
[AICrowdChallenge] Food Recognition - Nhận biết đồ ăn với Deep Learning?
Bài đăng này đã không được cập nhật trong 5 năm
I. Introduction
Xin chào mọi người, trước khi đi vào nội dung bài viết, mọi người cùng xem một vài hình ảnh sau đây trước nhé:

Đây là hình ảnh về các món ăn và đã được phân vùng và nhận biết về loại của nó, cụ thể ở đây chúng ta có cơm, cá hồi, mì ý và bơ... trông khá cool và hay ho phải không mọi người. Thực ra đây là một cuộc thi, challenge về nhận biết các món ăn trên CrowAI trong một ngày đẹp trời mình tình cờ nhìn thấy khi đang lướt twitter, vì nội dung rất hay nên mình đã không ngần ngại đăng ký để kéo data về ngồi nghịch. Ở đây có khá nhiều các competition khác khá hay ho, mình nghĩ đây là một nguồn data rất tốt và cũng là một nơi mà mọi người có thể training skill của mình. Mọi người có thể xem thêm về cuộc thi tại link này https://www.aicrowd.com/challenges/food-recognition-challenge nha.
Còn ở bài viết này mình sẽ nói về cách mà mình dùng để giải quyết bài toán này ra sao nhé.
II. Problem summary
Có thể nói đây là một bài toán hay, nếu không muốn nói là khó về Pattern Recognition trong Computer Vision, nhiệm vụ của chúng ta là phải nhận biết đc các món ăn trong một bức ảnh. Tuy nhiên, không giống với những bài toán thông thường khác, điểm khó khăn là các món ăn ngoài đời thực có hình dáng rất đa dạng, ngay cả khi chúng là cùng một loại nhưng ở từng thời điểm chúng sẽ có những hình dạng khác nhau, màu sắc hơi khác nhau và hơn nữa là thường thì sẽ có nhiều hơn một món ăn và overlap nhau trong một bức ảnh. Giả sử chúng ta có bức ảnh sau:

Ở bức ảnh này, chúng ta có 3 đối tượng đã được nhận biết là trà, bánh mỳ, và mứt. Điểm khó khăn chúng ta có thể nhận ra ở đây là làm sao để có thể tách biệt được mứt và bánh mỳ trong khi chúng đang overlap nhau, cách giải quyết đầu tiên để có thể nghĩ đến đó là dùng object detection tuy nhiên cách này mình nghĩ chưa thể giải quyết được những trường hợp một loại món ăn được bố trí ở các hình thái khác nhau, đè lên nhau, chưa kể một số món ăn còn có màu sắc và hình dáng khá giống nữa. Vì vậy possible approach ở đây là chúng ta sẽ tận dụng cả object detection và instance segmentation. Các kiến thức về object detection và instance segmentation tớ xin phép không chia sẻ ở đây, ở scope bài này mình chỉ tập trung vào vấn đề cài đặt giải quyết bài toán thui nha. Nào bây giờ cùng ngó qua dataset 1 tí, xem nó có gì nhé.
III. Dataset
Giới thiệu qua về dataset, thì bộ dữ liệu về Food này được collect trên 1 app có tên là MyFoodRepo được thu thập dựa trên rất nhiều tình nguyện viên là các users tại thuỵ sĩ cung cấp hình ảnh và dữ liệu về các bữa ăn hàng ngày của họ. Dữ liệu đã được annotate và verify trước khi public ra ngoài để làm dữ liệu cho cuộc thi này, các dữ liệu này đều là các hình ành thực tế khác xa so với những hình ảnh món ăn chúng ta thường hay nhìn thấy trên mạng => có thể áp dụng nó cho các bài toán thực tế được, ngoài ra file annotation cũng đã được format sẵn theo COCO format. Cùng xem qua thống kê một chút nhé:
from collections import Counter
class_counts = Counter()
for image_info in dataset.image_info:
ann = image_info["annotations"]
for i in ann:
class_counts[i["category_id"]] += 1
class_mapping = {i["id"]: i["name"] for i in dataset.class_info}
class_counts = pd.DataFrame(class_counts.most_common(), columns=["class", "count"])
class_counts["class"] = class_counts["class"].apply(lambda x: class_mapping[x])
plt.figure(figsize=(12, 12))
plt.barh(class_counts['class'], class_counts['count'])
plt.title('Counts of classes of objects');
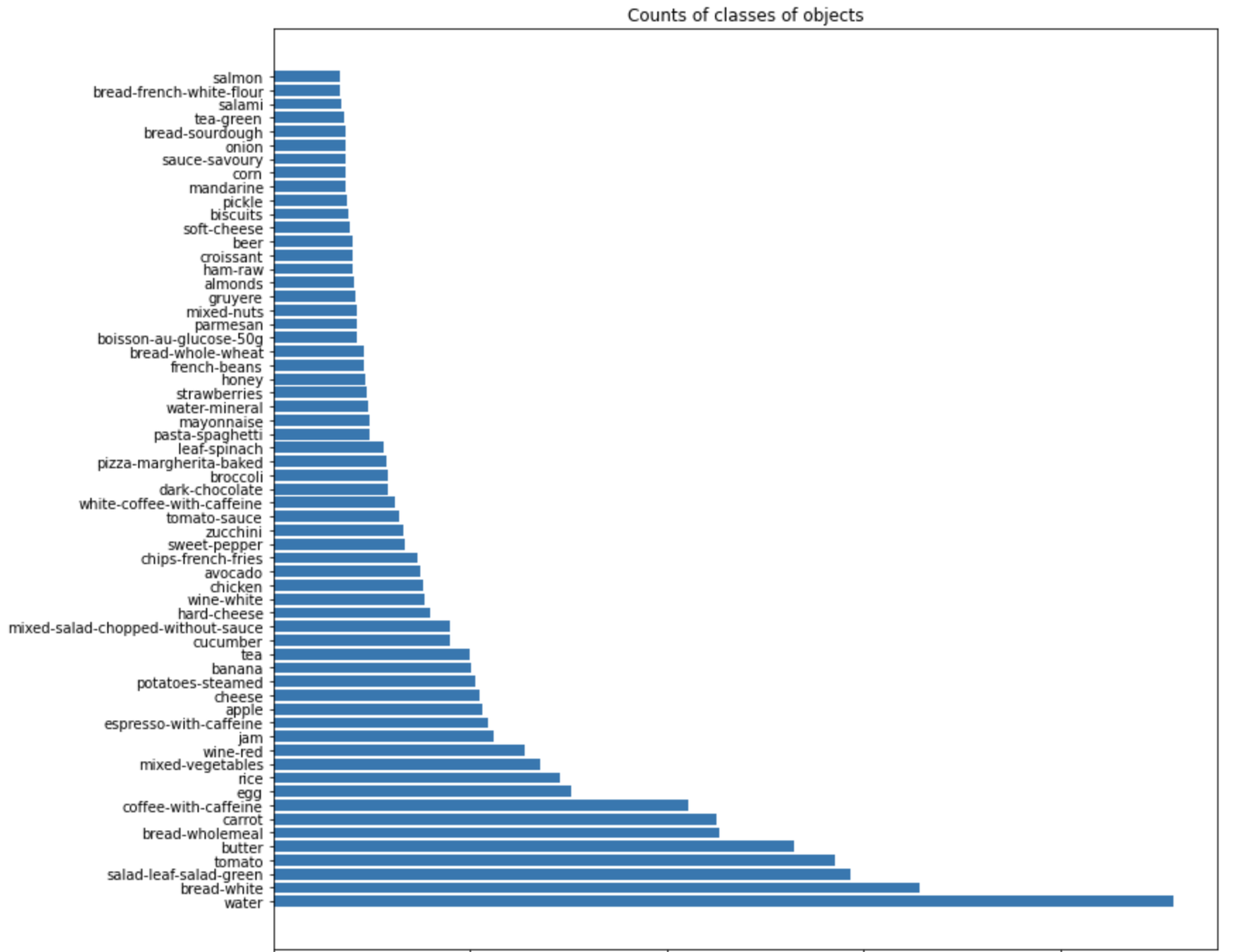

Ở đây chúng ta có tất cả 62 classes, trong đó có 61 classes chính và 1 class là background. Trong số những class này thì water và bánh mỳ trắng là 2 class chiếm số lượng lớn nhất, ngược lại cá hồi là chiếm số lượng ít nhất. Ngoài ra còn có một số class nổi bật như: tomato, carrot, egg, rice, wine-red, wine-white, vân vân và mây mây...
Mình sẽ show thử lên một ảnh mẫu:
image_id = random.choice(dataset.image_ids)
image = dataset.load_image(image_id)
plt.imshow(image)
mask, class_ids = dataset.load_mask(image_id)
bbox = utils.extract_bboxes(mask)
print("image", image_id, dataset.image_reference(image_id))
log("mask", mask)
log("class_ids", class_ids)
log("image", image)
log("bbox", bbox)
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names, figsize=(12, 12))

Code random ra 1 ảnh chứa rượu trắng từ file annotation, thú thực mà nói giữa rượu trắng và nước trắng rất khó để model có thể phân biệt được, hơn nữa nó lại được đựng trong 1 cái ly trong suốt như thế này. Thực sự đoạn này mình chưa tự tin lắm về khả năng model có thể generalize ra kết quả chính xác được không 
Tiếp theo mình sẽ check thêm một chút về các shape của các món ăn xem sao nhé:
image_ids = np.random.choice(dataset.image_ids, 4)
for class_id in np.random.choice(list(class_images.keys()), 10):
image_id = np.random.choice(class_images[class_id], 1)[0]
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
visualize.display_top_masks(image, mask, class_ids, dataset.class_names)
Kết quả mẫu:

Chúng ta có thể thấy là thường thì rất ít khi các món ăn sẽ tách rời nhau mà hay overlap lên nhau, hình dạng của chúng cũng rất đa dạng nữa.
Tiếp theo là các bbox:
for idx, class_id in enumerate(np.random.choice(list(class_images.keys()), 10)):
image_id = np.random.choice(list(class_images[class_id]), 1)[0]
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
bbox = utils.extract_bboxes(mask)
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names, figsize=(12, 12))

Nhìn ảnh này, t hơi mất niềm tin vào khả năng model có thể nhận diện được không, nhưng thôi cứ phải thử train mới biết được  )
)
IV. Implement Algorithm
Chúng ta vẫn sẽ tiếp cận theo hướng cũ, tuy nhiên ở đây sau khi cặm cụi tự build model rồi train nhưng không thấy khả quan tớ quyết định chuyển qua dùng thử Mask RCNN xem sao. Thì ở đây t sẽ nói qua về Mask RCNN nhé, thì đây là phiên bản nâng cấp của Faster RCNN được đội ngũ AI research của FB tạo ra phục vụ cho các bài toán Object detect và segment, ưu điểm của Mask RCNN là cho độ chính xác cao, tuy nhiên nhược điểm đổi lại cho việc đạt được độ chính xác cao thì tốc độ response khá chậm. Lý do t chọn Mask RCNN là bởi vì ngoài những ưu điểm đã được nói quá nhiều ở các papers, blogs ra thì như ở trên t có đề cập là Dataset đã được annotate theo format của COCO, mà thằng Mask RCNN này nó lại support nên việc training sẽ thuận lợi hơn rất nhiều. Dưới đây là kiến trúc mô hình hoạt động của Mask RCNN:
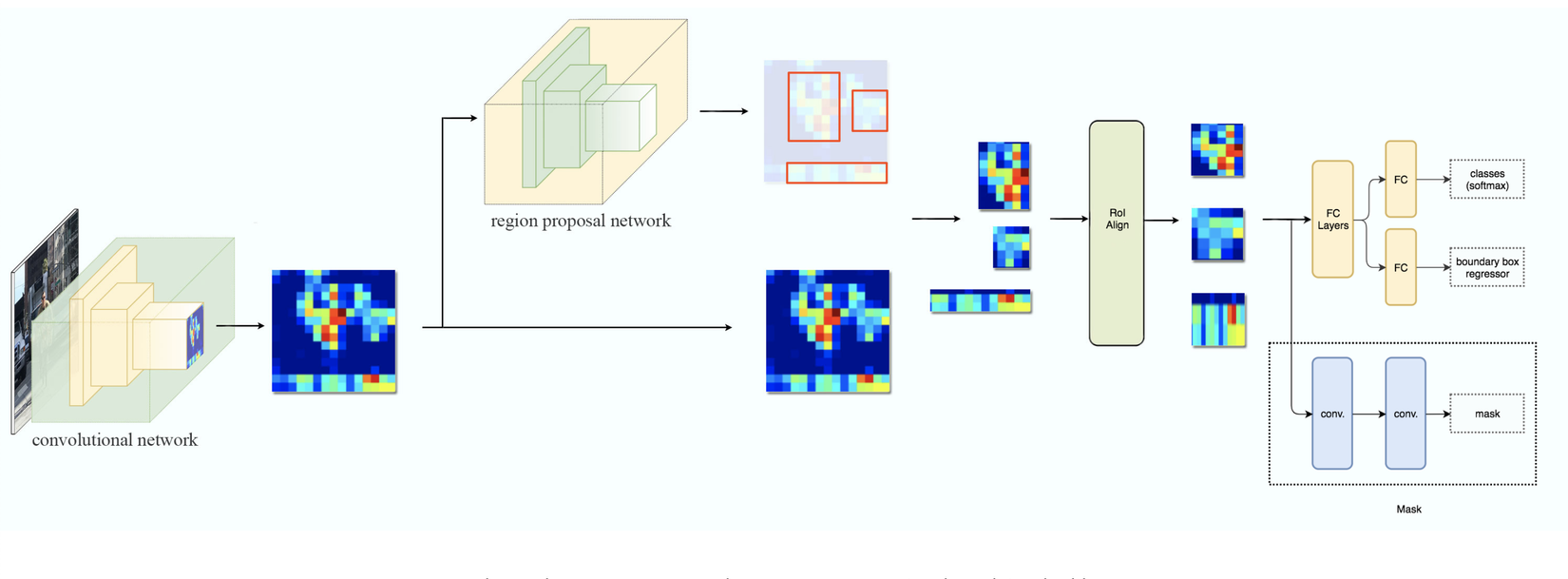
Quan sát hình ảnh trên đấy có thể thấy, Mask RCNN chia thành 3 phần chính, phần thứ nhất gọi là backbone, dùng để extract ra các image features để phục vụ cho việc xác định location và shape của object. Các backbone này thường là Resnet50 hoặc Resnet101, kiến trúc backbone là rất sâu và lưu 1 lượng tham số mô hình rất lớn trước khi được đưa vào RPN để xác định location vật thể và 1 mạng decoder để tìm mask.
Cùng xem qua các thông tin như default anchor boxes, ROI xem sao nhé:
image_id = np.random.choice(dataset.image_ids, 1)[0]
image, image_meta, _, _, _ = modellib.load_image_gt(dataset, config, image_id)
fig, ax = plt.subplots(1, figsize=(10, 10))
ax.imshow(image)
levels = len(backbone_shape)
for level in range(levels):
colors = visualize.random_colors(levels)
level_start = sum(anchors_per_level[:level])
level_anchors = anchors[level_start:level_start+anchors_per_level[level]]
print("Level {}. Anchors {:6} Feature map shape: {}".format(level, level_anchors.shape[0], backbone_shape[level]))
center_cell = backbone_shape[level] // 2
center_cell_index = (center_cell[0] * backbone_shape[level][1] + center_cell[1])
level_center = center_cell_index * anchors_per_cell
center_anchor = anchors_per_cell * (
(center_cell[0] * backbone_shape[level][1] / config.RPN_ANCHOR_STRIDE**2) \
+ center_cell[1] / config.RPN_ANCHOR_STRIDE)
level_center = int(center_anchor)
for i, rect in enumerate(level_anchors[level_center:level_center+anchors_per_cell]):
y1, x1, y2, x2 = rect
p = patches.Rectangle((x1, y1), x2-x1, y2-y1, linewidth=2, facecolor='none',
edgecolor=(i+1)*np.array(colors[level]) / anchors_per_cell)
ax.add_patch(p)
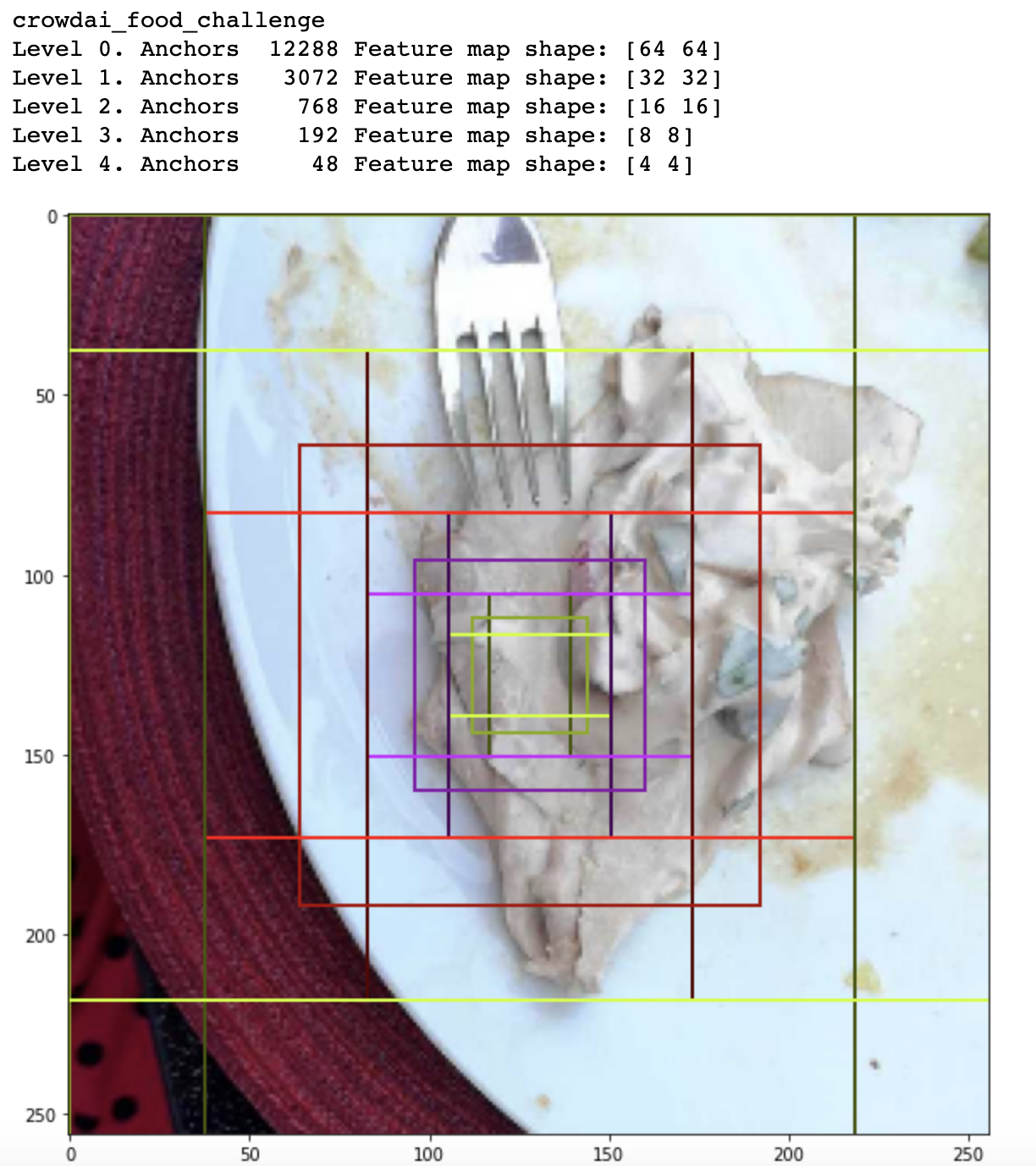
Ở đây chúng ta có thể thấy ở mỗi level của feature maps đều có 1 set các default anchor boxes ở các ratio khác nhau, điều này giúp cho việc mô hình có thể xác định được object ở các tỉ lệ scales. Mọi người có thể đọc thêm về Mask RCNN nha, cũng như hiểu thêm về các thành phần như anchor boxes, ROI, scales, ratio ở các papers như: Faster RCNN, SSD...
Tiếp theo mình sẽ đi chi tiết vào việc implement thuật toán nhé.
Việc đầu tiên chúng ta sẽ làm đó là define ra một class dataset để chuẩn bị dữ liệu phục vụ cho việc training với các functions được định nghĩa như sau:
def load_dataset(self, dataset_dir, load_small=False, return_coco=True):
self.load_small = load_small
if self.load_small:
self.annotation_path = os.path.join(dataset_dir, "annotations-small.json")
else:
self.annotation_path = os.path.join(dataset_dir, "annotations.json")
image_dir = os.path.join(dataset_dir, "images")
assert os.path.exists(self.annotation_path) and os.path.exists(image_dir)
self.coco = COCO(self.annotation_path)
self.image_dir = image_dir
class_ids = self.coco.getCatIds()
image_ids = list(self.coco.imgs.keys())
#Register classes
for _class_id in class_ids:
self.add_class("crowdai_food_challenge", _class_id, self.coco.loadCats(_class_id)[0]["name"])
#Register images
for _img_id in image_ids:
assert os.path.exists(os.path.join(self.image_dir, self.coco.imgs[_img_id]["file_name"]))
self.add_image(
"crowdai_food_challenge", image_id=_img_id,
path=os.path.join(self.image_dir, self.coco.imgs[_img_id]["file_name"]),
width=self.coco.imgs[_img_id]["width"],
height=self.coco.imgs[_img_id]["height"],
annotations=self.coco.loadAnns(self.coco.getAnnIds(
imgIds=_img_id,
catIds=class_ids,
iscrowd=None
)
)
)
if return_coco:
return self.coco
Vì file annotation đã được annotate theo format của coco nên việc xây dựng một data generator trở nên dễ dàng hơn rất nhiều bằng cách ở đây tớ dùng pycoco api để load data từ file annotation.js lên. Trong function này tớ khởi tạo 1 instance coco, rồi dùng api của nó để tạo ra các cặp class_id: class_name tương ứng và các annotations tương ứng với từng images. Việc làm tiếp theo là chúng ta cần load các annotated mask tương ứng với từng image_id. Code như sau nha:
def load_mask(self, image_id):
image_infor = self.image_info[image_id]
instance_masks = []
class_ids = []
annotations = self.image_info[image_id]["annotations"]
for annotation in annotations:
class_id = self.map_source_class_id("crowdai_food_challenge.{}".format(annotation["category_id"]))
if class_id:
m = self.annToMask(annotation, image_infor["height"], image_infor["width"])
if m.max() < 1:
continue
instance_masks.append(m)
class_ids.append(class_id)
if class_ids:
mask = np.stack(instance_masks, axis=2)
class_ids = np.array(class_ids, dtype=np.uint32)
return mask, class_ids
else:
return super(FoodChallengeDataset, self).load_mask(image_id)
Đến đây là cũng khá ổn rồi, chúng ta đã có data để train, có label tương ứng với mỗi mask, tiếp theo là sửa một số default config để chuẩn bị cho việc training:
class FoodChallengeConfig(Config):
NAME = "crowai-food-challenge"
IMAGES_PER_GPU = 2
GPU_COUNT = 1
BACKBONE = 'resnet50'
NUM_CLASSES = 62 # n_classes + background
STEPS_PER_EPOCH = len(dataset_train.image_ids) // 2
VALIDATION_STEPS = len(dataset_val.image_ids) // 2
LEARNING_RATE = 0.001
IMAGE_MAX_DIM = 256
IMAGE_MIN_DIM = 256
config = FoodChallengeConfig()
config.display()
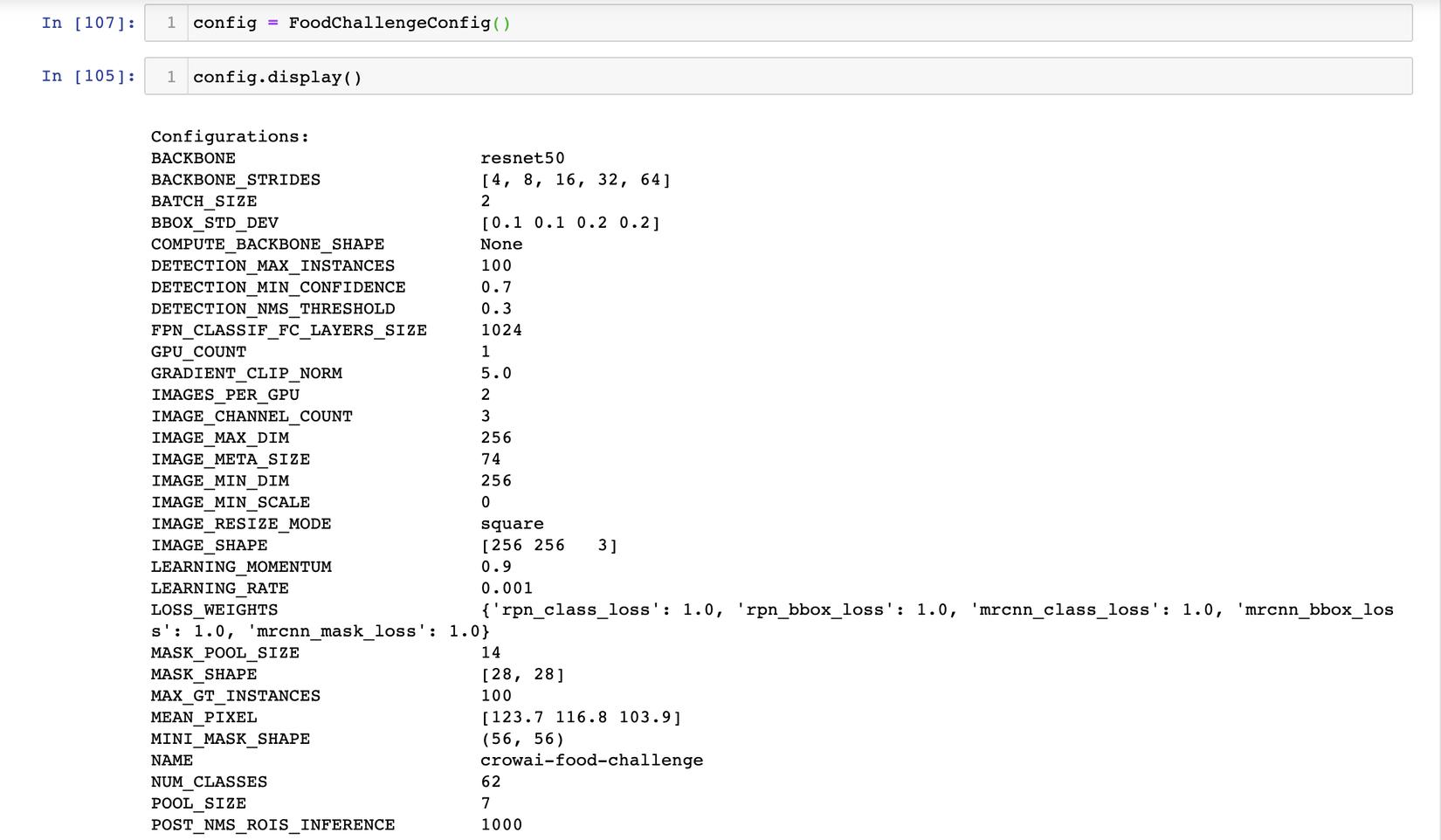
1 số thuộc tính có thể config như tên config, giá trị batch_size, ở đây giá trị batch_size sẽ bằng với giá trị của IMAGES_PER_GPU * GPU_COUNT, backbone chính là base_model, ở đây mình dùng resnet50 vì mình nghĩ nó đủ sâu rồi, mọi người có thể change nó thành resnet 101, mobileNet tuỳ theo từng bài toán nhé. Một số các thuộc tính quan trọng khác như: LEARNING_RATE, IMAGE_MAX_DIM, IMAGE_MIN_DIM...
Ok giờ ổn rồi, fit vào model để train nhé:
Ở đây t đang train trên kaggle, nhưng vì thời gian train khá lâu nên cứ được 1 thời gian ngắn nếu không để ý là kernel nó lại shutdown -_- . Cảm ơn người ae trong team Phan Huy Hoàng đã giúp mình cắm máy để train trong gần 1 ngày, ngoài ra hoàng cũng là 1 người có rất nhiều kinh nghiệm trong team, có các bài viết rất hay, mọi người có thể đọc thêm về các bài ở trang cá nhân của bạn ấy.
Ok quay trở lại bài viết, sau khi train xong 35 epochs, mình nhận được kết quả như sau, mọi người cùng xem nhé:
Dưới đây là code predict:
for i in range(4):
image_id = np.random.choice(dataset_val.image_ids, 1)[0]
original_image, image_meta, gt_class_id, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
r = model.detect([original_image])
r = r[0]
visualize.display_instances(original_image, r['rois'], r['masks'], r['class_ids'],
dataset.class_names, r['scores'], figsize=(10, 10))
Và kết quả:



Improvement and Future work
Tại đây mình sẽ nói về cái được và cái chưa được và những điều có thể làm để có thể improve được mô hình này, thì đầu tiên là kết quả tổng quan sau 35 epochs mình thấy chưa thực sự tốt lắm và vẫn có thể improve lên được nữa, ở trên đây mọi người có thể thấy mình vẫn chưa apply data augm vào cũng như k apply bất kỳ 1 phương pháp tiền xử lý nào cho images trước khi fit vào model để train. Đó là 2 điều đầu tiên mình nghĩ có thể làm để tăng khả năng generalize của model và giảm tỉ lệ overfit.
Trong tương lai, với bài toán này, mình sẽ cố gắng tiếp tục xây dựng lại model from scratch xem sao, và không chỉ dừng lại ở mức nhận biết món ăn, chúng ta hoàn toàn có thể tính được lượng calo trong thực ăn để điều chỉnh lượng thức ăn trong mỗi bữa ăn sao cho hợp lý. Mình vẫn sẽ tiếp tục cải thiện bài toán này và tiếp tục làm những dự định kia, nhưng giờ mình phải kiếm được data đã , hi vọng có dip quay trở lại chia sẻ với mọi người kỹ hơn và hay hơn.
Cảm ơn mọi người đã đọc đến đây, mọi ý kiến đóng góp mọi ngừoi có thể comment phía dưới hoặc gửi mail cho mình @nguyen.van.dat@sun-asterisk.com
VI. Reference
https://viblo.asia/u/phanhoang
https://arxiv.org/pdf/1506.01497.pdf
https://arxiv.org/pdf/1512.02325.pdf
https://github.com/matterport/Mask_RCNN
https://www.aicrowd.com/challenges/food-recognition-challenge/dataset_files
All rights reserved
