
Thử làm ứng dụng tô màu ảnh với mạng Deep Learning
Bài đăng này đã không được cập nhật trong 7 năm
Google Photos và tính năng tô màu cho ảnh đen trắng
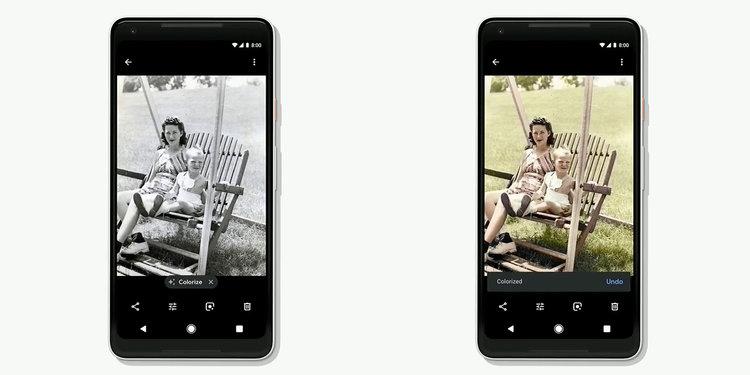
Bức ảnh mà các bạn đang nhìn thấy phía trên là một trong số các bức ảnh tại sự kiện Google I/O 2018. Bức ảnh được đưa ra nhằm công bố một trong số những tính năng ấn tượng mà Google đang chuẩn bị tích hợp vào ứng dụng Google Photos - Sử dụng trí tuệ nhân tạo để tô màu cho ảnh xám. Cùng với rất nhiều tiện ích mới khác, đây được coi là một tham vọng lớn của Google, với mong muốn "nâng cấp" Google Photos không chỉ là ứng dụng lưu trữ ảnh thông thường mà còn trang bị thêm các công nghệ AI để bổ sung thêm nhiều tính năng thông minh.
Tính năng khi được ra mắt, sẽ giúp cho người dùng có thể "biến" một bức ảnh xám (có thể là các bức ảnh đã chụp từ xưa) trở thành ảnh màu. Ứng dụng có khả năng đoán ra được những màu sắc phù hợp nhất cho bức ảnh.
Mục tiêu
Bài toán Tô màu cho ảnh như Google đang giải quyết ở trên khi tiếp cận bằng phương pháp Deep Learning có thể đem lại những kết quả rất tốt nếu như chúng ta xây dựng được mạng neuron hợp lý và tìm kiếm được những bộ dataset chất lượng cao. Vốn là người thích thử-sai  vậy nên trong bài viết lần mình sẽ thử xây dựng mô hình để làm ứng dụng này xem sao!
vậy nên trong bài viết lần mình sẽ thử xây dựng mô hình để làm ứng dụng này xem sao!
Các bước thực hiện
Như mình đã nói ở trên, với các bài toán tiếp cận bằng Deep Learning, việc thu thập - xử lý dữ liệu cùng với xây dựng một mạng DL hợp lý là những công việc bắt buộc. Và với ứng dụng này, chúng ta cũng sẽ đi qua các bước như sau
- Thu thập và tiền xử lý dữ liệu
- Xây dựng và huấn luyện mô hình DL
- Theo dõi kết quả và tối ưu
1. Thu thập và tiền xử lý dữ liệu
Hệ màu HSV
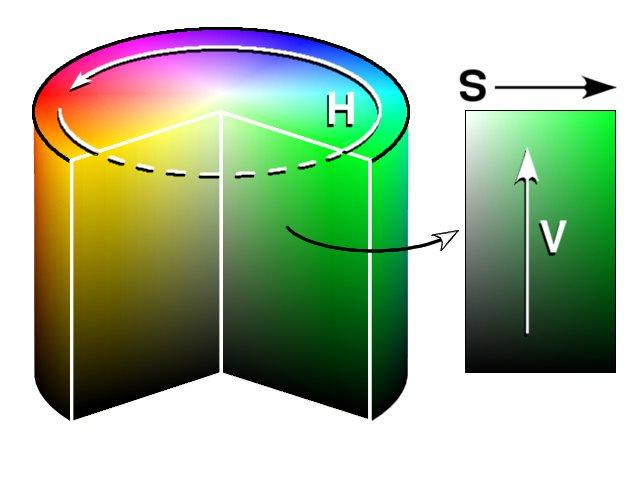
Đa phần chúng ta hiện nay khi nhắc tới màu sắc, mọi người sẽ thường nghĩ ngay tới hệ màu RGB (Red, Green, Blue) hoặc một số ít có thể sẽ biết đến hệ màu CMYK (cyan, magenta, yellow, key). Tuy nhiên, nếu bạn có để ý thì trong các công cụ chọn màu (color picker), hệ màu HSV (hue, saturation, value) thường sẽ được sử dụng. Lý do là vì khác với RGB và CMYK, sử dụng sự phối hợp giữa các màu cơ bản ban đầu để định nghĩa ra toàn bộ các màu còn lại, hệ màu HSV định nghĩa các màu theo một cách khá tương tự với cách mà mắt người cảm giác về màu sắc (Đó cũng là lý do các công cụ chọn mà sử dụng hệ màu này). Cụ thể như sau.
Một màu bất kỳ trong hệ HSV sẽ được định nghĩa bởi 3 tham số
- Hue (H): Màu - Đây chính là tham số thể hiện màu sắc (Vòng tròn trong ảnh phía trên). Tùy vào việc màu đó là màu gì mà H sẽ có tham số cụ thể (Ví dụ Màu đỏ sẽ rơi vào góc từ 0-60 độ, màu xanh lá cây từ 120 - 180 độ, màu xanh da trời từ 240-300 độ)
- Saturation (S): Độ bão hòa - Tham số thể hiện cho mức độ màu xám thể hiện ở trong các màu (Trục ngang trong ảnh phía trên). Với giá trị lớn nhất của độ bão hóa, màu sắc sẽ được thể hiện rõ nét nhất, ngược lại màu sắc sẽ xám dần.
- Value(V): Một số định nghĩa gọi là B - Brightness - Kết hợp với tham số S để tạo nên độ sáng và cường độ của màu. NẾU CHỈ TÁCH RIÊNG GIÁ TRỊ V RA, TA CÓ THỂ COI ĐÂY CHÍNH LÀ ẢNH XÁM CỦA MỘT ẢNH MÀU
Chọn việc xử lý và huấn luyện trên hệ màu HSV
Bài toán của chúng ta ở đây là cho đầu vào là một ảnh xám (1 channel), mô hình sẽ xử lý và đưa đầu ra là một ảnh màu (3 channel - với hệ RGB). Để giảm thiểu tham số cần phải xử lý thì với việc sử dụng hệ màu HSV, dựa vào việc coi ảnh xám đầu vào chính là giá trị V của ảnh đầu ra, mô hinh của chúng ta sẽ chỉ còn phải đoán 2 hệ màu còn lại (thay vì 3 nếu sử dụng RGB, 4 nếu sử dụng CMYK).
Vậy tóm lại, chúng ta chọn hệ màu HSV để xử lý vì 2 lý do chính như sau:
- Hệ màu HSV biểu diễn giống với cách mắt người cảm nhận màu sắc => Việc huấn luyện mô hình Deep Learning sẽ có thể có độ chính xác cao hơn.
- Hệ màu HSV có tham số V được coi như ảnh xám của ảnh ban đầu => Giảm thiểu các tham số cần phải huấn luyện cho mô hình Deep Learning.
Thu thập dữ liệu
Dữ liệu của chúng ta cần lần này không có yêu cầu gì đặc biệt, chỉ cần chúng là ảnh màu. Các bạn có thể lấy các ảnh bất kỳ để đưa vào training. Đối với mình, mình sẽ sử dụng tập ảnh Places365 - một dataset rất lớn được sử dụng trong các challenge về nhận biết hình ảnh. Dataset bao gồm các ảnh chụp phong cảnh của rất nhiều nơi trên thế giới trong nhiều khoảng thời gian khác nhau kèm theo nhãn là địa điểm chụp. Tuy nhiên ở đây, chúng ta sẽ chỉ cần lấy ảnh thôi!
Các bạn có thể tìm và tải xuống tập Places365 ở đây: http://places2.csail.mit.edu/download.html
Dữ liệu vô cùng nhiều, mình sẽ chỉ download tập test trên đó để dùng cho lần này (~4,7GB)
Tiền xử lý dữ liệu
Với việc chọn xử lý trên hệ màu HSV, công việc chúng ta trong giai đoạn tiền xử lý sẽ là đưa ảnh về hệ màu HSV, tách kênh V ra làm ảnh đầu vào, và 2 kênh H, S làm nhãn cho việc huấn luyện. Mình thực hiện như sau
def split_hsv_img(img_path):
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
return img_hsv[:, :, :2], img_hsv[:, :, 2]
Sau khi thực hiện chúng ta sẽ có 1 tập huấn luyện bao gồm các ảnh xám để training và các labels là ảnh đó ở 2 kênh H và S.
X.shape = (-1, 224, 224)
y.shape = (-1, 224, 224, 2)
2. Xây dựng mạng Deep Learning
Mạng U-Net
Với bài toán tô màu này, hiện có nhiều mạng DL đang tỏ ra rất hiệu quả, nhưng trong bài lần này, để cho dễ hiểu, mình sẽ sử dụng mạng Resnet, chỉnh sửa thay đổi 1 chút theo ý tưởng của mạng U-net (Một mạng đang được sử dụng phổ biến cho các cuộc thi phân vùng ảnh bởi tốc độ và độ chính xác của nó- Segmentation)
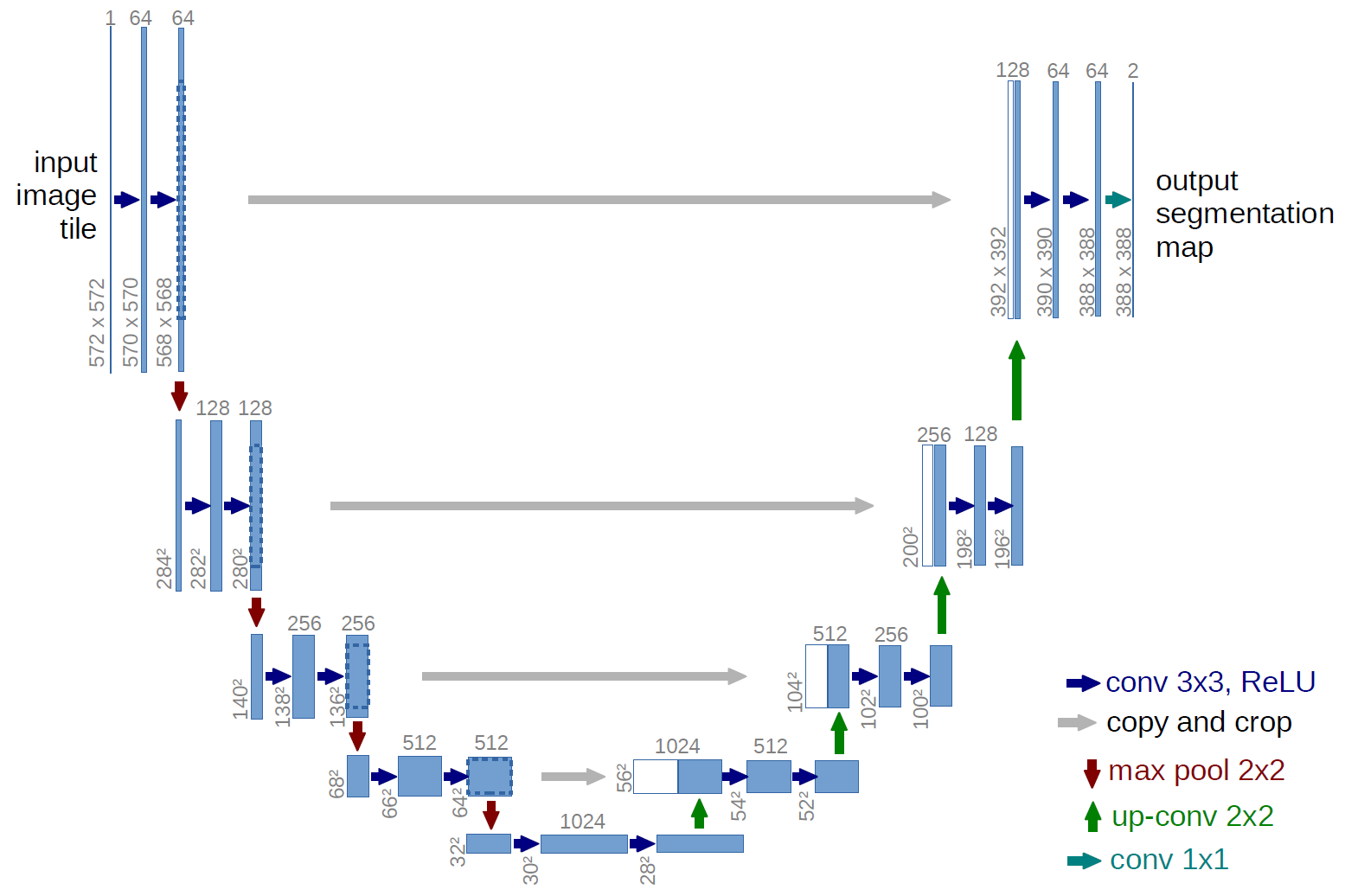
Ý tưởng chính của mạng U-Net gần giống như một auto-encoder, từ một ảnh ban đầu, sử dụng các lớp Conv2D để phân tích và trích chọn đặc trưng, downscale đưa về lớp Fully Connected, sau đó dùng Conv2D Transpose để upscale lại về kích thước ảnh ban đầu. Việc trích đặc trưng này làm cho mạng neuron thường khá sâu, chính vì vậy tại các lớp cuối, mô hình có thể bị quên đi các đặc trưng từ ảnh ban đầu hoặc đặc trưng được trích ra từ những lớp ban đầu, vậy nên U-Net sẽ đưa các ảnh từ các lớp ban đầu vào quá trình huấn luyện của các lớp sau như 1 tham số để tránh tình trạng đó.
Xây dựng mô hình cho bài toán tô màu
Mình sẽ sử dụng mạng cơ sở là Resnet và build dựa trên ý tưởng U-Net vừa rồi.
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model
from tensorflow.keras import applications
resnet = applications.resnet50.ResNet50(weights=None, classes=365)
x = resnet.output
model_tmp = Model(inputs = resnet.input, outputs = x)
#Get outputs of decode layers
layer_3, layer_7, layer_13, layer_16 = model_tmp.get_layer('activation_9').output, model_tmp.get_layer('activation_21').output, model_tmp.get_layer('activation_39').output, model_tmp.get_layer('activation_48').output
#Adding outputs decoder with encoder layers
fcn1 = Conv2D(filters=2 , kernel_size=1, name='fcn1')(layer_16)
fcn2 = Conv2DTranspose(filters=layer_13.get_shape().as_list()[-1] , kernel_size=4, strides=2, padding='same', name='fcn2')(fcn1)
fcn2_skip_connected = Add(name="fcn2_plus_layer13")([fcn2, layer_13])
fcn3 = Conv2DTranspose(filters=layer_7.get_shape().as_list()[-1], kernel_size=4, strides=2, padding='same', name="fcn3")(fcn2_skip_connected)
fcn3_skip_connected = Add(name="fcn3_plus_layer_7")([fcn3, layer_7])
fcn4 = Conv2DTranspose(filters=layer_3.get_shape().as_list()[-1], kernel_size=4, strides=2, padding='same', name="fcn4")(fcn3_skip_connected)
fcn4_skip_connected = Add(name="fcn4_plus_layer_3")([fcn4, layer_3])
# Upsample again
fcn5 = Conv2DTranspose(filters=2, kernel_size=16, strides=(4, 4), padding='same', name="fcn5")(fcn4_skip_connected)
relu255 = ReLU(max_value=255) (fcn5)
model = Model(inputs = resnet.input, outputs = relu255)
model.summary()
Mô hình thu được
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
__________________________________________________________________________________________________
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 112, 112, 64) 9472 conv1_pad[0][0]
__________________________________________________________________________________________________
bn_conv1 (BatchNormalization) (None, 112, 112, 64) 256 conv1[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 112, 112, 64) 0 bn_conv1[0][0]
......
fcn4 (Conv2DTranspose) (None, 56, 56, 256) 2097408 fcn3_plus_layer_7[0][0]
__________________________________________________________________________________________________
fcn4_plus_layer_3 (Add) (None, 56, 56, 256) 0 fcn4[0][0]
activation_9[0][0]
__________________________________________________________________________________________________
fcn5 (Conv2DTranspose) (None, 224, 224, 2) 131074 fcn4_plus_layer_3[0][0]
__________________________________________________________________________________________________
re_lu (ReLU) (None, 224, 224, 2) 0 fcn5[0][0]
==================================================================================================
Total params: 34,243,204
Trainable params: 34,190,084
Non-trainable params: 53,120
Các giá trị OpenCV gán cho hệ màu HSV sẽ vào khoảng từ 0-255, vậy nên tại lớp cuối cùng, mình sẽ sử dụng ReLU và gán max là 255 nhằm kiểm soát đầu ra chặt chẽ hơn. Hãy để ý đầu ra, chúng ta cần phải tính toán các tham số của các lớp Conv2D và Conv2DTranspose để kích thước của nó hoàn toàn giống với đầu vào, tuy nhiên sẽ có 2 kênh khác nhau. Đây là đầu ra mà chúng ta đang cần tính, để ghép với đầu vào tạo ra 1 bức ảnh hệ HSV có màu!
Lưu ý: Có thể các bạn cũng sẽ nhận ra, đầu vào của mạng Resnet sẽ là một ảnh màu 3 chiều. Vậy nên trước khi đưa vào huấn luyện, mình sẽ phải thực hiện 1 thao tác để đưa ảnh xám 1 chiều của mình về 3 chiều. Ở đây mình sẽ sử dụng thẳng hàm cvtColor của OpenCV cho tiện
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
Hàm trên của OpenCV tất nhiên không phải là một hàm sử dụng trí tuệ nhân tạo để đưa ảnh xám về ảnh màu, tác dụng của nó sẽ là tạo ra ảnh 3 kênh giống hệt nhau từ 1 kênh ban đầu (nhân 3 số channel).
Hàm loss và optimizer
Để tạo ra sự trực quan, bài toán này chúng ta sẽ sử dụng Regression Linear, tức là giá trị của đoán ra sẽ được đánh giá cả mức độ sai số so với giá trị nhãn, thay vì chỉ quan tâm đúng sai. Điều này là logic hơn rất nhiều so với việc chúng ta sử dụng Classification. Vì vậy ở đây mình sẽ sử dụng mean_squared_error , optimizer là rmsprop giống như các bài toán Regression phổ biến khác.
def root_mean_squared_error(y_true, y_pred):
return K.sqrt(K.mean(K.square(y_pred - y_true)))
model.compile(loss=root_mean_squared_error, optimizer='rmsprop')
Tiến hành huấn luyện
batch_size = 32
for i in range(0, 150):
i = np.random.randint(1, 9)
images, gt_images = load_data(i)
model.fit_generator(generator=image_batch_generator(images, gt_images, batch_size),
steps_per_epoch=len(images)//batch_size,
epochs=5,
verbose=1,
validation_data=image_batch_generator(images_val, gt_images_val, batch_size),
validation_steps=len(images_val)//batch_size,
callbacks=callbacks_list)
del images, gt_images
Vấn đề dữ liệu training lớn
Do lượng dữ liệu là rất lớn, vậy nên tốt nhất các bạn hãy sử dụng hàm fit_generator để tránh việc phải load toàn bộ dữ liệu training vào RAM hoặc GPU. Ở đây do dữ liệu lớn nên mình đã phải chia ra làm nhiều tập training (Ở đây mình chia dữ liệu thành 10 tập nhỏ, tập số 10 sẽ làm dữ liệu để validate), mình sẽ thực hiện load ngẫu nhiên 1 trong số đó vào để training 5 epochs rồi tiếp tục lấy tập khác vào.
.....
Epoch 00001: loss did not improve from 36.42126
312/312 [==============================] - 552s 2s/step - loss: 47.1491 - val_loss: 53.8508
Epoch 2/5
311/312 [============================>.] - ETA: 1s - loss: 44.4026
Epoch 00002: loss did not improve from 36.42126
312/312 [==============================] - 552s 2s/step - loss: 44.4070 - val_loss: 55.8593
Epoch 3/5
311/312 [============================>.] - ETA: 1s - loss: 42.5710
Epoch 00003: loss did not improve from 36.42126
312/312 [==============================] - 552s 2s/step - loss: 42.5674 - val_loss: 54.0140
Epoch 4/5
197/312 [=================>............] - ETA: 2:37 - loss: 41.1402
Mình dừng training sau khoảng 5 tiếng chạy trên Google Colab vì không có nhiều thời gian. Nếu có thể, các bạn tải xuống tập dữ liệu lớn hơn và kiên nhẫn chờ đợi huấn luyện càng lâu càng tốt để có kết quả khả quan hơn nhiều nhé!
3. Xem thành quả training!
Mô hình sẽ nhận đầu vào là 1 ảnh xám, và đưa cho chúng ta đầu ra là 1 ảnh 2 chiều với 2 kênh H và S. Muốn kiểm tra kết quả, chúng ta cần phải ghép 3 chiều lại thành hệ HSV rồi đưa chúng quay lại hệ màu RGB thông thường để hiển thị.
def regenerate_img(gray, hs):
img = np.zeros((224, 224, 3))
img [:, :, 2] = gray #V
img [:, :, 0] = hs[:, :, 0] #H
img [:, :, 1] = hs[:, :, 1] #S
img = np.array(img, np.uint8)
img = cv2.cvtColor(img, cv2.COLOR_HSV2RGB) #Convert to RGB
return img
Đây là kết quả mô hình của mình, mình chọn ngẫu nhiên vài ảnh trong tập validate để hiển thị

Trong file Predict ở repo của mình có để các ảnh kết quả khác trong tập validate, các bạn có thể vào để xem thêm.
Tùy vào tập data các bạn dùng để training, mà mô hình của chúng ta sẽ có các cách "sáng tạo" khác nhau khi tô màu. Nếu các bạn muốn tô màu cho ảnh phong cảnh, lựa chọn dataset Places365 là một lựa chọn không tồi, còn nếu muốn tô màu cho ảnh chân dung (phục chế ảnh), hãy tìm kiếm tập dataset cho ảnh chân dung (Ví dụ có thể kể đến tập CelebA), muốn tô màu cho ảnh có nhiều vật thể, ImageNet có lẽ sẽ là phù hợp.
Tổng kết
Bài viết hôm nay mình đã thử huấn luyện một mô hình Deep Learning nhằm giải bài toán tô màu cho ảnh xám. Mô hình mình build được dựa trên một mạng khá quen thuộc và có sẵn trong thư viện Keras là Resnet nên hy vọng sẽ giảm bớt khó khăn cho các bạn trong việc đọc và code theo.
Để mô hình có thể đoán được các màu một các hiệu quả và hợp lý hơn, ngoài việc dùng Deep Learning bình thường, chúng ta sẽ cần sử dụng thêm các kiến thức và thuật toán về phân bố màu sắc khác mà mình chưa tiện đề cập trong bài viết, các bạn có thể tìm đọc đến rất nhiều paper hiện nay liên quan đến bài toán này.
Mình đã đẩy source code của mình lên github nhằm giúp các bạn dễ theo dõi hơn:
https://github.com/hoanganhpham1006/colorization
Nếu có thắc mắc gì trong bài viết, hãy comment trực tiếp ở đây nhé! ^^ Cảm ơn các bạn đã theo dõi và ủng hộ mình.
All rights reserved
