
Tách lời khỏi nhạc: công cụ không thể thiếu cho các producer phòng ngủ
Bài đăng này đã không được cập nhật trong 5 năm
lời xin lỗi của tác giả: hiện tại tác giả đã xài hết $300 credit của Google Cloud nên server đã chết. đồng thời tác giả đã không gia hạn domain underlandian.com được nhắc đến trong bài nên lại càng là 2 lần chết. tác giả vô cùng xin lỗi bạn đọc.
Tại sao bạn nên quan tâm?
Đã bao giờ bạn nghĩ là Masew hay Touliver mix bài nào cũng như nhau phí cả vocal hay? Vì vậy bạn đã bắt đầu tập tành vọc các phần mềm làm nhạc như FL Studio hay Ableton Live hay Logic Pro và tạo ra một bản remix vô cùng cháy (nếu bạn xài Pro Tools thì xin cho mình chia buồn). Bước tiếp theo là bạn muốn lấy cái giọng ngọt ngào của Bảo Thy để nhét vào bản mix của bạn, nhưng khá chắc là có giời họ sẽ trả lời tin nhắn của bạn... Vậy thì, để mình giới thiệu cách bạn có thể tách ra những lời mẹ ru đó ra cho bài của bạn nhé! Đảm bảo mix nhạc hết mình share lên mạng hết buồn!
đảm bảo trên chỉ đúng nếu nhạc bạn cháy thật.
Chỉ với 0,000 đồng, sau khi đọc bài này, bạn sẽ:
- có một bài viết lại đúng chủ đề sếp mình đã viết ở đây
- biết một số phương pháp tách nhạc khá tốt
- có một nguồn tách nhạc không được tốt lắm từ server riêng của mình
- profile soundcloud của mình tại vì mình muốn quảng cáo nhạc của mình
Và bạn sẽ không có:
- kỹ năng viết nhạc cháy hơn masew hay touliver tại vì mình cũng không có đâu
Giới thiệu sơ sơ về các khái niệm cơ bản liên quan:
- Short-Time Fourier Transform (STFT)
Để hiểu được cái này là gì thì bạn cần hiểu (Discrete/Fast) Fourier Transform (DFT/FFT) là gì đã. Về cơ bản, nó tách một tín hiệu thành các tổng của các sóng cơ bản. Mình sẽ tập trung vào tín hiệu âm thanh tạm thôi:
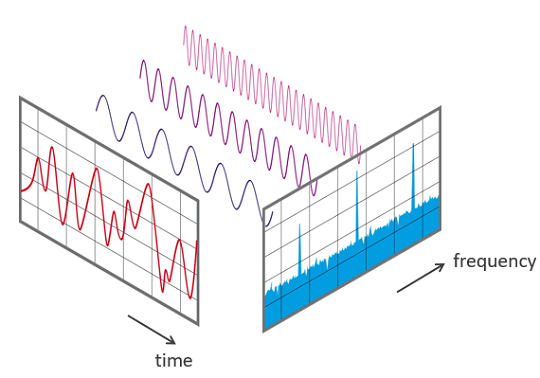
Bên trái màu đỏ, bạn có thể thấy một tín hiệu âm thanh như bạn vẫn thường thấy. Tín hiệu được tách ra thành ba sóng tuần hoàn cơ bản màu xanh xanh tím tím như kia, và tần số cơ bản của đám sóng đó chính là 3 cái mũi nhọn trong cái đồ thị tần số bên phải màu xanh lục. Mỗi mũi nhọn đó trục ngang tương ứng với tần số sóng cơ bản, và độ cao của nó là độ to của sóng cơ bản đó trong tín hiệu chính.
Giải thích một cách nhạc lý hơn nhé: bạn có thể tưởng tượng cái file nhạc của bạn có hợp âm A minor cơ bản, thì sau FFT bạn sẽ thấy ở ô các nốt A4 (nốt la - 440 Hz), C5 (nốt đô - 523.25 Hz), và E5 (nốt mi - 659.25 Hz) sẽ có giá trị khá cao, trong khi các nốt còn lại không tồn tại trong hợp âm đó sẽ có giá trị 0.
DFT và FFT kết quả giống nhau, chỉ là FFT nhanh hơn DFT nhiều vì nó ép sóng vào có độ dài là lũy thừa của 2 và tận dụng tính chất đó.
Quay trở lại STFT: khi chúng ta chia nhỏ tín hiệu thành từng khoảng nhỏ (có thể trùng nhau), dùng FFT trên từng đoạn đó và xem dải tần số của âm đó thay đổi như thế nào theo thời gian thôi.
Kết quả của FFT/STFT là một vector/matrix các số phức, và vì nó hơi khó hiểu, chúng ta sẽ tách nó thành các phần dễ hiểu hơn. Mỗi số phức đều có thể biểu diễn dưới dạng độ lớn và góc (pha) của nó:
và chúng ta sẽ chỉ xử lý phần độ lớn qua cái mạng máy học thôi, còn ma trận pha giữ lại để đến cuối chúng ta xây dựng ra lại cái acapella (không) mượt mà mà mình đã hứa từ đầu đó. Nhìn 3D thì cái ma trận độ lớn nó sẽ nhìn như thế nè nè:
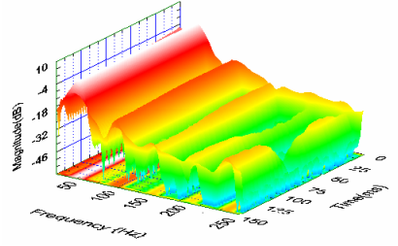
nếu chúng ta nhìn 2D theo trục thời gian và tần số không thôi, vì độ lớn đã được biểu diễn bằng màu, thì nó nhìn như thế nè nè

- Convolutional Neural Network
Cái này văn chương viết nhiều đến chết rồi, bạn có thể tham khảo một bài viết của anh trai mưa team mình Nguyễn Văn Đạt ở link này nhé! Về cơ bản, sử dụng các cửa sổ tích chập và qua các phép kích hoạt phi tuyến tính, các lớp đó sẽ tạo ra các tính chất của thông tin để chúng ta xử lý.
spoiler: chúng ta sẽ cho cái ảnh 2D của ma trận độ lớn của STFT qua các lớp convolutional.
- U-Net
Mạng U-Net, như ông Toằn Vi Lốc đã giải thích sơ qua, có hình như sau:

Khác với CNN thuần, trước mỗi lớp giảm chiều khi encode, các đặc tính được đưa đường tắt qua bên decode, để giữ lại những thông tin bị mất đi trong lúc giảm chiều. Mô hình này hay được xử dụng cho bài toán segmentation: khi bạn cần chỉ ra trong một bức ảnh thì đâu là cái thứ bạn cần tìm.
Trong bài toán này, giả thiết được đặt ra là một phần (nhưng không phải tất cả các ô thời gian-tần số) trong cái ảnh 2D kia tương ứng với phần vocal, và các ô còn lại tương ứng với nhạc nền. Nhìn 2 cái ảnh sau bạn sẽ thấy độ liên quan.
Đây là âm thanh gốc:

Và đây là âm thanh của lời không:

Bạn có thể thấy là ảnh trên có nhiều thông tin hơn ảnh dưới, ám chỉ là giả thiết của chúng ta có cơ sở. Vì vậy, thứ bạn cần tìm là từng độ lớn của sóng cơ bản trong thời gian -- về cơ bản thì nó là từng pixel trong cái ảnh spectrogram 2D ở trên kia kìa. Bài toán này được gọi là pixel-wise segmentation (duh).
spoiler 2: một phương pháp được đưa ra, và cũng là phương pháp mình xài, chính là U-Net.
Một phương pháp đã được xài với chất lượng khá tốt
Từ paper "Singing Voice Separation using a Deep Convolutional Neural Network Trained by Ideal Binary Mask and Cross Entropy" với repo ở đây, tác giả Lin et al. đã đưa ra một model về cơ bản là một vài lớp CNN, sau đó dàn phẳng ma trận kết quả thành một vector và cho qua hai lớp dense perceptron để đưa ra vector đầu ra xếp chữ nhật lại thành audio cuối. Mô hình của họ nhìn như sau:
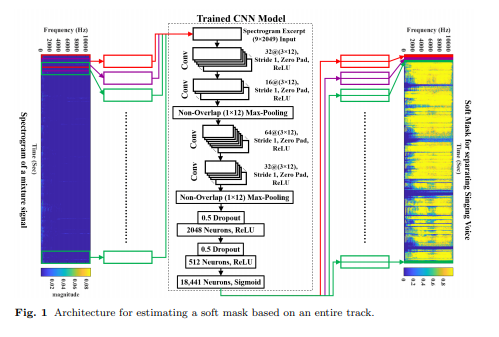
Tuy chất lượng khá ổn, mô hình của họ có gần 20 triệu (!) tham số, và lượng data họ có thì nhiều vô kể. Vì vậy, trừ khi bạn muốn nghiên cứu chuyên sâu/làm giải pháp bán/go pro làm nhạc thì thôi đừng cố.
Cách họ đã xử lý để lấy lượng data siêu to khổng lồ đó:
Họ lấy các bài nhạc và bản acapella trên các trang mạng như YouTube, rồi xài các hàm cross-correlation để xếp các bài đó sao cho trùng đúng thời gian và volume ngang nhau. Khá là ổn, mình sau này sẽ thí nghiệm cái đó sau.
Phương pháp sẽ được xài: U-Net
Phương pháp mình sẽ dùng giống như trong paper "SINGING VOICE SEPARATION WITH DEEP U-NET CONVOLUTIONAL NETWORKS" của tác giả đến từ Spotify mà các bạn có thể đọc tại đây. Mô hình các bạn có thể hình dung như sau:
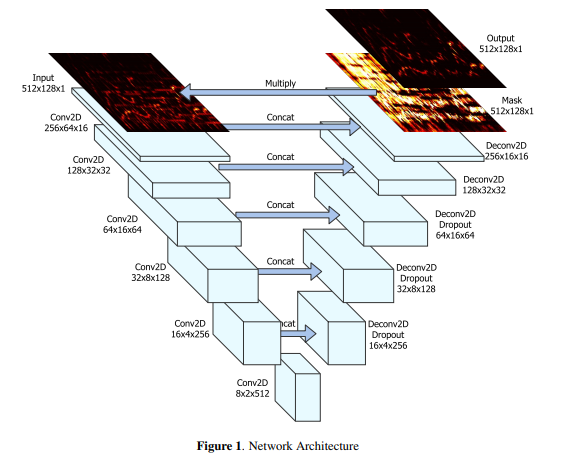
Mình sẽ dùng đúng dataset và các cách xử lý dữ liệu giống như ông Toằn Vi Lốc, nên bạn có thể đọc từ đó. Cho mình thanh minh là mình viết model này trước khi sếp mình viết nhé T^T; với cả mình viết trên Keras trong khi ổng viết PyTorch. Định nghĩa model của mình như sau:
main_input = Input(shape=(513,stft_len,channel), dtype='float32', name='audio_input')
# convolution 1
x = SeparableConv2D(filters=2*channel, kernel_size=5, padding='SAME')(main_input)
x = LeakyReLU(alpha=relu_rate)(x)
x = SeparableConv2D(filters=4*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = BatchNormalization()(x)
skip1 = Dropout(rate=drop_rate)(x)
# Pooling
x = MaxPooling2D(pool_size=4, strides=2)(skip1)
# convolution 2
x = SeparableConv2D(filters=8*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = SeparableConv2D(filters=16*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = BatchNormalization()(x)
skip2 = Dropout(rate=drop_rate)(x)
# Pooling
x = MaxPooling2D(pool_size=4, strides=2)(skip2)
# convolution 3
x = SeparableConv2D(filters=32*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = SeparableConv2D(filters=64*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = BatchNormalization()(x)
skip3 = Dropout(rate=drop_rate)(x)
# Pooling
x = MaxPooling2D(pool_size=4, strides=2)(skip3)
# bottom layer, do not expand
x = DepthwiseConv2D(kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = DepthwiseConv2D(kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = BatchNormalization()(x)
# Deconvolve to match dimensions
x = Conv2DTranspose(filters=64*channel, kernel_size=4, strides=2)(x)
x = Concatenate(axis=-1)([skip3, x])
# and convolve
x = SeparableConv2D(filters=32*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = SeparableConv2D(filters=16*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = BatchNormalization()(x)
x = Conv2DTranspose(filters=16*channel, kernel_size=5, strides=2)(x)
x = Concatenate(axis=-1)([skip2, x])
# and convolve
x = SeparableConv2D(filters=8*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = SeparableConv2D(filters=4*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = BatchNormalization()(x)
x = Conv2DTranspose(filters=4*channel, kernel_size=5, strides=2)(x)
x = Concatenate(axis=-1)([skip1, x])
# and convolve
x = SeparableConv2D(filters=2*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
x = SeparableConv2D(filters=1*channel, kernel_size=5, padding='SAME')(x)
x = LeakyReLU(alpha=relu_rate)(x)
main_output = x
model = Model(inputs=main_input, outputs=main_output)
Để ý rằng convolution layers của mình đều để padding là SAME, để giữ nguyên kích cỡ ảnh. Điều đó khá hiển nhiên, vì rõ ràng output của chúng ta sẽ cùng kích cỡ với input, vừa vì lời tương ứng với nhạc và vừa để chúng ta sau này còn xài lại ma trận pha. Sau đó như bình thường, chúng ta train giảm loss là độ khác nhau giữa spectrogram model đưa ra và spectrogram của vocal xịn -- độ khác nhau được tính bằng mean-absolute error (MAE):
Hàm loss này khác với anh Toàn (MSE), vì theo mình MAE sẽ cố gắng tạo ra các ô nhiều số 0 hơn (thưa hơn), và sẽ làm cho kết quả nghe "crisp" (gọn? tách tốt?) hơn.
Kết quả?
Thôi code làm gì cho mệt đầu nhỉ khi ai cũng code cho rồi  Repo của mình ở đây, các bạn có thể xài thoải mái.
Repo của mình ở đây, các bạn có thể xài thoải mái.
Như mình đã hứa, mình có host một server tách nhạc các bạn có thể thử với bất cứ bài gì bạn muốn! Link đây nè: voxtrac.underlandian.com -- tên đó là wordplay giữa vocal extract/ phát âm như vocal track.

Kết bài
Chúc các bạn vui vẻ! Mình hiện tại vẫn đang thí nghiệm với nhiều model khác để xem liệu có thể ra được một giải pháp tốt như mơ, nhưng đó vẫn chỉ là giấc mơ mà thôi nên...  Ví dụ, có thể xài skip connection kiểu khác -- chủ đề đã được thảo luận trong một paper mà mình và anh Toàn đang nộp nên các bạn có thể chờ đợi nha, tuy nhiên chất lượng cũng chưa được hoàn hảo như mình mong đợi.
Ví dụ, có thể xài skip connection kiểu khác -- chủ đề đã được thảo luận trong một paper mà mình và anh Toàn đang nộp nên các bạn có thể chờ đợi nha, tuy nhiên chất lượng cũng chưa được hoàn hảo như mình mong đợi.
Các bạn (nhất là đồng nghiệp) có nhạc gì các bạn làm hay thì comment dưới nha cho mình nghe ké với. Hãy bắt đầu việc tách vocal sơn thùng atm và remix nào!
All rights reserved
