
[Paper Explain] EfficientFormer: Vision Transformers at MobileNet Speed
Bài đăng này đã không được cập nhật trong 3 năm
I. Mở Đầu:
Mô hình transformer là một mô hình cực kỳ nổi tiếng trong lĩnh vực NLP, và một năm trở lại đây nó đã được đưa qua lĩnh vực computer vision và được nghiên cứu cực kỳ phổ biến nhưng một điểm yếu của nó là cực kỳ nặng và có độ chễ cao. Với điểm yếu này thì cực kỳ khó để có thể triển khai trên các thiết bị có cấu hình phần cứng yếu như mobile phone. Paper hôm nay sẽ giúp giải quyết vấn đề về độ chễ cao của mô hình bằng việc phân tích và cải tiến từng thành phần trong mạng, giúp cho tăng thời gian inference được tăng cao mà vẫn giữ được hiệu suất đáng gờm của transformer.
II. Đặt vấn đề:
Tác giả đã sử dụng iphone 12 làm ML core và đánh giá tốc độ của các mô hình CNN và ViT-based models theo từng thành phần trong mạng.
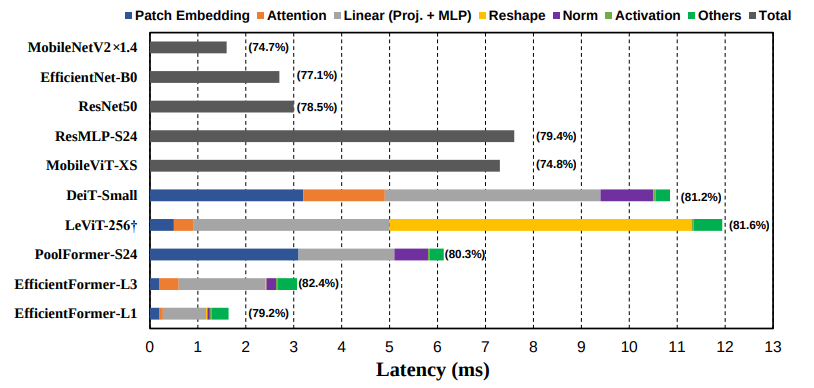
Theo thực nghiệm và đo đạc giữa các mô hình với nhau, tác giả có xác định được 3 vấn đề chính (thực ra là 4 nhưng cái cuối ko quan trọng lắm :>>) làm ảnh hưởng tới độ chễ của mô hình như sau.
Vấn đề 1: Patch embedding với kernel size và stride lớn làm nghẽn tốc độ của model.
Cách patch embedding thông thường sẽ sử dụng một kernel size và stride lớn với việc non-overlapped. Như vậy sẽ xảy ra 2 điểm yếu chính là:
- Các kernel size và stride lớn sẽ không được hỗ trợ tốt bởi các compiler và không thể tăng tốc qua các thuật toán ví dụ như Winograd. Như có thể thấy ở biểu đồ bên trên thì 2 model PoolFormer và DeiT-Small có độ chễ thời gian ở phần xử lý patch embedding là cao nhất (Nhưng có một bạn đồng nghiệp của mình đã thử nghiệm và cho thấy PE của PoolFormer thậm chí vấn nhanh hơn của EfficientFormer, các bạn có thể xem ở đây) Khá là khó hỉu =))
- Điểm yếu thứ 2 là việc patch embedding cũ không overlapped các patch với nhau, điều này làm cho việc liên kết giữa các patch kém hơn.
Vậy nên trong paper thay vì sử dụng một kernel size và stride lớn tác giả đã sử dụng kernel 3x3 và stride là 2.
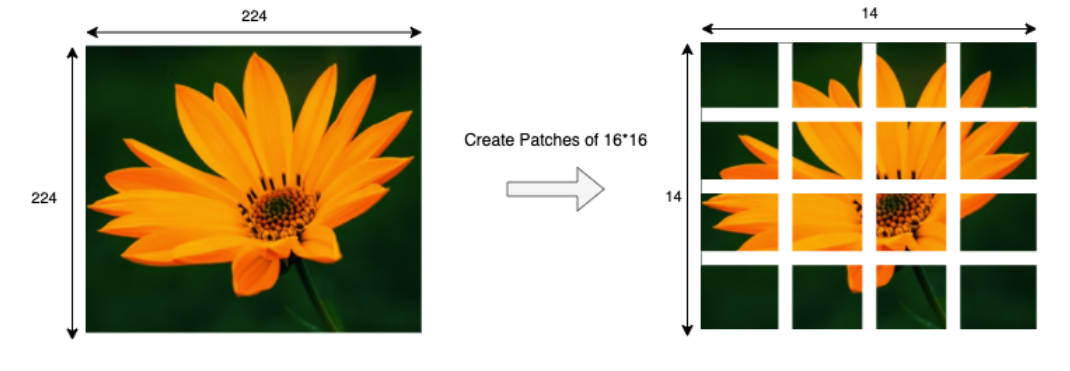
Node: Cho những bạn nào chưa rõ thì việc chia ảnh thành patch embedding chẳng khác gì một phép convolution vậy nên ta sẽ tận dụng luôn phép conv để tạo patch embedding. Và việc overlapped chính là hành động kernel trượt trên ảnh chồng chéo lên nhau và non-overlapped ngược lại.
Vấn đề 2: Việc reshape thường xuyên sẽ làm chậm mô hình.
Mọi người thường lầm tưởng rằng việc mô hình bị chậm là do cơ chế multi head self-attention (MHSA). Thế nhưng thực tế thử nghiệm cho thấy rằng chính việc sử dụng quá nhiều phép reshape khiến cho mô hình chậm đi, có thể thấy như ở mô hình LeViT-256. Vậy thì tại sao lại sử dụng nhiều phép reshape đến như vậy?
Mô hình LeViT được xây dựng chủ yếu trên Conv với đầu vào là 4D tensor (Batch_sizes, Channels, Height, Weight) trong khi đó MHSA lại nhận đầu vào là một 3D tensor (Batch_sizes, Height x Weight, Channels) do đó mỗi khi chuyển output từ Conv sang MHSA và ngược lại là chúng ta lại phải reshape một lần. Như vậy có thể thấy rằng việc cấu trúc mô hình xen kẽ giữa Conv và MHSA là không phù hợp.
Vấn đề 3: Sử dụng Conv-BN sẽ nhanh hơn LN (GN)-Linear.
Thông thường khi thiết kế layer tổng hợp thông tin MLP sẽ có 2 cách:
- Sử dụng LayerNorm (LN) và 3D Linear projection (proj)
- Sử dụng Conv 1x1 và BatchNorm (BN)
Về việc sử dụng LN - proj sẽ cho độ chính xác cao hơn nhưng thời gia inference kém hơn việc sử dụng Conv 1x1 - BN. Vậy nên ở những block Conv 4D tác giả quyết định xử dụng Conv 1x1 - BN để tối ưu hóa thời gian và ở block MHSA 3D tác giả sẽ sử dụng LN - proj để giữ nguyên được kiến trúc ViT và tối ưu hóa được accuracy.
Để rõ hơn việc tại sao sử dụng Conv 1x1 - BN lại cho thời gian inference nhanh hơn LN - proj thì các bạn có thể đọc bài RepVGG của bạn Bùi Quang Mạnh. Về cơ bản thì trong quá trình inference, sẽ không sử dụng 2 layer riêng biện là Conv-BN như lúc training nữa, mà 2 layer này nó sẽ được fusion lại thành một Conv duy nhất theo kỹ thuật re-parameterization.
III. Kiến trúc mô hình:
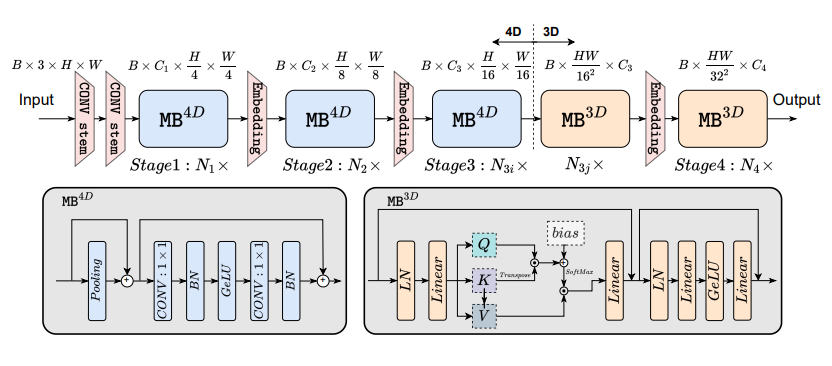
Mô hình có các thành phần chính gồm:
- Conv stem
- Embedding
- Meta block 4D (MB 4D)
- Meta block 3D (MB 3D)
Conv stem:
Thay vì sử dụng một kernel size 7x7 và stride 4 như các phương pháp patch embedding thông thường, thì tác giả chỉ cần sử dụng 2 lần conv 3x3 stride 2 tương đương để lấy được patch embedding mà trong khi số lượng tham số ít hơn và ưu điểm đã được đề cập ở vấn đề 1.

Đầu vào sẽ có kích thương (B, C, H, W) và đầu ra của 2 lần conv stem sẽ là (B, C, , )
Embedding: Thực chất cũng gần giống một layer conv stem, module này có tác dụng downsampling của output giữa các block trước đó xuống một nửa và làm input cho block phía sau. Điều này tạo cho mạng có kiến trúc Hierarchical nó giúp tăng effective resceptive field của model.
Meta block 4D: Đầu vào của MB 4D là (B, C, , ) trong quá trình tính toán block này kích thước của channels C sẽ thay đổi nhưng kích thước của chiều rộng và cao của features vẫn được giữ nguyên. Một block Conv cơ bản, không có gì đặc biệt.
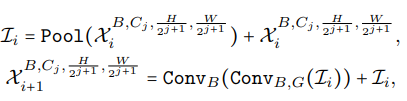
- : Conv + BN
- : Conv + BN + GeLU Activation
Meta block 3D: Tại đây, sau khi việc xử lý đã hoàn thành tại các block Conv 4D rẽ tiến hành reshape một lần duy nhất để chuyển đồi 4D input (B, C, , ) thành (B, , C). Ở đây sẽ là số lượng patch embedding và C là dimensional của patch embedding.
Nếu bạn đọc Vision transformer rồi thì nó chính là input đầu vào của mô hình ViT sau khi qua flatten - linear projection.
IV. Code:
-
Conv stem:
Ở đây khởi tạo 2 layers conv đều có kích thước kernel, stride và padding là như nhau, mỗi layer sẽ downsampling kích thước đầu vào đi một nửa.
def stem(in_chs, out_chs):
return nn.Sequential(
nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs // 2),
nn.ReLU(),
nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs),
nn.ReLU(), )
-
Embedding:
Ở đây embedding giúp downsampling kích thước của features xuống một nửa so với output của layer trước đó, điều này giúp cho mô hình có được kiến trúc Hierarchical tăng khả năng learning của model. Thiết kế này tương tự với kiến trúc phổ biến ở CNN.
Kích thước của conv layer được khởi tạo với kernel_size = 3, stride = 2, padding = 1, và norm layer ở đây chính là Batch Normalization.
class Embedding(nn.Module):
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2d):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
-
Multi-layers perceptron:
Với mlp truyền thống sẽ được triển khai bằng phép linear + layerNorm, nhưng nhận thấy rằng việc triển khai phép conv với kernel = 1, stride = 1 kế hợp với batchNorm tương đương với phép mlp truyền thống, trong khi hiệu xuất không giảm đi quá nhiều mà tốc độ được cải thiện từ 10-20%.
Ở đây mlp được triển khai với 2 layers conv với kernel = 1, stride = 1+ batchNorm.
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.norm1 = nn.BatchNorm2d(hidden_features)
self.norm2 = nn.BatchNorm2d(out_features)
def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.norm2(x)
x = self.drop(x)
return x
-
Meta Block 4D:
Ở block này khá đơn giản, khi input được đưa qua token mixer là average pooling rồi sau đó đưa tiếp qua mlp layers kết hợp thêm với skip-connection. Kiến trúc của block này chính là của kiến trúc PoolFormer của paper mataFormer. Các bạn có thể đọc thêm về metaFormer, đây là một paper giúp các bạn có thể thỏa sức tạo ra các ViT-based models miễn là các bạn có đủ resource để thử nghiệm 
class Meta4D(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.token_mixer = Pooling(pool_size=pool_size)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(x))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(x))
else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x))
return x
-
Meta Block 3D:
Tại block này token mixer xử dụng sẽ là Multi head self-attention và mlp layer ở đây sẽ sử dụng Linear layers thay vì conv như mlp layer ở MB 4D block, và lý do tại sao sử dụng Linear layers thì ở đây tác giả muốn giữ nguyên hiệu suất của thiết kế MHSA gốc và latency cũng không bị tăng lên quá nhiều.
class Meta3D(nn.Module):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Attention(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = LinearMlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(0).unsqueeze(0)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(0).unsqueeze(0)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
Để tham khảo full source code các bạn có thể truy cập tại: EfficientFormer
V. Thực nghiệm:
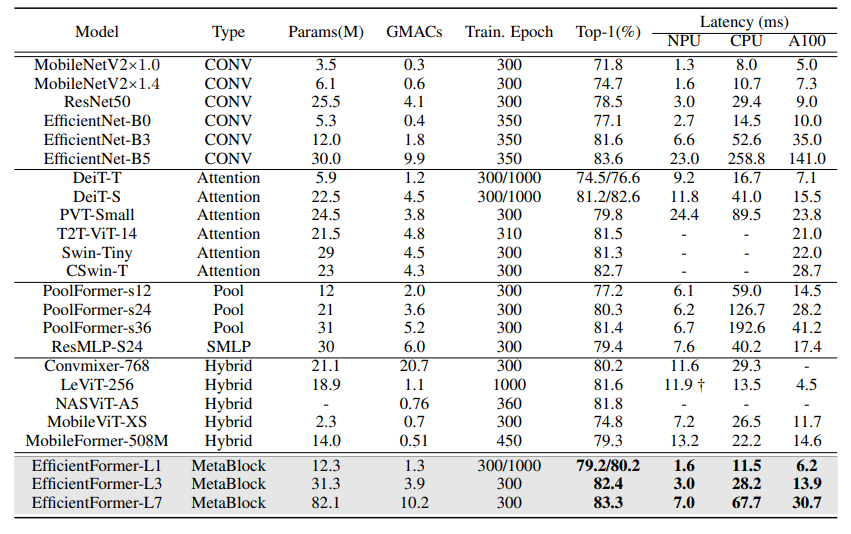
Như có thể thấy thì EfficientFormer đã outperform đc hầu hết các mạng ViT-based model hiện tại và thời gian inference của nó cũng đáng kinh ngạc. Như có thể thấy thì EfficientFormer-L1 có latency chỉ cao hơn mobileNetv2 một chút nhưng acc của nó đã outperform hoàn toàn. Nhưng có một điểm yếu là số lượng param của nó vẫn khá lớn, điều này đã được cải thiện ở mô hình EfficientFormerv2. Mình sẽ explain paper EfficientFormerv2 trong thời gian tới.
VI. Lời kết:
Thực sự thì kiến trúc của transformer nó đã quá mạnh trong NLP, từ khi nó được mang sang computer vision thì nó thực sự outperform gần như hoàn toàn các mạng CNN truyền thống, nhược điểm duy nhất của transformer chắc có lẽ là ở tốc độ, đây cũng là trở ngại rất lớn để có thể đưa được transformer lên các thiết bị mobile vốn dĩ có cấu hình hạn chế, nhưng nó cũng đã và đang được cải tiến từng ngày. Rất mong bài viết mang lại nhiều thông tin hữu ích cho mọi người ^^.
VII. Tài liệu tham khảo:
1. EfficientFormer: Vision Transformers at MobileNetSpeed
All rights reserved
