độ của SPPCSPC so với SPP và tốc độ cho thấy SPPCSPC cực kì nặng và chậm.
Bạn nào muốn thử thì code mình có để ở dưới đây
def get_model_info(model: nn.Module, tsize) -> str:
from thop import profile
from copy import deepcopy
import time
import torch
stride = 64
img = torch.zeros((tsize[0], tsize[1], stride, stride), device=next(model.parameters()).device)
start = time.time()
flops, params = profile(deepcopy(model), inputs=(img,), verbose=False)
end = time.time()
delta = end - start
params /= 1e6
flops /= 1e9
flops *= tsize[2] * tsize[3] / stride / stride * 2 # Gflops
info = "Params: {:.2f}M, Gflops: {:.2f}, time: {:.6f}".format(params, flops, delta)
return info
Kết quả của SPP trên CPU:
model = SPP(1024, 1024)
tsize = [16, 1024, 20, 20]
print(get_model_info(model, tsize))
>>> Params: 2.62M, Gflops: 33.63, time: 4.426360
Kết quả của SPPCSPC trên CPU:
model = SPPCSPC(1024, 512)
tsize = [16, 1024, 20, 20]
print(get_model_info(model, tsize))
>>> Params: 7.61M, Gflops: 97.49, time: 7.837845
(CSP-OSA)PANet
PANet là một phiên bản mở rộng của FPN (Feature Pyramid Network). PANet lần đầu được áp dụng trong họ nhà YOLO là YOLOv4, về ý tưởng của PANet, các bạn có thể đọc lại ở đây: https://viblo.asia/p/tong-hop-kien-thuc-tu-yolov1-den-yolov5-phan-3-63vKjgJ6Z2R#_pan-7
Ở YOLOv7, toán tử cộng để kết hợp 2 feature maps từ 2 scale vào với nhau đã được thay thế bằng toán tử concatenate. Hơn nữa, sau khi kết hợp với feature maps từ scale trên, sinh ra một feature maps trung gian, feature maps trung gian này tiếp tục được xử lý bằng CSP-OSA module thay vì được tiếp tục kết hợp thẳng với feature maps từ scale dưới như FPN hay PANet thông thường (Hình 6).
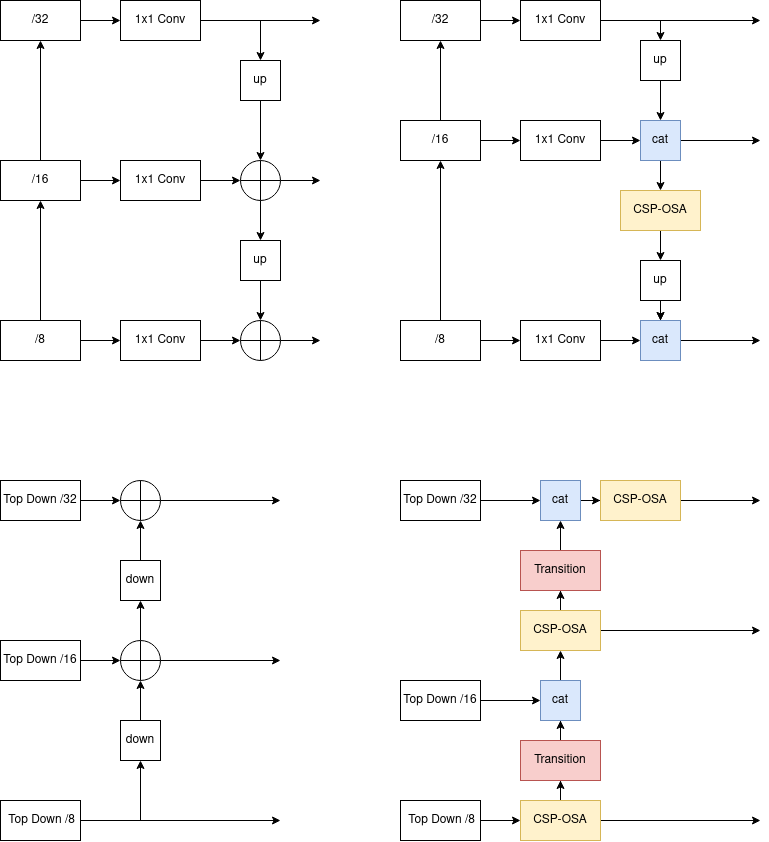
CSP-OSA là một tên gọi do mình tự chế vì mình thấy nó giống OSA module được CSP hóa. OSA module bắt nguồn từ VoVNet, là một module cực kì nhanh và tiết kiệm điện năng. CSP-OSA module có kiến trúc ở Hình 7.
RepConv
Các feature maps từ các scale khác nhau sau đi đưa qua FPN hay PANet sẽ được xử lý thêm với Conv ứng với từng scale. Còn trong Neck của YOLOv7, việc xử lý này sẽ được thực hiện bởi RepConv, một module với tốc độ của Conv nhưng độ chính xác thì cao hơn rất nhiều. RepConv sử dụng kĩ thuật Re-param để có một module tốc độ cao mà độ chính xác cũng cao. Kĩ thuật này mình đã nói tới ở phần 1: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-1-zXRJ8BGOVGq#_re-parameterization-4 và một bạn trong team mình cũng đã có bài phân tích về RepConv tại đây nên mình sẽ không nói sâu về RepConv nữa.
Neck của YOLOv7 có kiến trúc tổng quát như sau
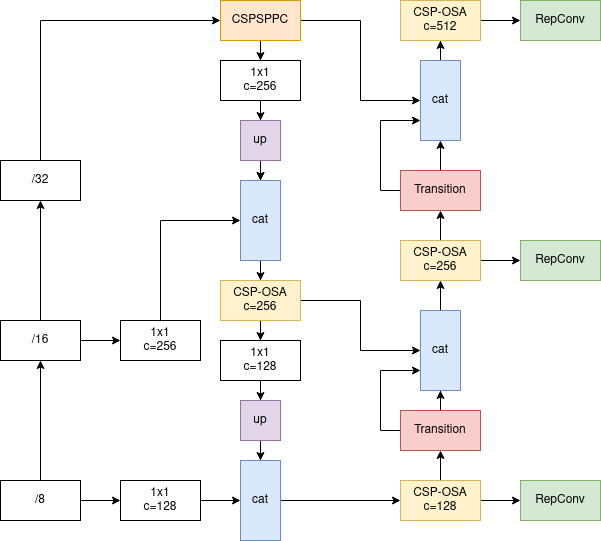
Head
Head của YOLOv7 chỉ đơn giản là YOLOR, sử dụng implicit knowledge, chứ không có gì khác
Những thay đổi khác
Về phần này thì không có gì đáng nói, hầu hết những điểm yếu phát hiện trong YOLO đã được giải quyết trong YOLOv4 và YOLOv5 như Grid Sensitivity, Regression Loss mới, Data Augmentation,...
Lần này YOLOv7 đem đến cho chúng ta một khái niệm mới: Label Assignment. Và phần này thì mình đã dành nguyên một bài để nói về nó rồi nên mình xin phép sẽ không nhắc lại tại đây. Các bạn có thể xem về Label Assignment của YOLOv7 tại phần 2 của series này ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-2-0gdJz0YEVz5
Tuy nhiên, YOLOv7 vẫn chọn sử dụng Anchor Box và áp dụng thêm simOTA vào. Về việc không sử dụng Anchor-free, tác giả YOLOv7 giải thích rằng dù simOTA đã rất tốt rồi nhưng đối với những ảnh có kích cỡ to thì Anchor-based vẫn hội tụ tốt và nhanh hơn, nên tác giả quyết định không sử dụng Anchor-free.
Các phiên bản YOLOv7 khác nhau
Cũng giống như các YOLO khác, v7 cũng có những phiên bản khác nhau của nó như: YOLOv7, YOLOv7x, YOLOv7d6,... và ở phần này mình sẽ nói về các phiên bản khác nhau đó.
YOLOv7-p5
Đây là nhóm model được train với size ảnh . Nhóm YOLOv7-p5 bao gồm 3 model là: YOLOv7-tiny, YOLOv7 và YOLOv7x.
Model scaling
Để tạo ra các phiên bản khác nhau một cách efficient (hiệu quả), tác giả của YOLOv7 đề xuất ra một phương pháp model scaling mới cho model dạng concatenate. Các phương pháp model scaling từ trc tới giờ như EfficientNet, RegNet đều là các plain model (model không bao gồm phép concatenate). Trong Scaled-YOLOv4, tác giả cũng đã đề xuất ra một phương pháp model scaling nhưng nó vẫn chưa tốt, vì lúc đó tác giả chỉ thực hiện tăng số stage trong model.
Khi scale một model, ta sẽ scale theo 3 chiều như sau:
- Depth scaling: scale theo độ sâu, đây là cách phổ biến nhất. Scale theo độ sâu là tăng số lượng layer lên (VD: ResNet-50 -> ResNet-101 -> ResNet-152)
- Width scaling: scale theo chiều rộng của mạng. Scale theo chiều rộng là tăng số lượng channels ở trong layer lên
- Resolution scaling: scale kích cỡ của ảnh đầu vào. Ờ thì cái này chắc khỏi phải giải thích :v
Và EfficientNet lần đầu phân tích mối liên hệ giữa việc scale theo 3 chiều này, đề xuất ra một phương pháp để scale 3 chiều cùng lúc, độ chính xác tăng cao mà số lượng tham số tăng lên cũng khá ít, đó gọi là một phương pháp scale efficient.
Như đã nói ở trên, các phương pháp model scaling từng được đề xuất chưa đề cập đến dạng model concatenate. Xét Compatation Block ở bên trong ELAN Block, tác giả YOLOv7 nhận thấy rằng, nếu ta scale theo độ sâu (tăng số lượng layers trong computation block lên), thì lúc concatenate, số lượng channels sinh ra cũng sẽ được tăng lên (Hình 9).
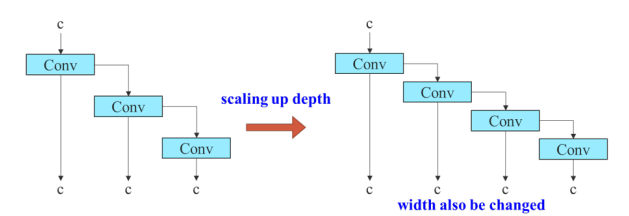
Vì vậy, tác giả của YOLOv7 sau một hồi tính toán, đã tìm ra con số scale chiều sâu lên 1.5 lần thì chiều rộng cũng sẽ được scale lên 1.25 lần. Áp dụng phương pháp scale tổng hợp theo chiều sâu và rộng vào ELAN Block, số lượng layers trong computation block của ELAN Block tăng từ (1.5 lần), số lượng channels trong lúc concatenate sẽ tăng từ (1.25 lần) (Hình 10).
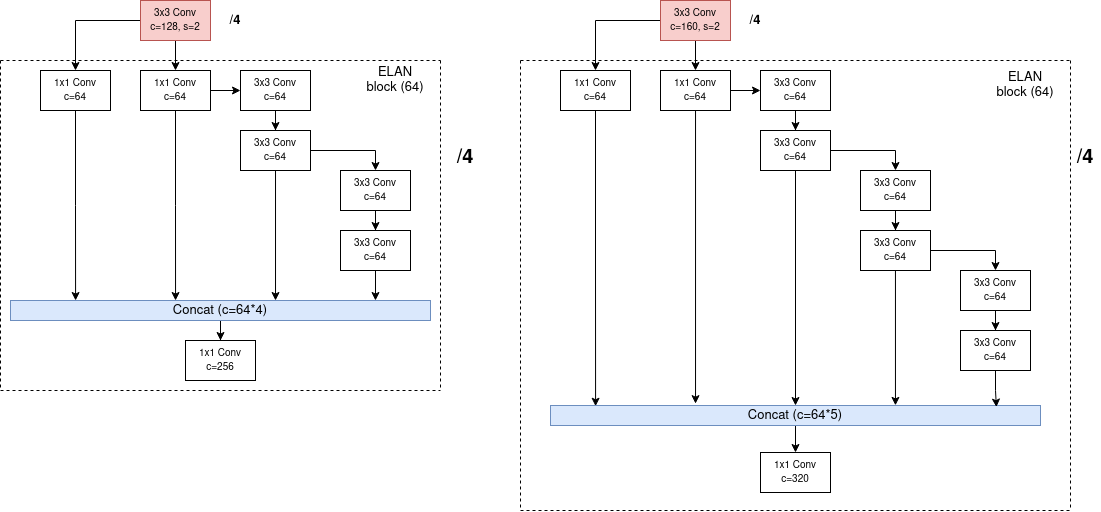
Phép scale này cũng được thực hiện lên những module khác như CSP-OSA trong Neck,...
YOLOv7-p6
Đây là nhóm model được train với size ảnh . Nhóm YOLOv7-p6 bao gồm 3 model là YOLOv7-w6, YOLOv7-e6, YOLOv7-d6
Model scaling
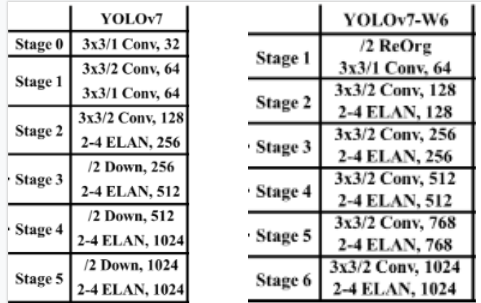
Luật scale của YOLOv7-p5 vẫn được áp dụng cho YOLOv7-p6. Lấy gốc là YOLOv7-w6, số channels và số layer của computation block trong ELAN Block của YOLOv7-w6 giống với YOLOv7. Tuy nhiên, điểm khác biệt của YOLOv7-w6 so với YOLOv7 là số stage trong backbone (Bảng 1)
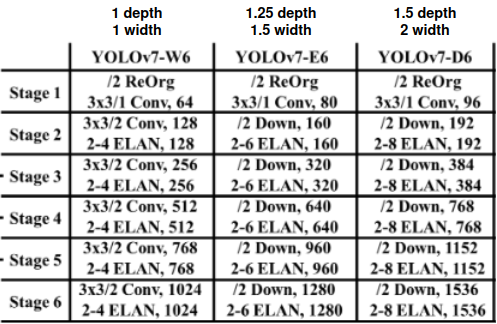
Áp dụng luật model scaling, các model dạng lớn hơn sẽ có số channels và layer trong computation block như Bảng 2
Auxiliary head (Deep Supervision)
Trong phần 1 của series này, mình đã có nhắc về Auxiliary head: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-1-zXRJ8BGOVGq#_deep-supervision-auxiliary-head-7
Áp dụng Auxiliary head vào bài toàn Classification hay Semantic Segmentation thì khá là đơn giản, vì target (ground truth) của 2 bài toán này đã khá là rõ ràng, từ đó việc tính loss cho output từ Auxiliary head cũng khá là rõ ràng luôn. Nhưng trong bài toán Object Detection, việc xách định target của bài toán (Label Assigment) còn có hẳn một hướng nghiên cứu riêng :v
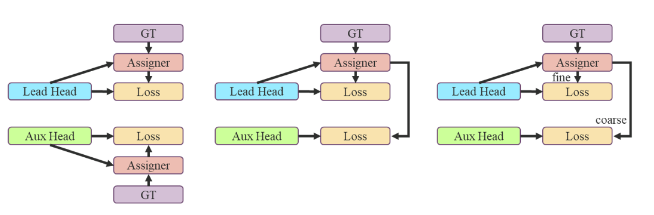
Cách dễ nhất chính là áp dụng riêng rẽ Label Assignment lên Lead Head và Aux Head (Hình 11 bên trái). Bản thân việc này như này đã đem lại kết quả rất tốt rồi, nhưng tác giả của YOLOv7 vẫn tìm ra một cách làm mới lạ hơn để cải tiến.
YOLOv7 sử dụng Label Assignment là SimOTA, simOTA sẽ sử dụng ground truth và prediction từ Head để tạo ra target, từ đó ta mới có thể tính loss giữa target và prediction của model. Thay vì để Aux Head sử dụng prediction của nó (Aux Head), để tạo ra target cho nó (Aux Head), trong YOLOv7, Aux Head sử dụng prediction của Lead Head, để tạo ra target cho nó (Aux Head) (Hình 11 ở giữa). Lý giải cho việc này là do Lead Head đã có khả năng học khá mạnh, vậy nên target được tạo ra từ Lead Head sẽ có sự biểu diễn tốt hơn và có tương quan tới ground truth cao hơn. Do vậy, Aux Head sẽ được học từ target tốt hơn, dẫn đến tối ưu tốt hơn. Hơn nữa, ta cũng có thể coi đây là "residual learning". Bằng việc để cho Aux Head học những cái mà Lead Head đã học rồi, mà Aux Head lại nằm đằng trước Lead Head (Hình 12), Lead Head có thể tập trung học thêm những thông tin "residual", thông tin mà Lead Head trước đó chưa từng học được.
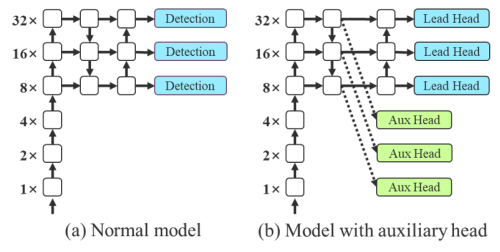
Không chỉ dừng lại ở đó, để cải tiến thêm ý tưởng sử dụng Lead Head để hướng dẫn cho Aux Head (Guided Lead Head), thay vì sử dụng cùng một target được tạo ra từ Lead Head, YOLOv7 tạo ra 2 target khác nhau từ Lead Head, một cho bản thân Lead Head (fine label), còn lai cho Aux Head (coarse label) (Hình 11 bên phải). Tất cả các Aux Head của YOLOv7 đều được áp dụng ở trong Neck như trên Hình 12.
YOLOv7-E6E
Vì model này đặc biệt hơn các loại còn lại nên mình sẽ dành nguyên 1 phần cho nó. YOLOv7-E6E cũng được train với size ảnh 1280 như nhóm YOLOv7-p6 nhưng không áp dụng đúng luật model scaling.
Tác giả YOLOv7 nhận thấy rằng, nếu áp dụng luật model scaling thông thường lên ELAN và tăng số layer trong Computation Block lên thì sẽ phá vỡ trạng thái ổn định của ELAN. Nếu tiếp tục tăng số layer trong Computation Block lên, độ chính xác vẫn có thể cải thiện tuy nhiên, độ hiệu quả sẽ không được như mong muốn khi hiệu năng tính toán không còn được tốt nữa. Vì vậy, tác giả đã tạo ra E-ELAN (Extended ELAN) có kiến trúc như Hình 13.
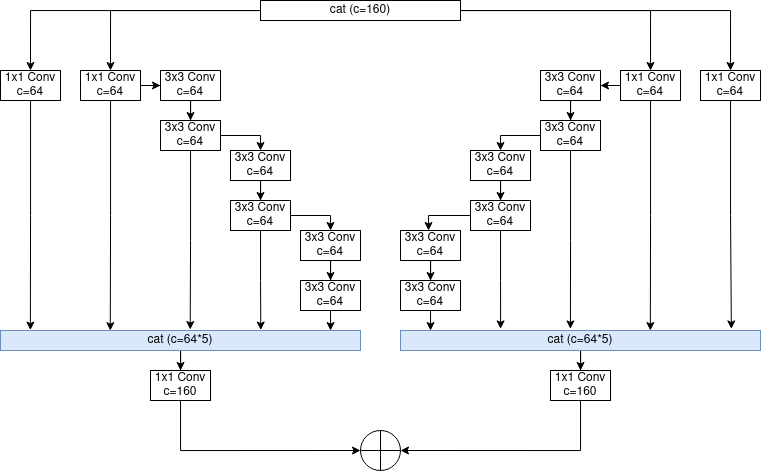
Việc mở rộng kiến trúc này không chỉ áp dụng lên ELAN trong backbone mà còn áp dụng lên cả CSP-OSA trong Neck.
Và đương nhiên, YOLOv7-E6E cũng áp dụng cả Auxiliary Head như họ YOLOv7-p6
Kết
Và bài viết này đã khép lại series phân tích YOLOv7 của mình. Nếu có bất cứ sai sót gì các bạn có thể góp ý cho mình ở trong phần bình luận
Reference
YOLOv7: https://arxiv.org/abs/2207.02696
All rights reserved
