
SENATOR – Hành Trình Tìm và Vá Lỗ Hổng Kiến Thức Cho LLM
Dùng LLM để “chém gió” thì ổn, nhưng khi chuyển sang các lĩnh vực chuyên sâu như y khoa, tài chính hay nghiên cứu khoa học, model vẫn thường trả lời thiếu chính xác hoặc thậm chí sai lệch. Nguyên nhân chính là dù đã được pre‑train trên khối lượng dữ liệu khổng lồ, mô hình vẫn chưa nắm vững những mối liên hệ chuyên môn phức tạp. Kết quả là hallucination – tức chém bừa không có căn cứ – vẫn diễn ra, và trong nhiều trường hợp, “sai một li” thôi cũng có thể gây hậu quả nghiêm trọng. Thay vì blind fine‑tune hay nhồi thêm dữ liệu đại trà, SENATOR (Structural Entropy‑guided Knowledge Navigator) được sinh ra để giúp LLM tự “tự kiểm tra, tự vá” lỗ hổng kiến thức một cách có hệ thống.
Kiến trúc SENATOR
Để xử lý các vấn đề trên, team nghiên cứu đề xuất SENATOR (Structural Entropy-guided Knowledge Navigator). Framework này làm hai việc chính: tìm lỗ hổng kiến thức và vá lỗ hổng đó. Khác với các cách cũ (kiểu fine-tune bừa hoặc nhồi thêm dữ liệu thừa thãi), SENATOR đi đúng trọng tâm, dùng Monte Carlo Tree Search (MCTS) kết hợp với knowledge graph để scan xem llm yếu chỗ nào, rồi tạo dữ liệu siêu targeted để sửa đúng chỗ đó.
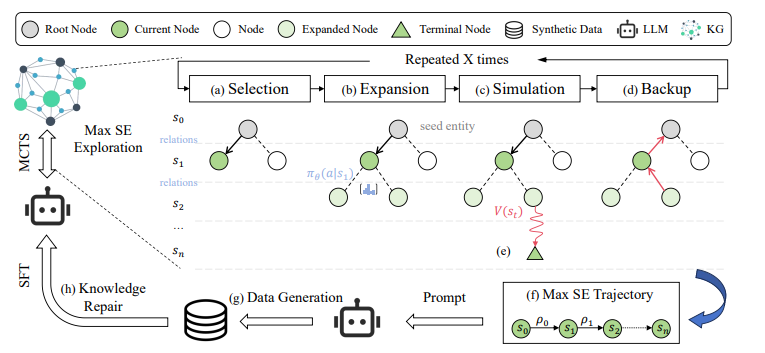
Hình 1: Sơ đồ tổng quan kiến trúc SENATOR, bao gồm các thành phần KG → MCTS → SE → Synthetic Data → Fine‑tuning.
BƯỚC 1: TÌM LỖ HỔNG
SENATOR phát hiện lỗ hổng kiến thức của mô hình thông qua ba cơ chế kết hợp. Đầu tiên là đo độ bất định (uncertainty). Mỗi triplet trong knowledge graph được chuyển thành một câu cloze — một câu có chỗ trống buộc mô hình phải điền vào từ còn thiếu. Ví dụ: “Thuốc Imatinib gây tác dụng phụ là ." Mô hình cần dự đoán đúng từ, trong trường hợp này là “nausea” (buồn nôn). Sau đó, SENATOR tính độ ngạc nhiên của mô hình bằng công thức self-information: , trong đó là xác suất mô hình gán cho từ đúng. Nếu xác suất này thấp, self-information sẽ cao, biểu thị rằng mô hình đang không chắc chắn — đây là một dấu hiệu cảnh báo về lỗ hổng kiến thức.
Kế đến, SENATOR sử dụng Structural Entropy (SE) để đánh giá mức độ hiểu biết của mô hình đối với các chuỗi kiến thức liên kết trong KG. Không chỉ xét các triplet riêng lẻ, SENATOR phân tích các đoạn nối dài như: Imatinib → causes_side_effect → nausea → treated_by → antiemetic drugs. Đây là một chuỗi logic trong không gian kiến thức, và nếu SE của chuỗi này cao, điều đó cho thấy mô hình đang thiếu hiểu biết trên toàn bộ đoạn. Ngược lại, nếu SE thấp thì chuỗi đã được học tốt và không cần can thiệp.
Cuối cùng, để tối ưu việc dò tìm lỗ hổng, SENATOR sử dụng Monte Carlo Tree Search (MCTS) thay vì quét toàn bộ KG. MCTS giúp khám phá hiệu quả các vùng kiến thức đáng nghi. Thuật toán hoạt động bằng cách chọn các node theo chiến lược PUCT (kết hợp giữa dự đoán và độ tin cậy), mở rộng các nhánh liên quan, đánh giá phần thưởng (reward) để xác định mức độ thiếu hụt kiến thức, rồi lan truyền ngược lại thông tin để cập nhật các node tổ tiên. Chẳng hạn, khi một mô hình y khoa được hỏi về gene BRCA1 và trả lời đúng một phần, nhưng lại lúng túng khi nói về cơ chế sửa chữa DNA liên quan, SENATOR có thể phát hiện điểm yếu ở liên kết “BRCA1 → sửa DNA” và đánh dấu vùng đó để đào tạo lại.
BƯỚC 2: VÁ LỖ HỔNG
Sau khi đã định vị được các vùng kiến thức mà mô hình chưa nắm vững, SENATOR chuyển sang bước vá lỗ hổng bằng cách sinh dữ liệu huấn luyện nhân tạo (synthetic QA) một cách có kiểm soát. Các câu hỏi – trả lời được tạo ra nhằm nhắm chính xác vào vùng yếu, giúp mô hình học lại đúng nội dung cần thiết mà không bị nhiễu bởi các thông tin không liên quan. Ví dụ, nếu phát hiện mô hình không hiểu rõ vai trò của BRCA1 trong sửa chữa DNA, SENATOR sẽ sinh ra một QA như: “BRCA1 ảnh hưởng thế nào đến cơ chế sửa chữa DNA trong ung thư vú?” với câu trả lời tương ứng: “BRCA1 giúp sửa chữa đứt gãy sợi đôi DNA bằng cách điều phối protein RAD51…” Chất lượng dữ liệu được kiểm soát chặt:
- Format: Câu hỏi và trả lời phải rõ ràng, không mập mờ.
- Logic: Phải có logic rõ ràng, không được chém.
- No hallucination: Mọi thông tin phải có trong KG, không được tự bịa.
Điểm mạnh của SENATOR là kiểm soát chất lượng dữ liệu sinh ra một cách chặt chẽ. Nội dung phải có định dạng rõ ràng, logic mạch lạc và quan trọng nhất là dựa trên tri thức thực có trong knowledge graph — tuyệt đối không được bịa đặt (hallucination). Sau khi hoàn tất bộ QA này, mô hình sẽ được huấn luyện lại bằng phương pháp supervised fine-tuning (SFT), giúp cập nhật kiến thức đúng vào những vị trí còn thiếu, tối ưu hóa hiệu quả học mà không cần phải huấn luyện lại toàn bộ mô hình.
KẾT QUẢ THỰC TẾ
Team nghiên cứu test SENATOR trên LLaMA-3 và Qwen2, dùng các benchmark y khoa như MedQA, MedMCQA, PubMedQA, GPQA, MMLU. Kết quả ngon hơn cả mong đợi: • Hiệu quả: Model cải thiện rõ rệt trên các subdomain y khoa. Một heatmap trong paper cho thấy khi tăng tỷ lệ synthetic data, độ chính xác tăng đều trên các chủ đề, từ nội khoa tới di truyền học. • Phân bố dữ liệu: Synthetic data của SENATOR mở rộng vùng phủ kiến thức so với dữ liệu pretraining. PCA visualization cho thấy dữ liệu mới (màu đỏ) bổ sung đúng những chỗ benchmark (màu xanh) còn thiếu. • Chuyển giao kiến thức: Đỉnh nhất là synthetic data từ lỗ hổng của model này có thể dùng để cải thiện model khác. Ví dụ, tui thấy họ test swap dữ liệu giữa LLaMA-3 và Qwen2, cả hai đều ngon hơn, chứng tỏ nhiều lỗ hổng là do bản chất domain, không phải model-specific.
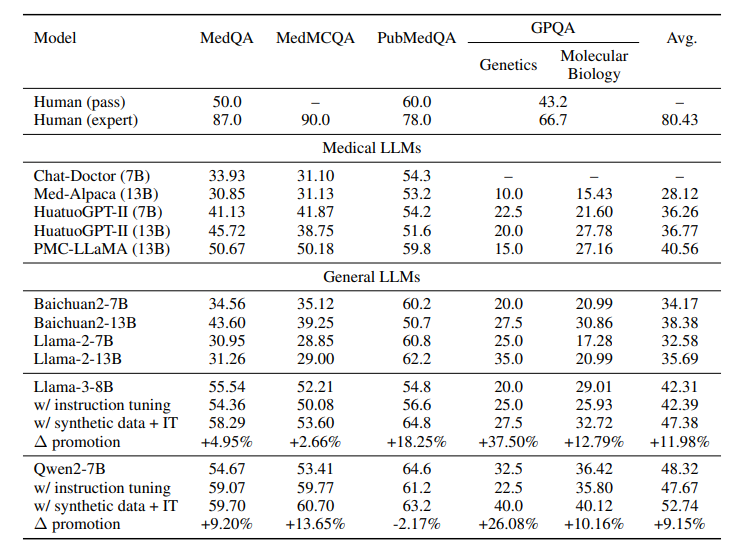
Hình 2: Kết quả đánh giá SENATOR
Ứng dụng
Y khoa
Khi hỏi model về cơ chế tác dụng của gene BRCA1 trong ung thư vú, LLM có thể chỉ biết sơ sơ hoặc bỏ sót phần liên kết với protein sửa chữa DNA. SENATOR sẽ phát hiện path này thiếu kiến thức, sinh loạt câu hỏi như “BRCA1 ảnh hưởng thế nào đến quá trình sửa chữa DNA?” kèm đáp án chi tiết, giúp model sau khi fine‑tune trả lời đầy đủ và chính xác hơn.
Nghiên cứu hóa sinh
Trong KG phản ứng enzyme–substrate, nếu model lơ mơ cơ chế xúc tác của một enzyme X, SENATOR sẽ khoanh vùng, rồi tạo QA pairs yêu cầu “Mô tả bước 2 trong cơ chế xúc tác của enzyme X” với đáp án đúng. Sau khi fine‑tune, LLM có thể hỗ trợ mô phỏng phản ứng một cách chi tiết.
Luật pháp & Tài chính
Với KG điều luật – án lệ, framework này có thể tìm ra chỗ model hiểu sai quy định, rồi sinh case study targeted để dạy lại. Tương tự trong tài chính, nếu LLM mơ hồ về mối liên hệ giữa CPI và lãi suất, SENATOR sẽ generate bài tập bám sát dữ liệu cơ bản để fine‑tune.
Kết luận
SENATOR mang đến phương pháp “học đúng, học trúng, học đủ” cho LLM trong mọi domain chuyên sâu. Bằng việc kết hợp Structure Entropy và MCTS để scan lỗ hổng, rồi vá qua synthetic data siêu targeted, framework giúp model giảm hallucination, nâng cao độ tin cậy, đồng thời tiết kiệm tài nguyên fine‑tune. Nếu bạn đang phát triển LLM cho lĩnh vực hẹp nào đó, SENATOR chính là công cụ không thể bỏ qua.
REF
All rights reserved
