
Nhận diện khuôn mặt với mạng MTCNN và FaceNet (Phần 1)
Bài đăng này đã không được cập nhật trong 4 năm
Nhận diện khuôn mặt (Face Recognition) là một trong những thách thức lớn mà các nhà nghiên cứu về Học máy - Học sâu đã và đang phải đối mặt. Bài toán này có thể được áp dụng ở rất nhiều lĩnh vực khác nhau, đặc biệt trong những lĩnh vực yêu cầu độ chính xác và bảo mật cao như eKYC trong E-Comercial và nhận diện danh tính qua surveillance camera (CCTV). Ta sẽ chia bài toán này ra thành 2 vấn đề chính: Phát hiện khuôn măt (Face Detection) và Phân biệt khuôn mặt (Face Verification). Để đi sâu hơn về quá trình hiểu và áp dụng hoàn chỉnh một bài Face Recognition, chúng ta sẽ cùng tìm hiểu và inference 2 mạng nổi tiếng cho 2 vấn đề trên: MTCNN (Multi-task Cascaded Convolutional Networks) và FaceNet.
1. Tổng quan về MTCNN (Multi-task Cascaded Convolutional Networks):
Phần đầu tiên sẽ là về Face Detection, một bài toán với nhiệm vụ phát hiện các khuôn mặt có trong ảnh hoặc frame trong Video. Mạng MTCNN sẽ giúp chúng ta điều này với 3 lớp mạng khác biệt, tượng trưng cho 3 stage chính là P-Net, R-Net và O-Net (PRO!) . Chúng ta sẽ đi sâu hơn vào từng stage để hiểu rõ hơn nhé!
1.1 Stage 1: P-Net
Trước hết, một bức ảnh thường sẽ có nhiều hơn một người - một khuôn mặt. Ngoài ra, những khuôn mặt thường sẽ có kích thước khác nhau. Ta cần một phương thức để có thể nhận dạng toàn bộ số khuôn mặt đó, ở các kích thước khác nhau. MTCNN đưa cho chúng ta một giải pháp, bằng cách sử dụng phép Resize ảnh, để tạo một loạt các bản copy từ ảnh gốc với kích cỡ khác nhau, từ to đến nhỏ, tạo thành 1 Image Pyramid.

Với mỗi một phiên bản copy-resize của ảnh gốc, ta sử dụng kernel 12x12 pixel và stride = 2 để đi qua toàn bộ bức ảnh, dò tìm khuôn mặt. Vì các bản copies của ảnh gốc có kích thước khác nhau, cho nên mạng có thể dễ dàng nhận biết được các khuôn mặt với kích thước khác nhau, mặc dù chỉ dùng 1 kernel với kích thước cố định (Ảnh to hơn, mặt to hơn; Ảnh nhỏ hơn, mặt nhỏ hơn). Sau đó, ta sẽ đưa những kernels được cắt ra từ trên và truyền qua mạng P-Net (Proposal Network). Kết quả của mạng cho ra một loạt các bounding boxes nằm trong mỗi kernel, mỗi bounding boxes sẽ chứa tọa độ 4 góc để xác định vị trí trong kernel chứa nó (đã được normalize về khoảng từ (0,1)) và điểm confident (Điểm tự tin) tương ứng.
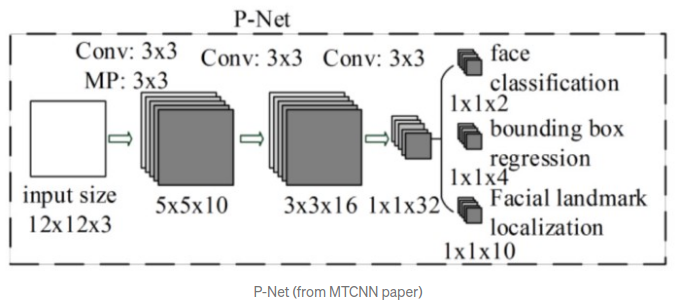
Để loại trừ bớt các bounding boxes trên các bức ảnh và các kernels, ta sử dụng 2 phương pháp chính là lập mức Threshold confident - nhằm xóa đi các box có mức confident thấp và sử dụng NMS (Non-Maximum Suppression) để xóa các box có tỷ lệ trùng nhau (Intersection Over Union) vượt qua 1 mức threshold tự đặt nào đó. Hình ảnh dưới đây là minh họa cho phép NMS, những box bị trùng nhau sẽ bị loại bỏ và giữ lại 1 box có mức confident cao nhất.
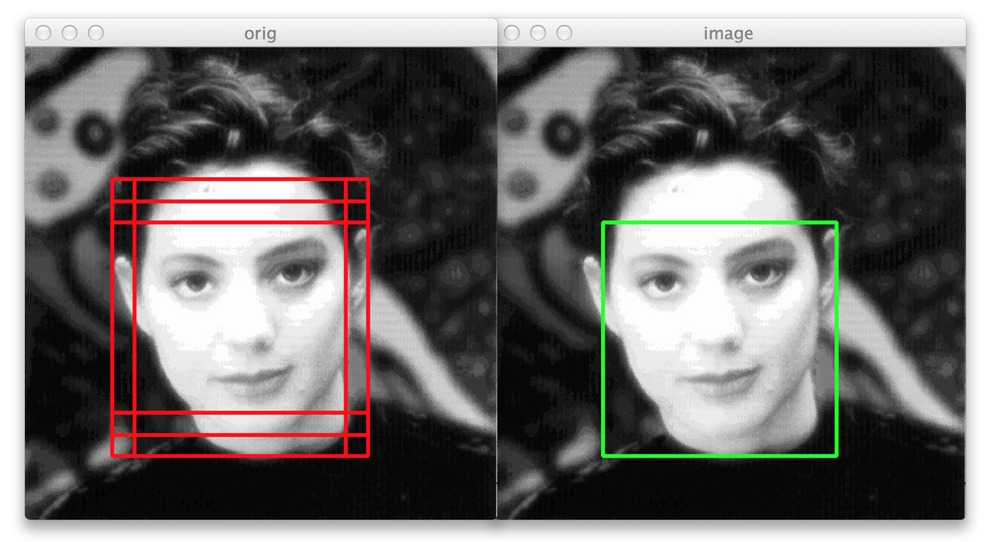
Sau khi đã xóa bớt các box không hợp lý, ta sẽ chuyển các tọa độ của các box về với tọa độ gốc của bức ảnh thật. Do tọa độ của box đã được normalize về khoảng (0,1) tương ứng như kernel, cho nên công việc lúc này chỉ là tính toán độ dài và rộng của kernel dựa theo ảnh gốc, sau đó nhân tọa độ đã được normalize của box với kích thước của của kernel và cộng với tọa độ của các góc kernel tương ứng. Kết quả của quá trình trên sẽ là những tọa độ của box tương ứng ở trên ảnh kích thước ban đầu. Cuối cùng, ta sẽ resize lại các box về dạng hình vuông, lấy tọa độ mới của các box và feed vào mạng tiếp theo, mạng R.
1.2 Stage 2: R-Net
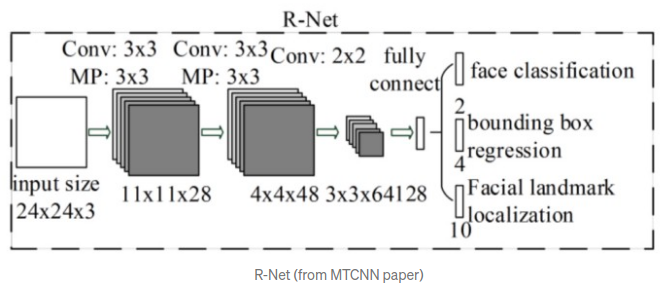
Mạng R (Refine Network) thực hiện các bước như mạng P. Tuy nhiên, mạng còn sử dụng một phương pháp tên là padding, nhằm thực hiện việc chèn thêm các zero-pixels vào các phần thiếu của bounding box nếu bounding box bị vượt quá biên của ảnh. Tất cả các bounding box lúc này sẽ được resize về kích thước 24x24, được coi như 1 kernel và feed vào mạng R. Kết quả sau cũng là những tọa độ mới của các box còn lại và được đưa vào mạng tiếp theo, mạng O.
1.3 Stage 3: O-Net

Cuối cùng là mạng O (Output Network), mạng cũng thực hiện tương tự như việc trong mạng R, thay đổi kích thước thành 48x48. Tuy nhiên, kết quả đầu ra của mạng lúc này không còn chỉ là các tọa độ của các box nữa, mà trả về 3 giá trị bao gồm: 4 tọa độ của bounding box (out[0]), tọa độ 5 điểm landmark trên mặt, bao gồm 2 mắt, 1 mũi, 2 bên cánh môi (out[1]) và điểm confident của mỗi box (out[2]). Tất cả sẽ được lưu vào thành 1 dictionary với 3 keys kể trên.

Okay! Vậy là chúng ta đã xong phần Face Detection với MTCNN, đã có thể lấy được khuôn mặt từ các bức hình rồi. Tiếp theo, với bài toán Face Verification, ta sẽ sử dụng mạng FaceNet để tiến hành phân biệt và clustering các khuôn mặt.
2. Tổng quan về FaceNet (FaceNet: A Unified Embedding for Face Recognition and Clustering):
Phần tiếp theo là về Face Verification. Nhiệm vụ chính của bài toán này là đánh giá xem ảnh mặt hiện tại có đúng với thông tin, mặt của một người khác đã có trong hệ thống không. Để tiếp cận bài toán này, trước tiên, chúng ta cần nắm được một số khái niệm có trong Paper của FaceNet .
2.1 Các khái niệm cơ bản:
- Embedding Vector: Là một vector với dimension cố định (thường có chiều nhỏ hơn các Feature Vector bình thường), đã được học trong quá trình train và đại diện cho một tập các feature có trách nhiệm trong việc phân loại các đối tượng trong chiều không gian đã được biến đổi. Embedding rất hữu dụng trong việc tìm các Nearest Neighbor trong 1 Cluster cho sẵn, dựa theo khoảng cách-mối quan hệ giữa các embedding với nhau.
- Inception V1: Một cấu trúc mạng CNN được giới thiệu vào năm 2014 của Google, với đặc trưng là các khối Inception. Khổi này cho phép mạng được học theo cấu trúc song song, nghĩa là với 1 đầu vào có thể được đưa vào nhiều các lớp Convolution khác nhau để đưa ra các kết quả khác nhau, sau đó sẽ được Concatenate vào thành 1 output. Việc học song song này giúp mạng có thể học được nhiều chi tiết hơn, lấy được nhiều feature hơn so với mạng CNN truyền thống. Ngoài ra, mạng cũng áp dụng các khối Convolution 1x1 nhằm giảm kích thước của mạng, khiến việc train trở nên nhanh hơn.
- Triplet Loss: Thay vì sử dụng các hàm loss truyền thống, khi mà ta chỉ so sánh giá trị đầu ra của mạng với ground truth thực tế của dữ liệu, Triplet Loss đưa ra một công thức mới bao gồm 3 giá trị đầu vào gồm anchor (mỏ neo, nếu các bạn muốn biết lý do vì sao nó có tên như vậy thì hình GIF dưới sẽ giải thích khá rõ) : ảnh đầu ra của mạng, positive : ảnh cùng là 1 người với anchor và negative : ảnh không cùng là 1 người với anchor.
là margin (lề thêm) giữa cặp positive với negative, độ sai lệch cần thiết tối thiểu giữa 2 miền giá trị, chính là embedding của . Công thức trên cho ta thấy mong muốn về khoảng cách giữa 2 embeddings là và sẽ phải nhỏ hơn ít nhất giá trị so với cặp và . Việc của ta là làm cho sự chênh lệch giữa 2 phía của công thức trở nên lớn nhất có thể, hay nói cách khác, phải là minimum và phải là maximum. Và để mạng "khó" học hơn (hay nói cách khác, học được nhiều hơn) thì điểm positive được chọn phải nằm xa nhất có thể so với anchor, còn điểm negative được chọn phải nằm gần nhất có thể so với anchor, nhằm khiến cho mạng "gặp" những trường hợp xấu nhất. Hàm Loss tổng quát được nêu trong paper là công thức sau đây:
Các bạn có thể xem minh họa rõ ràng hơn về quá trình học nhờ dùng vào hàm Triplet Loss qua GIF dưới đây. Nguồn tại bài viết này (Bài viết trong link khá hay, các bạn có thể tham khảo thêm)

2.2 Quy trình thực hiện:
Quá trình Training:
-
Sử dụng một tập Dataset với rất nhiều các cá thể người khác nhau, mỗi cá thể có một số lượng ảnh nhất định.
-
Xây dựng một mạng DNN dùng để làm Feature Extractor cho Dataset trên, kết quả là 1 embedding 128-Dimensions. Trong paper có 2 đại diện mạng là Zeiler&Fergus và InceptionV1.
-
Huấn luyện mạng DNN để kết quả embedding có khả năng nhận diện tốt, bao gồm 2 việc là sử dụng normalization (Khoảng cách Euclide) cho các embeddings đầu ra và tối ưu lại các parameters trong mạng màng bằng Triplet Loss.
-
Hàm Triplet Loss sẽ sử dụng phương pháp Triplet Selection, lựa chọn các embeddings sao cho việc học diễn ra tốt nhất.
![image.png]()

Quá trình Inference:
-
Truyền ảnh mặt cần classify vào trong mạng Feature Extractor, thu được 1 embedding.
-
Tiến hành sử dụng hàm và so sánh với các embedding khác trong tập embeddings đã có. Việc classify sẽ giống như thuật toán k-NN với k = 1.
3. Tổng kết:
MTCNN và FaceNet là 2 mạng rất nổi tiếng trong việc xử lý bài toán Face Recognition nói chung. Và việc kết hợp giữa chúng, khi đầu vào là ảnh/video với rất nhiều người và trong hoàn cảnh thực tế, sẽ đưa ra được kết quả khá tốt. Khi đó, MTCNN sẽ đóng vai trò là Face Detection/Alignment, giúp cắt các khuôn mặt ra khỏi khung hình dưới dạng các tọa độ bounding boxes và chỉnh sửa / resize về đúng shape đầu vào của mạng FaceNet. Còn FaceNet sẽ đóng vai trò là mạng Feature Extractor + Classifier cho từng bounding boxes, đưa ra embedding và tiền hành phân biệt và nhận dạng các khuôn mặt. Ở bài tiếp theo, chúng ta sẽ tìm hiểu về cách inference lại cả 2 mạng trên và tạo ra một mạng hoàn chỉnh, giúp nhận diện Realtime danh tính khuôn mặt nhé!
Bài viết chắc chắn sẽ còn nhiều thiếu sót, rất mong nhận được góp ý của mọi người để bài viết trở nên tốt hơn. Cảm ơn các bạn đã theo dõi và đọc bài của mình!
P/S: Phần 2 đã có tại đây
4. Tài liệu tham khảo:
All rights reserved
