


![]() Bài viết được ghim
Bài viết được ghim

Độ hot của Langchain
Langchain là một framework vô cùng hot hit trong thời gian gần đây. Nó được sinh ra để tận dụng sức mạnh của các mô hình ngôn ngữ lớn LLM như ChatGPT, LLaMA... để tạo ra các ứng dụng trong thực tế. Dù mới được phát triển cách đây khoảng 6 tháng (10/2022) và vẫn được cập nhật liên tục hàng ngày nhưng trên Github Langchain đã nhận được những tương tác khủng với lượng star lê...

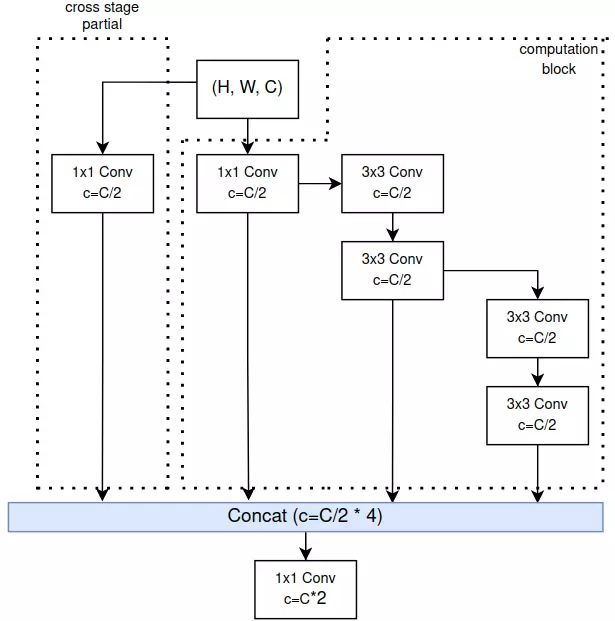
Tất cả bài viết

Trong bài viết trước của mình, mình đã giới thiệu về Hadoop và các thành phần của Hadoop. Hadoop là một hệ sinh thái mã nguồn mở được sử dụng để lưu trữ và xử lý dữ liệu lớn. Nhân tiện một ngày đẹp trời được giao task setup multi node cluster để làm 1 số công việc trên công ty, mình viết luôn một bài coi như node lại quá trình cài đặt cũng như kiểm thử về multi node cluster trong Hadoop.
Việc ...

<img src="https://images.viblo.asia/0c976705-3d65-4272-8779-0972e528987c.png" >
Figure 1. Eager Execution vs. Graph Execution <br>
(https://towardsdatascience.com/eager-execution-vs-graph-execution-which-is-better-38162ea4dbf6)
Tensorflow là một nền tảng hỗ trợ cho việc học máy từ việc tải, xử lý dữ liệu đến huấn luyện, triển khai mô hình cùng vô vàn tác vụ khác.
Tensorflow...

Lời mở đầu
Có lẽ thời gian chỉ trong vòng vài tháng trở lại đây, thế giới công nghệ đã bị khuynh đảo bởi các mô hình AI như ChatGPT, GPT-4, DALLE-2, Midjourney... Các mô hình AI đã thực sự tạo được cho người dùng những cảm xúc wow và có thể thấy rằng đâu đâu cũng nói về nó. Có phải kỉ nguyên mới của AI có phải đã bắt đầu rồi không? Bản thân mình nghĩ là CÓ. NÓ THỰC SỰ ĐÃ BÁT ĐẦU. Và chúng ta,...
Lời mở đầu
Xin chào các bạn, có lẽ gần đây thế giới công nghệ không khỏi choáng ngợp trước tần suất ra mắt của các sản phẩm AI từ ChatGPT, GPT-4 và gần đây nhất là vào ngày 1/4, Elon Musk và Twitter đã quyết định open source một phần của hệ thống gợi ý trên nền tảng Twitter tại đây và tại đây. Và mới chỉ sau hai ngày, repo này đã đạt được 38000 star trên Github đủ để thấy sức nóng của nó lớn đ...

Diffusion Models đang dần phổ biến. Nhiều trường đại học và khóa học đã đưa Diffusion Models vào chương trình giảng dạy. Mình viết bài này với hy vọng bài viết này sẽ có ích phần nào với các bạn muốn tìm hiểu về Diffusion Models.
Một số từ tạm dịch
- Diffusion: khuếch tán
- Quasi-static process: quá trình chuẩn tĩnh
- Thermodynamic Equilibrium: cân bằng nhiệt động học (NĐH)
- Forward Diffusion...

Ở nội dung các bài viết trước, mình có giới thiệu qua về nội dung khóa học Data Science Fundamental và Data Analytics Fundamental để làm những bước đệm cho việc học về Data Science nói chung. Chắc hẳn nếu bạn có bạn bè làm về Data Science (Data Engineer, Data Scientist, ..) thì các cái tên Hadoop, Spark, ... được nhắc lại nhiều lần và bạn có thể giống mình sẽ tự hỏi: Nó là gì? Mình có tìm các k...

Tóm tắt Ảnh là gì và làm thế nào để trích xuất features? Convolutional Neural Network (CNN). CNN xem ảnh là các pixel có tổ chức theo dạng hình chữ nhật và thực hiện trích xuất features sử dụng phép Convolution ở một vùng cục bộ. Vision Transformer (ViT). ViT xem ảnh là một chuỗi các patch và thực hiện trích xuất features sử dụng phép Self-Attention ở khoảng cách toàn ảnh.
Và bài này sẽ giới t...

Chào các bạn, như các bạn cũng biết xác suất thống kê khá là quan trọng trong Xử lý dữ liệu (data analysis) cũng như khoa học dữ liệu (data Science) vì nó giúp chúng ta hiểu rõ hơn về dữ liệu mình có. Và mình dạo này khá là rảnh rỗi nên học lại kiến thức xác suất thống kê và đây là bài viết đầu tiên trong chuỗi Series Xác suất thống kê với python . Chúng ta cùng bắt đầu thôi nhé.
Mean, Median...

Chào mọi người, dạo gần đây mình có thời gian nên tìm hiểu bài bản vể việc học DA từ đầu nên bắt đầu như thế nào, Vì vậy hôm nay mình cũng viết bài chia sẻ những gì mình đã tìm hiểu trong thời gian vừa qua.
Để trở thành một nhà phân tích dữ liệu thì chúng ta cần học và có những kỹ năng sau:
Kiến thức về Data, Database Muốn phân tích được data thì việc hiểu data là gì rất là quan trọng,Data (...

Kết thúc khóa học Data analytics cho người mới bắt đầu, bài viết này của mình sẽ bao gồm 2 nội dung chính: Phương pháp luận trong Data Science và Data Analytics trong các lĩnh vực khác nhau sẽ có hiệu quả thế nào. Cùng mình trao đổi nhé Data Science methodology Phương pháp luận trong Data Science là phương pháp khoa học dữ liệu để thúc đẩy những thông tin, hiểu biết có ý nghĩa hơn. Bản chất thì...

Sự háo hức chờ đón GPT-4
Có lẽ chưa một năm nào mà chứng kiến sự vươn lên ngoạn mục của AI trong lòng công chúng như năm nay. Không thể phủ nhận rằng OpenAI đã làm quá tốt trong việc đưa AI đến với mọi người, mọi nhà. Đâu đâu cũng nghe về ChatGPT, về Midjourney, blah blah... Và cũng không để cho dân tình phải chờ đợi lâu thì ngày 14/3/2023, phiên bản nâng cấp thực sự của GPT-3 đã được công bố ...

Tiếp nối trong phần đầu tiên về các khái niệm cơ bản của Data Analytics, trong phần này, mình sẽ tập trung về các kiểu dữ liệu, levels của dữ liệu và tổng quan trực quan hóa dữ liệu, mỗi kiểu trực quan sẽ phù hợp với từng kiểu dữ liệu và mục đích khác nhau. Mời các bạn đọc cùng trao đổi nhé Một số thuật ngữ, thông số trong thống kê và Data Analytics Trước hết mình sẽ điểm qua một vài từ khóa cơ...

Lời mở đầu Thời gian này, do một vài lý do nên mình đang học về Data Science, vì vậy những bài viết trong thời gian này sẽ xoay quanh chủ để này. Trong các khóa học online, thì mình đang học dở về khóa "Learn data analytics for beginners" của SkillUp. Khóa này theo mình đánh giá tương đối hay, cho cái nhìn overview về Data analytics. Trong bài viết này, mình sẽ note lại để trao đổi cùng các bạn...

Tiếp nối series Data Science với các bài học đầu tiên về các khái niệm, kiến thức cơ bản, trong bài viết hôm nay, chúng ta sẽ cùng nhau phân biệt giữa Database, Data warehouse và Data lake.
Database Đây chắc hẳn là một khái niệm khá quen thuộc đối với các bạn IT.
- Database (cơ sở dữ liệu) là một bộ sưu tập dữ liệu được tổ chức bày bản và thường được truy cập từ hệ thống máy tính hoặc tồn tại ...

Data Science là cái tên có lẽ không còn quá xa lạ với mọi người. Một lĩnh vực lớn làm việc với Data mà chắc hẳn rất nhiều người tò mò. Đang đứng ở công việc với AI, thì cứ nghĩ là mình đang tìm hiểu một lĩnh vực mới, nhưng xem xét lại mới thấy mình cũng là 1 phần của Data Science. Với mong muốn cùng tìm hiểu, chia sẻ, trao đổi và trau dồi kiến thức trên nền tảng Viblo, mình xin phép chia sẻ bài...
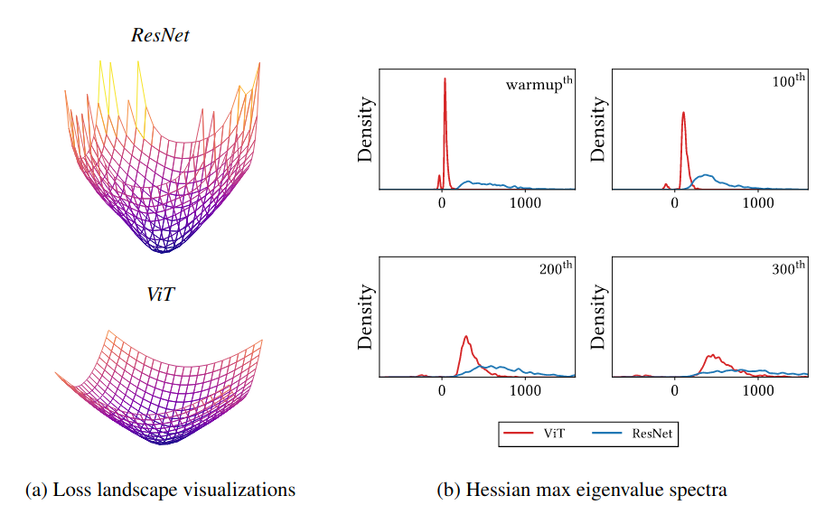
Mở đầu Qua 2 bài viết: cơ chế Attention trong Computer Vision và MetaFormer với cái tiêu đề đầy chế giễu, thì giống như mình là một hater của Self-Attention. Thì đúng là mình có một chút gì đó không thích Self-Attention thật (vì nó nặng, và mình thì thích những thứ gì nhanh và nhẹ) nhưng dù sao thì mình vẫn phải tìm hiểu nó thôi :v
Nên là hôm này mình sẽ trình bày một chút kiến thức của mình v...

Trong thời gian gần đây, các mô hình Generative AI chẳng hạn như ChatGPT có tần xuất vô cùng dày đặc trên tất các các phương tiện truyền thông. Mặc dù khá dễ dàng để có thể liệt kê các nhược điểm cố hữu chẳng hạn như có tính tin cậy không được đảm bảo được đề cập đến trong ChatGPT hay là "Chết GPT"?, ta khó có thể phủ nhận rằng các mô hình này có thể giảm thiểu rất nhiều thời gian và công sức n...
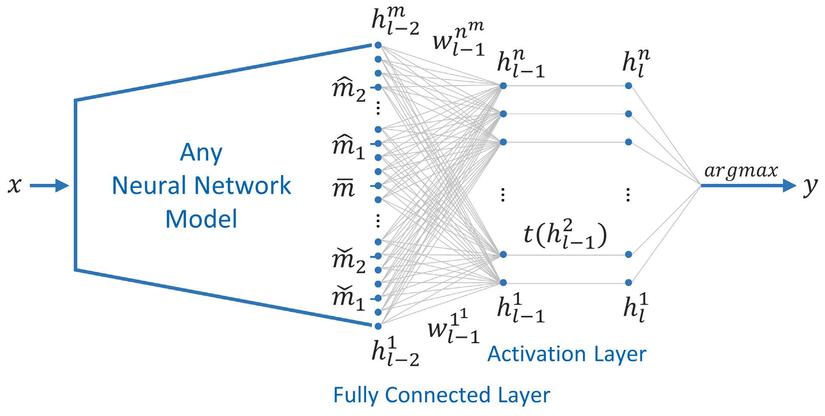
- Bài toán Open-Set Recognition
Thông thường, với các bài toán classification, ta thường hay train một mô hình học máy học có giám sát trên một bộ training set với số lượng class nhất định và test mô hình đó trên một bộ test set có cùng các class với bộ đã được dùng để train. Khi đó, model sẽ chỉ thực hiện được task Closed-Set Recognition, nghĩa là classify một input vào một trong những class...

Những ngày qua ChatGPT có thể nói đã dấy lên một làn sóng thảo luận mạnh mẽ trong xã hội, không chỉ dừng lại trong cộng đồng IT. Người ta nói về nguy cơ robot/ trí tuệ nhân tạo thay thế con người nhiều hơn bao giờ hết. Tuy nhiên mình nghĩ chúng ta nên quan tâm nhiều hơn đến việc làm thế nào để sử dụng ChatGPT (cũng như các mô hình GPT) như một công cụ hỗ trợ để tối ưu hóa năng suất làm việc, cũ...

Cảnh báo
Bài viết này chỉ là quan điểm cá nhân của mình về ChatGPT - một ứng dụng AI sốt sình sịch trong thời gian gần đây. Tuy nhiên, bài viết này sẽ có cả những luận điểm không vừa tai về nó. Chống chỉ định với các Fan cuồng ChatGPT hay hội các nhà tư tưởng đang mơ mộng về một tương lai AI có thể thay thế con người.
Cha đẻ của ChatGPT là ai?
Có lẽ trong những ngày gần đây ChatGPT là một cụ...
