
[Vinh danh Paper] QLoRA: Quantize để training mô hình hàng tỷ tham số trên Google Colab
Bài đăng này đã không được cập nhật trong 3 năm
Mình sẽ phải mở đầu bài này bằng một câu khen: Đây là một paper cực kì tuyệt vời! Lần đầu tiên mình có thể đem áp dụng ngay một paper ngay khi nó mới ra mắt và đạt được kết quả cực kì tốt. (Gần) Đúng như ở tiêu đề, mình đã có thể fine-tune mô hình 7 tỷ, 13 tỷ và 33 tỷ tham số với 2 con RTX 3090. Đáng nói là mô hình 7 tỷ tham số chỉ chiếm 4-5Gb/GPU, tức là ~10Gb, hoàn toàn có thể training trên Google Colab.
Đây là một paper về kĩ thuật Quantization. Nên nếu bạn đang tìm kiếm một kiến trúc model nhẹ thì đây không phải là một paper dành cho bạn. Còn nếu bạn đang tìm kiếm cách làm nhẹ model Transformer của bạn thông qua kĩ thuật Quantization thì đây là một paper rất đáng đọc, hoặc tò mò về Quantization thì cũng nên đọc về paper này.
Nhập môn Quantization
Khái niệm và một số loại data type
Quantization là quá trình biến đổi một sự biểu diễn chứa nhiều thông tin thành một dạng biểu diễn (data type - dtype) chứa ít thông tin hơn (Hình 1).
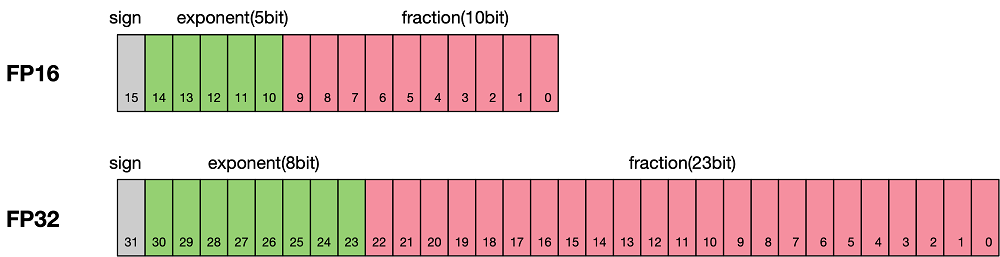
Định dạng dấu phẩy động 32 bit (Floating Point 32 - FP32) là một định dạng số máy tính. Tức là một số sẽ được lưu trữ sử dụng 32 bit trong bộ nhớ: bao gồm 1 bit dấu, 8 bit mũ và 23 bit phần lẻ. Về chính xác cách một số được biểu diễn dưới dạng FP32 như nào thì các bạn có thể Google để biết thêm chi tiết (và các bạn nên làm thế).
Các weights của models, các tensor, các activations trong model đều có thể được lưu trữ dưới dạng FP32, và nó là mặc định ở đa số các framework/library mà chúng ta sử dụng để tạo ra Neural Network (NN). Nếu ta có thể biểu diễn weights, hoặc activations mà sử dụng ít bits hơn (như trên hình là 16 bits) là ta đã giảm được rất nhiều gánh nặng về bộ nhớ, đồng thời tăng tốc trên một số thiết bị hỗ trợ tính toán 16bit.
Và thực tế là rất nhiều framework/library đã hỗ trợ và sử dụng FP16 trong training model với kĩ thuật Mixed Precision Training: dùng đồng thời cả FP32 và FP16. Một số thành phần, quá trình của model thì sẽ ở FP16, còn một số thì lại FP32 (Nếu mình sai thì các bạn có thể sửa lại cho mình phần này nhé, mình đang tạm hiểu cách hoạt động của nó là như thế).
Ngoài FP32 và FP16 thì ta còn một số dtype khác như: INT8, BF16, FP4, yada yada...:
- INT8: Biểu diễn sử dụng 8 bit và chỉ biểu diễn số nguyên
- BF16: Biểu diễn sử dụng 16 bit nhưng khác với FP16
- FP4: Biểu diễn sử dụng 4 bit và biểu diễn được phân số
Câu hỏi được đặt ra là tại sao lại có nhiều dtype, cùng là 16 bits biểu diễn nhưng lại có FP16 và BF16?
Như ở trên, mình có nói rằng có một kĩ thuật gọi là Mixed Precision Training, sử dụng đồng thời cả FP16 và FP32. Tại sao phải sử dụng đồng thời mà không sử dụng mỗi FP16 thôi. Khi một số sử dụng ít bits hơn để biểu diễn, khoảng biểu diễn của chúng sẽ bị hẹp lại. Trong NN, một số lớp sẽ sử dụng các số rất nhỏ: epsilon trong LayerNorm có giá trị ~, tuy nhiên giá trị nhỏ nhất mà FP16 biểu diễn được lại chỉ là ~. Từ đó dẫn đến sự ra đời của BF16 (BrainFloat 16). BF16 sử dụng nhiều bits cho phần exponent hơn là FP16 (Hình 2), do đó có thể biểu diễn được khoảng rộng hơn FP16, nhưng lại thiếu chính xác hơn sau dấu phẩy.
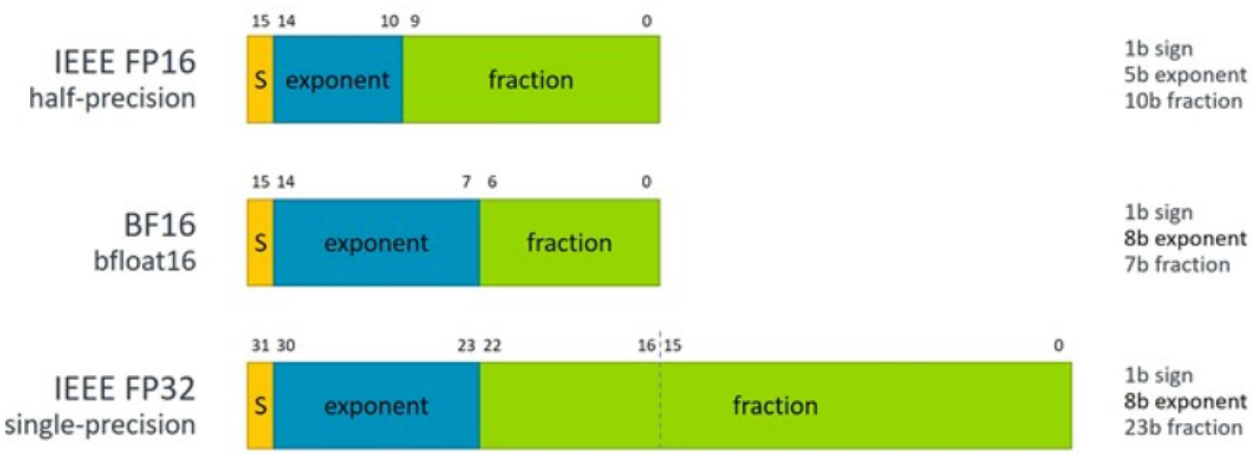
Cùng là sử dụng 16 bit để biểu diễn, tuy nhiên tùy vào cách xác định các bits mà ta sẽ thu được các dtype khác nhau. Và tất nhiên, nếu càng sử dụng ít bits biểu diễn, thì độ chính xác càng tụt giảm.
Cách quantize
Khi đã xác định được loại dtype mà muốn quantize về, thì tiếp theo ta phải áp dụng công thức để biến đổi từ dtype gốc (source dtype) sang dtype mà ta muốn quantize (target dtype). Để chắc chắn rằng có thể sử dụng toàn bộ được target dtype, ta sẽ scale source dtype về khoảng target dtype thông qua việc normalize với giá trị tuyệt đối lớn nhất hiện có của soure dtype. Ví dụ cách quantize FP32 về INT8 có khoảng giá trị như sau:
với là hằng số quantize, là phép làm tròn.
Ví dụ, ta có tensor ở dạng FP32 muốn quantize về INT8, thì hằng số quantize và tensor mới ở dạng INT8 là
Và đảo ngược từ target dtype về source dtype gọi là quá trình de-quantize:
Và xin chúc mừng các bạn đã xong nhập môn về Quantization
QLoRA
QLoRA: Quantized LoRA là một paper về quantization kết hợp vs LoRA để giúp training các mô hình siêu nặng một cách dễ dàng. QLoRA giới thiệu 3 thứ:
- NF4 (Normal Float 4): Một dtype mới, sử dụng chỉ 4 bit nhưng độ chính xác lại ở mức cực tốt
- Double Quantization: Quantize 2 lần
- Paged Optimizers: Tránh lỗi OOM
Quantization nâng cao
Các khó khăn khi Quantize
Khó khăn đầu tiên. Với việc sử dụng ít bits để biểu diễn hơn, tức là lượng thông tin cũng bị mất mát. Mình lấy ví dụ trên hình 3 thực hiện quantize từ INT3 về INT2, rất dễ để thấy rằng nếu quantize theo công thức ở phía trên thì thông tin bị mất đi tới một nửa. Vì vậy, khi quantize ta phải làm thế nào để việc mất mát thông tin là ít.
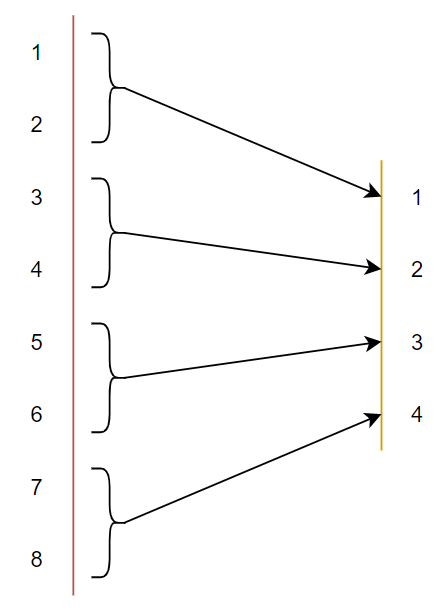
Khó khăn thứ hai. Với cách quantize như công thức phía trên thì sẽ không hề quan tâm tới phân phối của tensor ta cần phải quantize. Nhìn hình 4 thì sẽ dễ hình dung hơn, lấy ví dụ một tensor 10 phần tử có khoảng giá trị float từ , đa số các phần tử tập trung trong khoảng nhưng khi thực hiện quantize thì toàn bộ khoảng giá trị hay khoảng giá trị thì cũng ra một số, tức là khoảng sẽ được quantize về đúng 2 số. Như thế thì lại không hợp lý lắm, ta sẽ muốn khoảng được biểu diễn bởi nhiều số hơn (như hình 5).
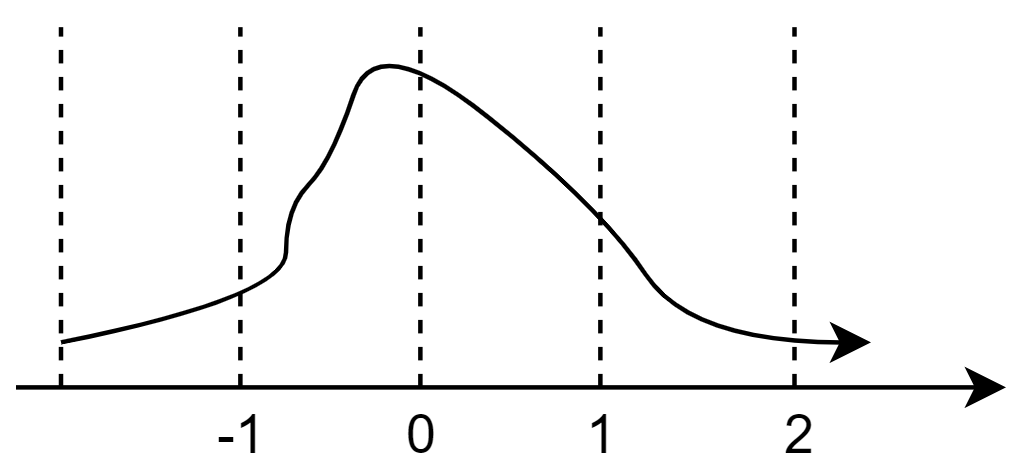
Lời giải cho khó khăn thứ hai. QLoRA sử dụng kĩ thuật quantize gọi là Quantile Quantization (Hình 5). Thay vì chia khoảng giá trị thành từng đoạn bằng nhau như ở Quantize thông thường, thì Quantile Quantization sẽ coi khoảng giá trị như một cái phân phối, và chia làm sao cho từng phần trong phân phối đấy có xác suất xảy ra bằng nhau. Một khoảng được chia như dưới kia sẽ gọi là một quantile.
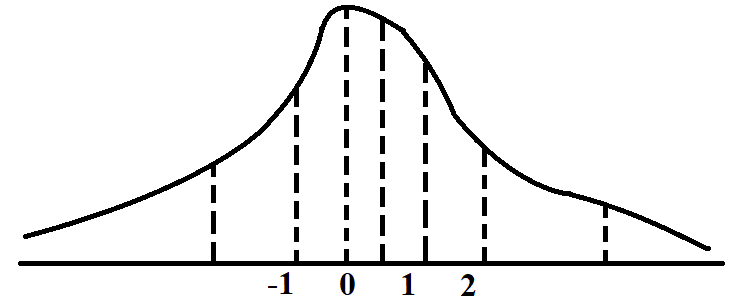
Khó khăn thứ ba. Trong một tensor sẽ có khả năng xảy ra outlier. Tức là có một số giá trị, xảy ra cực cực kì ít, nhưng lại nằm rất xa các giá trị còn lại của tensor đó (Hình 6). Đen là các giá trị đó lại thường là các giá trị cực kì quan trọng và cẩn phải biểu diễn chính xác. Do tính chất của Quantile Quantize: các khoảng quantile phải có xác suất bằng sau, khiến việc biểu diễn outlier 2.75 bị gộp vào với các giá trị từ 1.5 trở đi
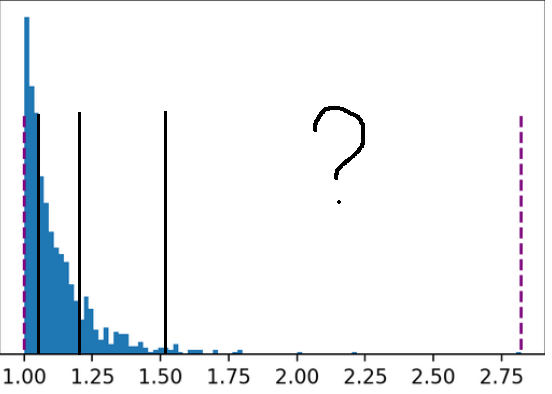
Lời giải cho khó khăn thứ ba. Thay vì quantize gộp 1 phát cả một tensor gồm nhiều phần tử, thì ta sẽ chia tensor ra làm nhiều chunks, và quantize mỗi chunk của tensor đó riêng biệt (Hình 7).
Normal Float 4: Đi tìm dtype để thực hiện Quantize
QLoRA sử dụng Quantile Quantization. Tuy nhiên, việc đi tìm quantile phù hợp cho từng tensor weights là lâu, do việc xác định các quantile là khó. Có một số thuật toán xấp xỉ quantile nhanh, nhưng làm như thế thì lại không tốt với Outlier. QLoRA nhận ra rằng, vấn đề này có thể được giải quyết nếu các tensor tuân theo cùng một loại phân phối cố định, ta sẽ chỉ cần đi tìm các quantiles một lần duy nhất, và áp dụng các quantiles đó cho toàn bộ các tensor weight thay vì cứ mỗi tensor weights thì ta phải tìm quantiles phù hợp cho chúng. QLoRA đã làm thí nghiệm chứng minh rằng đa số các tensor weights của pre-trained LLM tuân theo phân phối chuẩn với mean 0 và standard deviation . Do đó, QLoRA thực hiện biến đổi toàn bộ weights về một phân phối cố định bằng việc chia cho để phân phối sẽ nằm vừa trong khoảng giá trị của target dtype.
Và khoảng giá trị mà target dtype QLoRA muốn quantize về được đặt là . Do đó, weights của NN và target dtype sẽ được normalize về khoảng này.
Với các giả định: tensor weights của NN thuộc phân phối chuẩn với mean 0 và std , và nằm trong khoảng thì dtype sẽ được tìm ra như sau:
- Thực hiện tìm ra quantiles của phân phối chuẩn mean 0 std 1 để thu được k-bit quantile quantization dtype
- Lấy dtype vừa tìm được, scale về khoảng
Công thức tìm quantiles (bước 1) như sau:
với là hàm tính quantile của phân phối chuẩn .
Tuy nhiên, mọi thứ không đơn giản thế. Các phương pháp quantization thường là symmetric (đối xứng), tức số quantiles được chia ra một cách đối xứng (Hình 8)
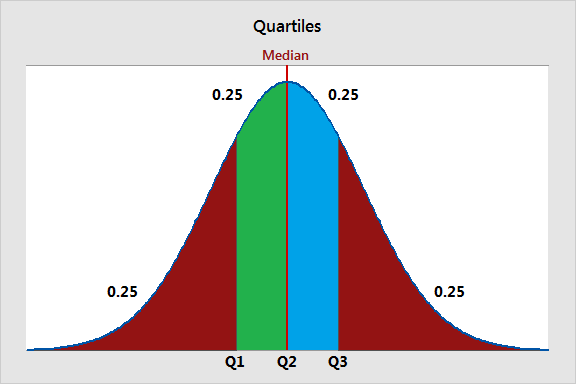
Như các bạn có thể thấy, với ví dụ là Quartiles thì không hề có sự biểu diễn chính xác cho số 0. Tại sao điều này lại quan trọng? Vì trong Deep Learning ta thường sử dụng padding, và ta sẽ pad vào tensor các giá trị . Vì thế, một yếu tố nữa được thêm vào target dtype mà QLoRA hướng đến là phải biểu diễn chính xác số . Vì vậy, QLoRA quyết định target dtype sẽ là asymmetric (bất đối xứng). Lúc này số quantiles sẽ được chia ra làm 2 phần: cho phần âm kèm số 0 và cho phần dương kèm số 0. Sau đó ta ghép 2 phần này lại và bỏ đi một số 0 (vì số 0 bị tính 2 lần). Và đó là cách mà Normal Float 4 (NF4) được tạo ra.
Tóm gọn lại, dtype NF4 có những đặc điểm sau:
- Sử dụng 4 bits biểu diễn
- Nằm trong khoảng
- Bất đối xứng, có sự biểu diễn cho giá trị 0
- Được tạo ra để áp dụng cho tensor tuân theo phân phối chuẩn mean 0 và std 1
Toàn bộ giá trị của dtype NF4 như sau:

Để thực hiện quantize tensor weight về NF4, trước tiên ta phải scale tensor weight về khoảng , sau đó ta thực hiện quantize như bình thường theo công thức ở phần Cách Quantize bên trên. Lưu ý, bước này sẽ bao gồm áp dụng cả Chunk Quantize.
Double Quantization
Đúng như tên gọi của nó, Double Quantization thực hiện quantize 2 lần. Khi ta thực hiện Chunk Quantize, nếu sử dụng nhiều chunks, với mỗi chunk sẽ có quantization constant của riêng chunk đó thì bộ nhớ để lưu trữ quantization constant cũng từ đó mà tăng lên. Vì vậy, QLoRA thực hiện quantize luôn cả quantization constant. Mỗi quantization constant của mỗi chunk sẽ được quantize về FP8 trở thành : .Với là quantization constant thu được sau khi quantize tensor weight, là constant của quantization constant còn là kết quả của quá trình quantize lần 2 này.
Có thể thấy quantize constant FP32 lại sinh ra constant FP32 nữa là (để có thể tìm ra từ ) thì làm sao mà giảm được bộ nhớ, nó lại còn tăng lên khi phải lưu trữ thêm . Khi thực hiện Chunk Quantize lần một để Quantize tensor weight, ta sử dụng block size là 64 (kiểu 64 phần tử được gộp vào làm 1 chunk), nhưng khi thực hiện Chunk Quantize cho quantization constant , ta sử dụng block size là 256, từ đó giảm số lượng phải lưu trữ lại.
Paged Optimizers
Bình thường khi training mô hình với GPU, sẽ khá là nhiều bạn gặp lỗi OOM. Và cái Paged Optimizers này giúp giải quyết vấn đề đấy. Mình không học quá sâu về phần cứng để có thể nói rõ ràng quá trình này được thực hiện một cách chi tiết nhất nên mình tóm tắt lại quá trình này như sau: ở GPU Nvidia có thứ gọi là Unified Memory. Khi training bị OOM, những thứ khiến cho GPU bị OOM sẽ được chuyển tạm thời sang CPU (tức là chuyển lưu trữ từ VRAM sang RAM), và khi nào GPU cần cái đống đấy để tính toán thì sẽ đòi lại từ CPU.
LoRA
Các bạn có thể đi đọc lại bài viết của mình về LoRA tại đây: https://viblo.asia/p/fine-tuning-mot-cach-hieu-qua-va-than-thien-voi-phan-cung-adapters-va-lora-5pPLkj3eJRZ
QLoRA
QLoRA hiện tại chỉ hỗ trợ cho Linear layer (vì LoRA cũng chỉ hộ trợ cho Linear). Một layer sẽ gồm 2 thành phần: Thành phần pretrained (freeze) và thành phần LoRA (train). Quá trình tính toán output của layer Linear có LoRA đó như sau:
với như sau:
Oke nhìn có vẻ hơi đáng sợ, cùng phân tích nó ra nào. Trước tiên ta cần phải làm rõ, trong một layer Linear layer có LoRA, thành phần pretrained được freeze và không cập nhật gradient, còn thứ cần train là thành phần LoRA. Weights của thành phần pretrained sẽ được quantize về NF4. Trong quá trình tính toán output, thành phần pretrained sẽ được dequantize từ NF4 về BF16, rồi kết hợp tính toán với thành phần LoRA ở dạng BF16. Khi tính xong thì thành phàn pretrained lại được quantize lại về NF4. Vì vậy, QLoRA giúp chúng ta có thể đưa được model to vào vừa với VRAM để training, chứ không tăng tốc độ của model (do cứ đến layer nào cần tính toán thì ta lại phải dequantize nó về BF16).
Xét công thức (1), phía bên phải dấu bằng sẽ gồm 2 thành phần: thành phần pretrained sử dụng để chuyển từ NF4 về BF16, và thành phần còn lại là LoRA. sử dụng 2 quantization constant (1 cái ở dạng NF8, 1 cái ở dạng FP32) và tensor weights ở dạng NF4 để biến đổi về BF16. Đơn giản vậy thôi!
 Tại sao QLoRA lại phải dequantize weight từ NF4 về BF16?. Vì các GPU hiện nay chưa hỗ trợ tính toán 4-bit
Tại sao QLoRA lại phải dequantize weight từ NF4 về BF16?. Vì các GPU hiện nay chưa hỗ trợ tính toán 4-bit
Kết
QLoRA là một paper tuyệt vời! Mình mong là mọi người khi đọc xong bài viết này có thể tự thử nghiệm QLoRA và train cho bản thân một mô hình 7 tỷ tham số! Và bài này cũng viết kha khá về Quantization, hy vọng nó sẽ giúp các bạn thấy Quantization thú vị và áp dụng các kĩ thuật Quantization để tăng tốc và cũng như là làm nhẹ mô hình của bản thân.
All rights reserved
