


![]() Bài viết được ghim
Bài viết được ghim

Độ hot của Langchain
Langchain là một framework vô cùng hot hit trong thời gian gần đây. Nó được sinh ra để tận dụng sức mạnh của các mô hình ngôn ngữ lớn LLM như ChatGPT, LLaMA... để tạo ra các ứng dụng trong thực tế. Dù mới được phát triển cách đây khoảng 6 tháng (10/2022) và vẫn được cập nhật liên tục hàng ngày nhưng trên Github Langchain đã nhận được những tương tác khủng với lượng star lê...

Tất cả bài viết

Tóm tắt Thời gian gần đây, object detection đã có nhiều thay đổi về kiến trúc mô hình và các thành phần trong pipeline để hoạt động hiệu quả và bớt cồng kềnh hơn. Có thể kể đến một số thay đổi như: loại bỏ anchors, sử dụng đầu tách (decoupled head), kiến thức tiềm ẩn (implicit knowledge), các chiến lược gán nhãn (label assignment) ... và loại bỏ thành phần Non-maximum suppression (NMS). NMS có ...

Tổng quan
Dạo một vòng mấy trang chia sẻ kiên thức để chống lười, đập vào mắt mình một bài viết với tiêu đề khá giật tít, mà kiểu nó sẽ áp dụng được trong rất nhiều bài toán. Vì vậy mạn phép đọc bài viết của tác giả sau đó dịch theo ý hiểu để diễn giải cho mọi người cùng thảo luận (Chứ cái này mình không có tự nghĩ ra :v) Bài viết giới thiệu về 1 kỹ thuật mang tên MixNMatch có nguồn gốc từ 1 p...

Lời mở đầu CNN (Convolutional Neural Network) lần đầu được ra mắt và áp dụng vào bài toán Classification (phân loại) là LeNet-5 vào năm 1989 của nhóm nghiên cứu của thầy Yann LeCun. Và với sự ra mắt tiếp đó của AlexNet vào năm 2012, chiến thắng cuộc thi phân loại ảnh ImageNet, CNN đã dần có được sự thống trị của mình trong các bài toán phân loại ảnh. Rất nhiều các kiến trúc CNN mới ra đời như V...
Lời mở đầu Xin chào các bạn. Lâu lắm rồi mình mới quay lại viết một bài viết mới. Nhân dịp Viblo tổ chức sự kiện Mayfest2022, mình xin được chia sẻ một số bài viết về chủ đề Làm gì khi các mô hình học máy thiếu dữ liệu có nhãn. Như chúng ta đã biết, dữ liệu là linh hồn của mọi dự án học máy và sẽ chẳng thể có mô hình nào hoạt động tốt nếu như không có một tập dữ liệu chất lượng cả. Nhưng có một...

Intro
Style transfer là một bài toán thuộc lĩnh vực computer vision nhận được sự chú ý của nhiều nhà nghiên cứu bởi tính ứng dụng cao trong các ứng dụng chỉnh sửa ảnh áp dụng công nghệ AI. Việc huấn luyện một mạng nơ ron để thực hiện style transfer là rất khó khăn bởi vấn đề tìm kiếm dữ liệu. Paper JoJoGAN mà mình sẽ giới thiệu ở đây đã đề xuất một thủ tục để finetune mạng Generator của S...
Xin chào các bạn, hôm nay mình sẽ chia sẻ một bài viết về chủ đề làm sạch dữ liệu, như mọi người cũng biết bước làm sạch dữ liệu cực kì quan trọng trước khi đưa vào phân tích dữ liệu hoặc huấn luyện mô hình. Mình tình cờ đọc được bài viết sử dụng thư viện có sẵn để làm sạch dữ liệu và mình thấy nó khá là hay và còn rút ngắn được thời gian làm sạch dữ liệu. Bây giờ chúng ta cùng nhau tìm hiểu ...
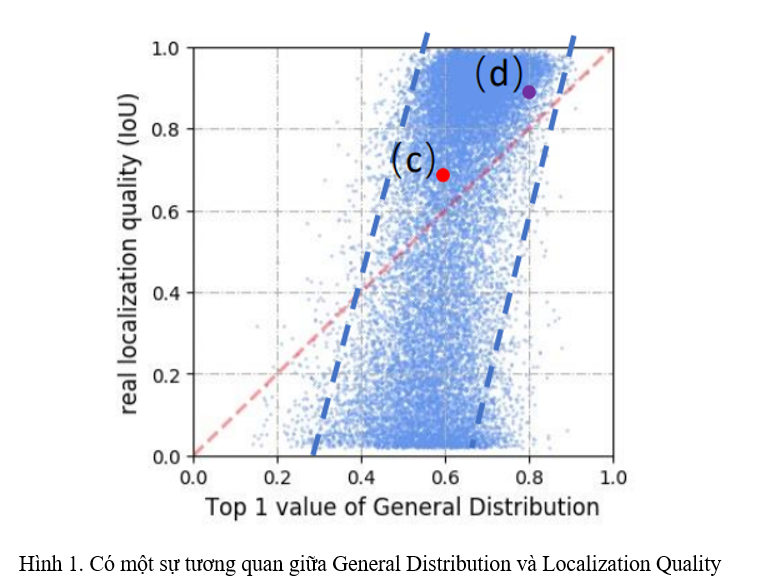
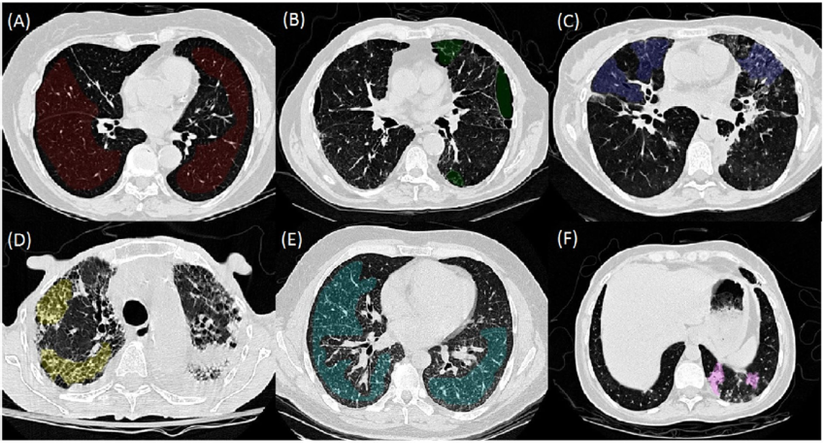
Một số kiến thức cần biết Mình khuyến khích mọi người trước khi đọc bài này thì nên đọc về Generalized Focal Loss hoặc bài phân tích về Generalized Focal Loss (GFL) mà mình đã viết ở đây để có thể hiểu rõ được bài này. Tuy nhiên, mình vẫn sẽ tóm tắt lại các ý chính của GFL ở đây. Trong cấu trúc của các Dense Object Detector thường có 3 đầu ra: đầu ra cho Classification, Localization và một đầu ...
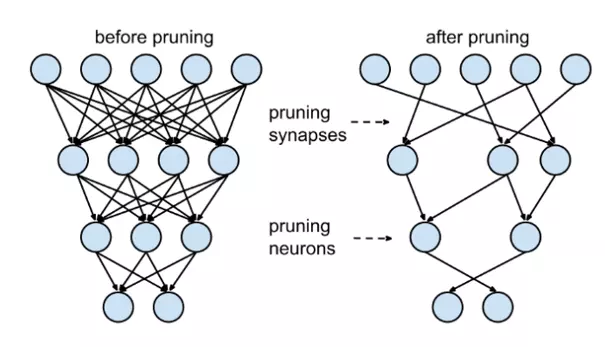
Abstract Tiếp nối chuỗi Series nâng cao kiến thức bản thân về ML, DL, bài viết này mình xin phép chia sẻ một bài viết thuộc chủ để Pruning. Vẫn với lí do lướt Towards Data Science, Medium thì thấy bài viết hay quá nên chia sẻ cùng mọi người
Cùng với việc phát triển mạnh mẽ của công nghệ và dữ liệu đã thúc đẩy Deep Learning ngày càng lớn mạnh với những thành tựu đánh kinh nể, có những bài toán ...
Lời mở đầu Tiếp nối việc phân tích paper, hôm nay mình sẽ cùng các bạn phân tích 1 paper liên quan dến bài toán Semantic Segmentation và phương pháp Contrastive learning. Đường dẫn bài báo gốc mình để ở đây Một số khái niệm cơ bản
- Học tự giám sát (Self-supervised learning): Hiểu đơn giản là ngoài việc sử dụng các nhãn (labels) do chính cong người gán nhãn, mô hình sẽ sử dụng thêm 1 lượng lớn ...

Để một mô hình học máy có thể khái quát hóa tốt, người ta cần đảm bảo rằng các quyết định của nó được hỗ trợ bởi các mẫu có ý nghĩa trong dữ liệu đầu vào. Tuy nhiên, điều kiện tiên quyết là để mô hình có thể tự giải thích, ví dụ: bằng cách làm nổi bật các đặc trưng đầu vào mà nó sử dụng để hỗ trợ dự đoán của nó thông qua một số phương pháp chẳng hạn như Layer-Wise Relevance Propagation. Mặc đã ...
[IMG]
Những nghiên cứu mới xuất hiện mới với tốc độ cực nhanh trong ngành trí tuệ nhân tạo nói chung và thị giác máy tính nói riêng. Nghiên cứu sau dựa trên nghiên cứu trước. Những kỹ thuật được chứng minh là hiệu quả qua nhiều năm khiến chúng ta ít khi nghĩ rằng chúng nên được bỏ đi. Thi thoảng mình cũng hay bắt gặp những bài báo "rethinking" (hay "revisiting")để xem xét lại vấn đề và mình nghĩ đi...
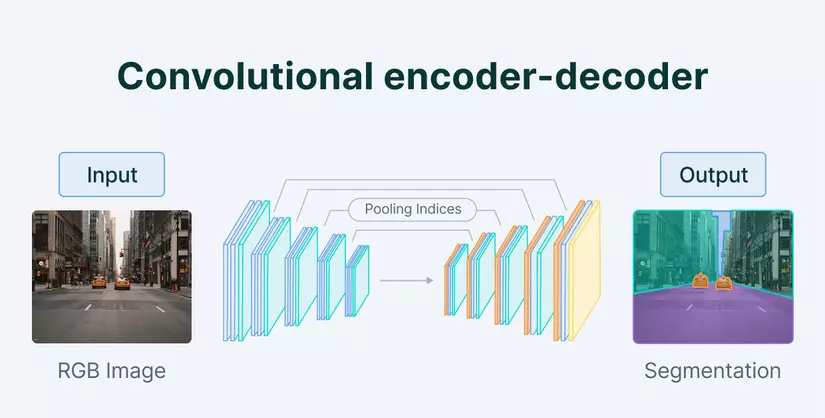
Khai bút đầu xuân bằng cách điểm lại vài kiến thức cơ bản :vvvv
Hẳn những ai làm quen với Machine Learning và AI, và kể cả những người chưa từng tiếp xúc, và cả những người ngoài ngành IT này nữa, đều ít nhiều từng biết đến các AI tự vẽ tranh, tự chơi nhạc, tự viết text, hay nói đúng hơn là tự sinh (generative). trong những năm trở lại đây, các mô hình sinh đã đạt được những bước tiến vô cùng ...
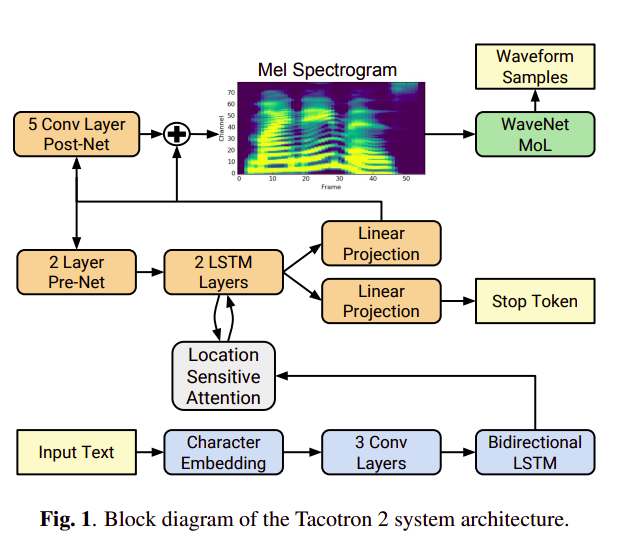
I. Lời mở đầu Tiếp nối chủ đề về kiến trúc Tacotron mà mình đã đề cập với các bạn trong bài viết Tìm hiểu kiến trúc Text2Speech nổi danh một thời -Tacotron (Phần 1), hôm nay chúng ta tìm hiểu một phiên bản lột xác Tacotron2 được đề cập trong bài báo NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS
Tacotron là kiến trúc dạng se...
Tiếp nỗi chuỗi các bài viết về các kiến thức mình tự học để trau dồi kiến thức cho bản thân, hôm nay mình xin giới thiệu tới các bạn một công cụ vô cùng hữu ích trong giới học máy. ONNX thì thực chất trên Viblo đã có một bài viết của tác giả Bùi Quang Mạnh đã nói rất chi tiết ở đây. Tuy nhiên từ khóa về ONNX trên Viblo chưa thực sự có nhiều bài viết bổ trợ, đồng thời mình cũng hay dùng Tensorfl...
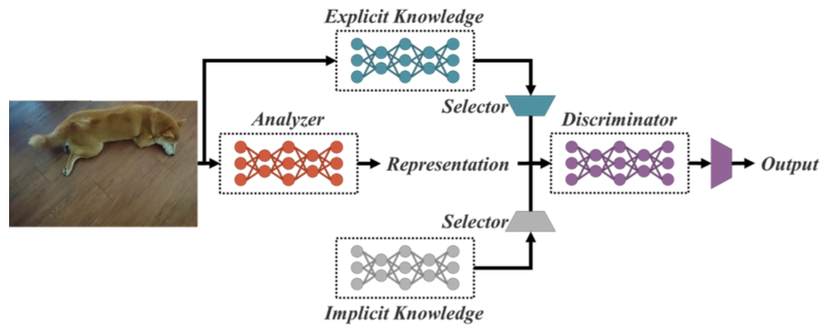
[IMG]
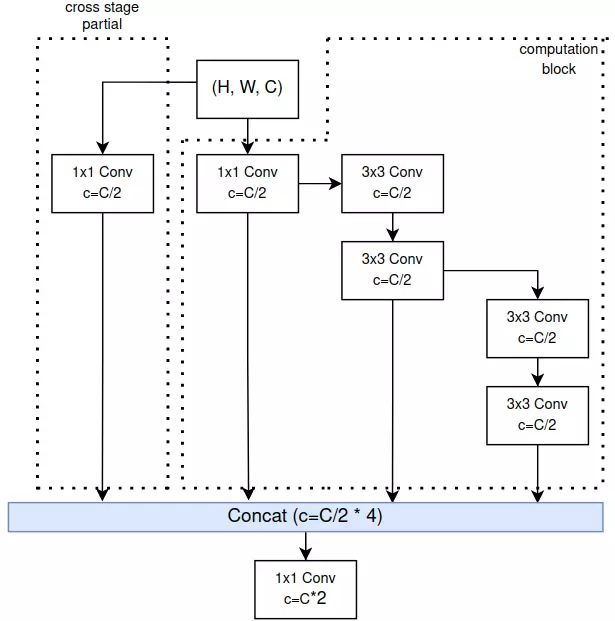
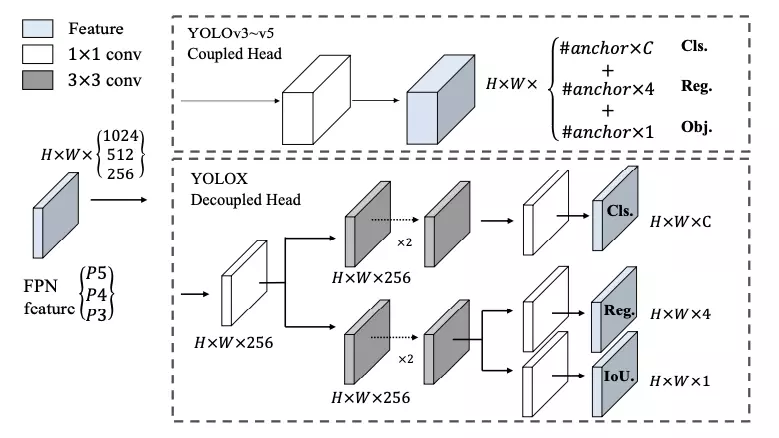
YOLO có lẽ là một trong những họ giải thuật được phát triển nhiều phiên bản nhất trong lĩnh vực trí tuệ nhân tạo. Chúng ta đã có YOLOv1 đến YOLOv5 và mới nhất hiện nay là hai phiên bản YOLOR và YOLOX. Mỗi lần ra một phiên bản YOLO mới, nhiều kỹ thuật SOTA được tích hợp trong đó và thực sự mình cảm thấy học được rất nhiều từ những bài báo này. YOLOR ra mắt năm 2021, trong phiên bản này, YOLOR ...
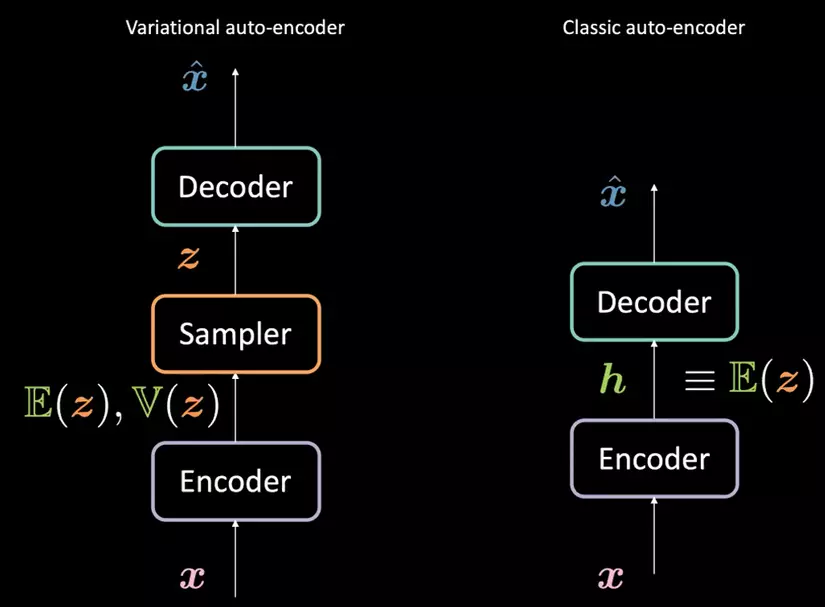
Introduction Xin chào mọi người, trong bài viết ngày hôm này minh sẽ cùng mọi người tìm hiểu về Variational Autoencoder (VAE), một loại generative model trong deep learning. Trong vài năm gần đây, các mô hình generative đang thu hút được sự chú ý của các nhà nghiên cứu và đạt được một số kết quả đáng kinh ngạc trong một số ứng dụng như: super resolution, face generation, ... Một số họ mô hình ...
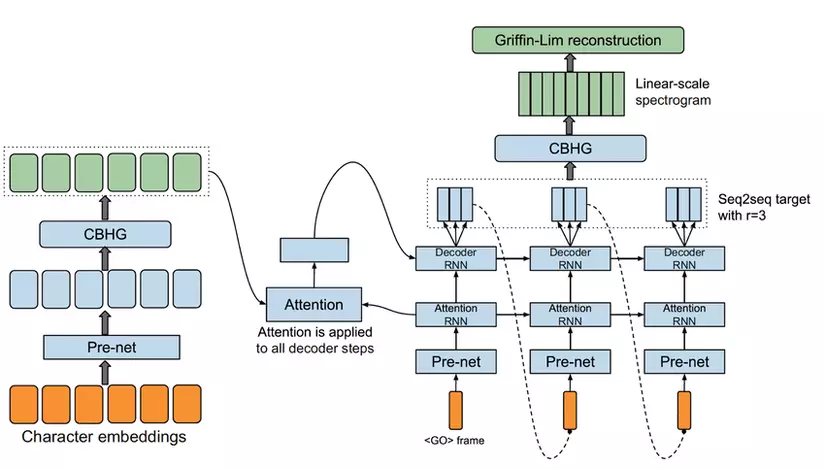
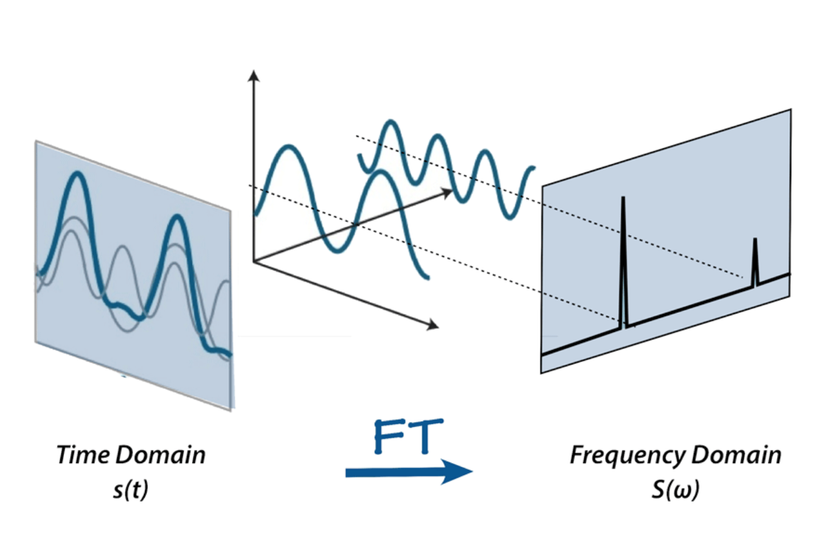
Trong bài Một số kiến thức cơ bản về Text2Speech , mình cùng các bạn đã điểm qua các kiến thức cơ bản về Xử lý giọng nói như cách con người tạo ra âm thanh, các phép toán biến đổi Fourier, ... Hôm nay, mình chia sẻ về một kiến trúc đã từng làm mưa làm gió một thời trong lĩnh vực Text2Speech - Tacotron trong bài báo TACOT...
Xin chào mọi người, chúc mừng năm mới mọi người, chúc mọi người năm mới mạnh khỏe, an khang thịnh vượng.
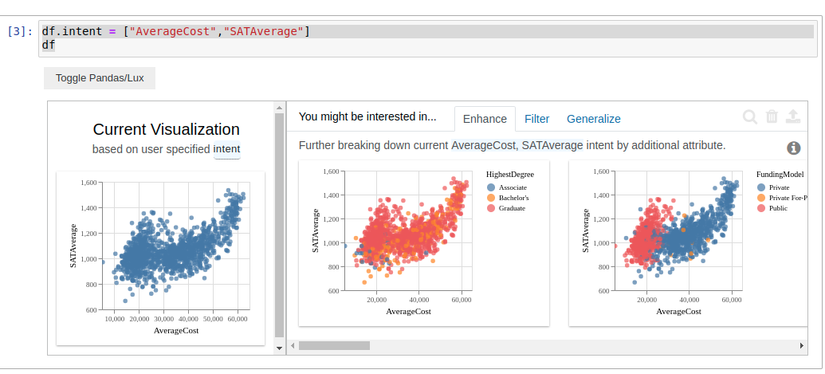
Dữ liệu chứa rất nhiều thông tin chi tiết có ý nghĩa. Phân tích dữ liệu là cách để có được những thông tin chi tiết đó. Đôi khi, chúng ta bối rối trong việc lựa chọn công cụ nào chúng ta muốn sử dụng. Hoặc chúng ta có thể sử dụng một ngôn ngữ lập trình như Python hoặc một số bạn không biết ...
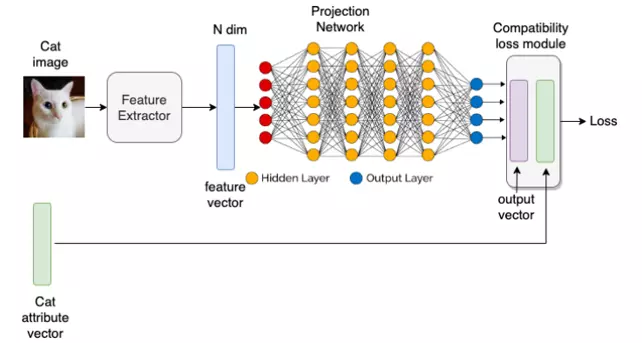
Giới thiệu Trong các bài toán về Face Recognition, chắc hẳn các bạn đã nghe hoặc nên nghe về 1 khái niệm One-shot learning. Mình cũng đã từng làm đồ án môn học về phương pháp này, tương đối hay. Lại là lúc lượn lờ linh tinh, bắt gặp một khai niệm Zero-shot learning. Ủa, tiền thân của One-shot learning hay gì? Vì vậy, song song với việc tìm hiểu xem nó là gì, mình cũng mong muốn chia sẻ cho mọi ...
Hello mọi người. Trước hết, mình xin cảm ơn mọi người vì đã theo dõi những bài viết của mình trong suốt hai năm vừa qua. Nhân dịp đầu xuân năm mới, mình chúc mọi người một năm mới tiền, tài, sức khỏe phát triển mạnh mẽ như em Dần. 😸
Chả là thế này từ ngày bắt đầu hành trình học tập và làm việc với bộ môn ML (viết tắt của Machine Learning mọi người nhé  ) đến nay cũng khoảng 2 năm rưỡi có lẻ,...
) đến nay cũng khoảng 2 năm rưỡi có lẻ,...
