
[Paper Explain] Sử dụng Self-Instruct và Unnatural Instruction để tạo thêm dữ liệu training LLM
Bài đăng này đã không được cập nhật trong 2 năm
Instruction finetuning
Việc có một mô hình ngôn ngữ (LM) có khả năng generalize tốt (trong quá khứ) thì khá là khó. Ta đã có thể train instance-level generalize model một cách khá ổn. Tức là, ta sẽ train một model thực hiện mapping input sang output trong task : với . Và khi thực hiện test thì ta sẽ test trên các instance với cùng task .
Tuy nhiên, một LM mạnh, như đã nói, thì cần phải có khả năng generalize tốt, có khả năng cross-task generalization. Ta sẽ train model trên các task cho trước: với và và thực hiện test model trên các task chưa gặp: với
Con người có khả năng tuyệt vời trong việc giải quyết các tasks khác nhau, chỉ bằng việc đọc chỉ dẫn (instruction) và nhìn vào một vài các ví dụ làm mẫu. Vì thế, ta muốn tạo ra một model có thể làm được task mới bằng việc đọc các instruction: với là instruction của task . Đây gọi là instruction finetuning.
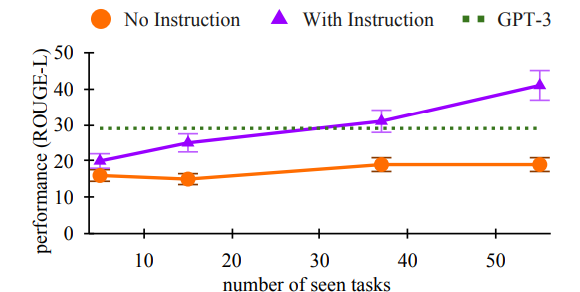
Với performance tuyệt vời của instruction finetuning, tất nhiên là ta sẽ cần nhiều data để thực hiện nó. Và để có được data thì con người lại phải đi viết instruction. Điều này là vô cùng tốn kém và mất thời gian. Hơn nữa, việc sử dụng con người viết instruction sẽ bị giới hạn về số lượng, độ đa dạng, độ sáng tạo, do đó model vẫn sẽ bị giới hạn về performance. Vì vậy, ta cần tìm ra phương pháp để quá trình tạo ra dữ liệu instruction một cách tự động.
Self-instruct
Định nghĩa instruction data
Để có thể sinh được data dạng instruction thì ta cần phải định nghĩa xem nó sẽ có dạng như nào.
Instruction data sẽ bao gồm tập hợp các instruction , mỗi instruction sẽ ứng với một task . Task sẽ bao gồm cặp input-output . Một model sẽ sinh ra output dựa trên task instruction và input tương ứng: với .
Chú ý rằng instruction và input không bị ràng buộc chặt chẽ với nhau. Ví dụ với instruction: "Write an essay about school safety" (Viết một đoạn văn nói về an toàn trong trường học) vẫn có thể làm instruction hoàn toàn bình thường và không cần sử dụng đến input, model vẫn có thể đưa ra được output. Hơn nữa, ta có thể viết lại cấu trúc instruction-input đầy đủ với instruction là: "Write an essay about the following topic" (Viết một đoạn văn về chủ đề sau) và input sẽ được để là "school safety" (an toàn trong trường học). Do vậy, để tăng thêm tính đa dạng trong dữ liệu, ta hoàn toàn có thể sử dụng các instruction không bao gồm input
Sinh instructon data tự động
Để có thể sinh data tự động thì chắc chắn là phải sử dụng một LM, hoặc một Large Language Model (LLM) để sinh rồi. Và model được lấy ví dụ trong bài này sẽ là GPT-3. Chú ý là model càng mạnh thì chất lượng của dữ liệu càng tốt nhé.
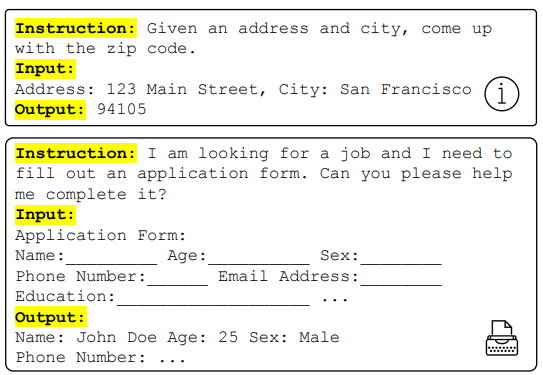
 Từ bây giờ một cặp input-output sẽ được gọi là một instance.
Từ bây giờ một cặp input-output sẽ được gọi là một instance.
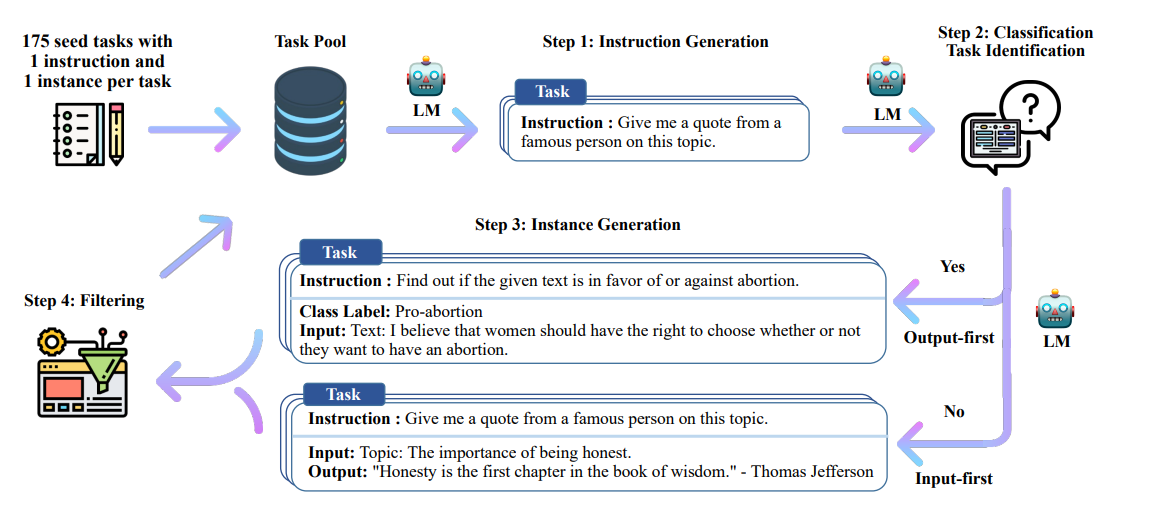
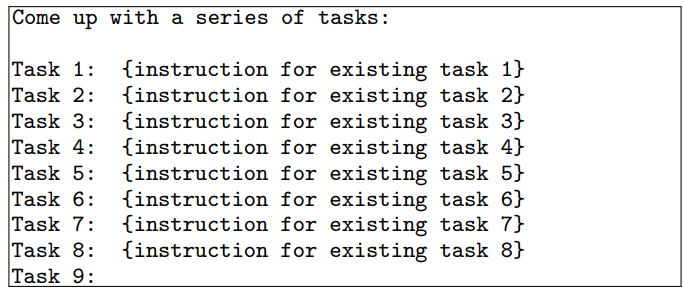
Sinh instruction. Ở bước đầu tiên, Self-Instruct sẽ thực hiện sinh ra instruction mới. Đầu tiên, ta sẽ có một task pool bao gồm 175 tasks (gồm 1 instruction và 1 instance cho mỗi task). Mỗi lần muốn sinh instruction, ta sẽ chọn ra 8 instructions ngẫu nhiên trong task pool này để làm ví dụ mẫu, đưa 8 instructions này vào model và yêu cầu model sinh ra thêm instructions mới (Hình 4).
Xét xem instruction sinh được có thuộc classification task không. Vì khi sinh dữ liệu, ta sẽ cần các phương pháp khác nhau đối với task thuộc dạng classification và task non-classification nên ta sẽ cần phải phân biệt chúng. Một task được gọi là classification khi output label của chúng sẽ nằm trong một không gian nhỏ (Hình 5).

Sinh instance. Với việc đã có instruction và loại task, ta sẽ thực hiện sinh instance cho từng instruction. Đây là bước khá là khó do model của chúng ta cần phải hiểu task chúng ta đưa cho nó là gì, dựa vào instruction và xem liệu có cần sử dụng tới input không và nếu cần thì tự động thêm input vào, và cũng phải tự hoàn thiện output. Thế nên ta khá là cần sử dụng một LM (hoặc LLM) mạnh ở đây. Một cách khá tự nhiên là thực hiện phương pháp Input-first: Ta sẽ bảo LM sinh ra một input dựa trên instruction, và sau đó sinh ra output tương ứng (Hình 6).

Tuy nhiên, khi sử dụng phương pháp Input-first thì input được sinh ra thường có xu hướng thiên vị về 1 label, đặc biệt là với classification task. Chẳng hạn, khi có một instruction là dạng kiểu "phát hiện lỗi ngữ pháp trong câu sau", thì câu input được sinh ra sẽ thường xuyên có lỗi ngữ pháp. Do đó, ta sử dụng phương pháp Output-first cho các task classification. Ta sẽ tạo ra output class label cho task classification trước, rồi sau đó mới tạo ra input dựa trên task và class label (Hình 7).
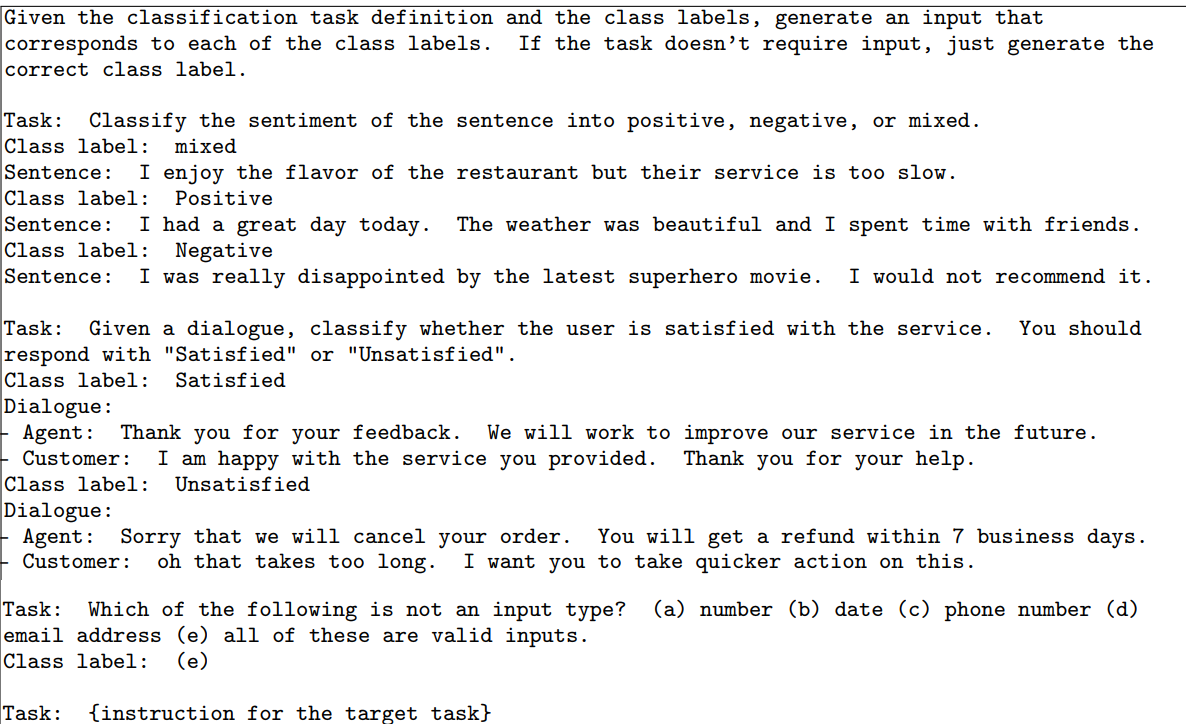
Do vậy, khi task là classification thì ta sẽ sinh instance theo Output-first, còn khi task là non-classification thì ta sẽ sinh instance theo Input-first
Filter và hậu xử lý. Để làm tăng độ đa dạng cho các instruction, ta sẽ chỉ lấy instruction với ROUGE-L similarity ít hơn 0.7 với từng instruction đã tồn tại trong pool. Hầu hết phần này là để xử lý những instance không phù hợp với một số quy luật của chúng ta đặt ra, và tất nhiên quy luật thì là của mỗi người và mỗi bài toán.
Unnatural Instruction
Tương tự với Self-instruct, Unnatural Instruction cũng sử dụng một model mạnh để sinh thêm instruction data, tuy nhiên khác nhau ở cách thức sinh data. Nếu như trong Self-Instruct, ta sẽ mất công làm cái task pool gồm 175 tasks để chất lượng task sinh ra giống với người nhất thì trong Unnatural Instruction ta chỉ cần cái task pool gồm 15 tasks thôi, vì nó là Unnatural (không giống người)
Định nghĩa instruction data
Tương tự như Self-Instruct, ta cũng phải biết Instruction data có dạng như nào thì mới có thể sinh được Một sample sẽ bao gồm 4 trường: (1) instruction mô tả task, (2) input, (3) constraint space, dùng để giới hạn output của task đó, constraint chủ yếu dùng cho task classification và (4) output
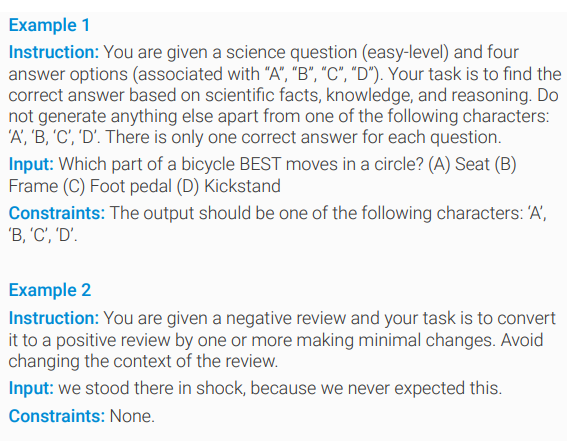
Sinh instructon data tự động

Sinh input. Thay vì sinh tuần tự Instruction -> Classify -> Input -> Output như Self-instruct thì Unnatural Instruct gộp một phát, sinh Instruction + Input + Constraint trong một lần. Ta sẽ prompt model với 3 task instance gồm Instruction + Input + Constraint và bảo model sinh cái thứ 4. Ở đây lại có một điểm nữa khác với Self-Instruct, ta sẽ chỉ sinh ra một instance gồm Instruction + Input + Constraint mới chứ k phải nhiều
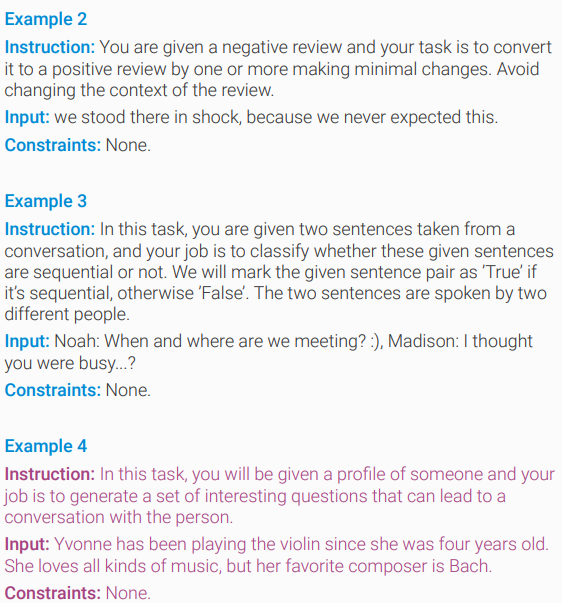
Filter. Unnatural Instruction thực hiện filter các instance được sinh ra: (1) các instance không có đủ 3 phần: Instruction, Input và Constraint; (2) Instruction và Input giống y hệt với mẫu trong prompt; (3) các instance bị lặp lại (dù đã sử dụng prompt khác)
Sinh output. Với một example , ta sẽ sinh ra được một output bằng việc đưa prompt là Instruction, Input, Constraint vào.
Mở rộng template. Những instance ta vừa sinh ra theo bước trên bị giới hạn ở format có instruction-input-output. Để tăng độ đa dạng cho format, Unnatural Instruction thêm vào một format thay thế nhưng vẫn giữ lại nội dung của instruction. Ta tiếp tục sử dụng model lên những instance đã được sinh ra để tạo ra 2 format thay thế, format thay thế thường ngắn hơn và ít "formal" hơn

Phân tích data được sinh ra
Mình sẽ không viết về phân tích của Self-instruct, vì người làm ra Self-instruct cũng không đưa ra quá nhiều phân tích có ý nghĩa cũng như là không đủ sâu.
Cảnh báo quan điểm cá nhân: Mình nghĩ rằng Self-instruct với một task pool tốt, nhiều và chất lượng cao, thì instruction data sinh ra sẽ tốt thôi. Tuy nhiên để có một task pool tốt thì cần nhiều thời gian và nhân lực. Thế nên mình sẽ phân tích về Unnatural Instruction là chủ yếu vì: Không cần một task pool tốt, instruction data sẽ như nào, có sử dụng được không?
Vì vậy những điều tóm tắt dưới đây đều thuộc về Unnatural Instruction
Unnatural Instruction sử dụng text-davinci-002 để sinh ra instruction data, và finetune model T5-11B
Lấy ra ngẫu nhiên 200 mẫu instruction data được sinh ra, mình biết 200 là quá ít để đánh giá toàn bộ dataset được sinh ra bởi Unnatural Instruction, nhưng 200 mẫu thôi cx đã tốn của họ rất nhiều thời gian rồi nên chúng ta hãy tin tưởng vào 200 mẫu đó thôi. Ta đánh giá 200 mẫu tập trung vào khía cạnh: tính đúng đắn và tính sáng tạo.
Tính đúng đắn. Kiểm tra xem: (1) instruction data được sinh ra có hợp logic và có thể thực thi được không? (2) input có phù hợp với mô tả của instruction không? (3) nếu input và instruction đã phù hợp, thì output có đúng không?
Sau khi kiểm tra 200 mẫu, thì chỉ có 57% là mẫu đúng, tức thỏa mãn cả 3 điều trên; có 4.5% là instruction sinh ra không hợp logic, hoặc không thực thi được; 17.5% input không hợp với instruction và 21% output không đúng với instruction và input.
Đến đây sẽ có một câu hỏi to lớn khi mà chỉ có thể tin được một nửa số instruction data được sinh ra từ model, ta lại phải ngồi kiểm tra lại dữ liệu sinh ra, rồi ngồi loại bỏ những dữ liệu không đúng, rất mất thời gian và tiền bạc. Tuy nhiên không phải như thế. Đồng ý là garbage in, garbage out, lượng noise trong dữ liệu nhiều như thế rất đáng quan ngại nhưng noise cũng có noise this và noise that.
Xét ví dụ một mẫu bị sai

Mẫu này bị tính là sai vì lý do (2), input không phù hợp với mô tả của instruction. Instruction nói là sẽ có một "list of clues" tuy nhiên trong input thì chỉ có mỗi một clue. Tuy nhiên, output ở trường hợp này vẫn chấp nhận được vì Istanbul (thủ đô của Turkey) là một thành phố nằm ở 2 lục địa là Châu Âu và Á.
Tính đa dạng. Với 200 mẫu mà đã có tới 117 task. Một số task là những task kinh điển trong NLP như Sentiment Analysis, Question Answering, Summarization yada yada... thì lại có rất nhiều task cực kì cụ thể như: phát hiện đây là công thức nấu ăn của món gì khi mà cho một list các nguyên liệu =)))
LLM nhạy cảm với Meta-prompt. Để sinh ra được instruction data, thì ta sẽ phải đưa vào LLM các prompt để chúng sinh ra text đúng với mong muốn của chúng ta. Và như mọi người biết thì chất lượng data sinh ra phụ thuộc rất nhiều vào không chỉ prompt và còn là cả meta-prompt (Hình 13).

Với Text-davinci-002 thì Meta-prompt dạng Enumeration (Bảng 1) sẽ sinh ra data có chất lượng tốt nhất để sử dụng cho T5-11B

Có sử dụng Constraint hay không? Unnatural Instruction có một trường là Constraint thay vì chỉ mỗi Instruction-Input như Self-instruct. Trường này có ảnh hưởng như thế nào đến chất lượng của instruction data được sinh ra? Họ đã làm thêm các thí nghiệm: (1) bảo text-davinci-002 sinh ra constraint khi sinh instruction-input-constraint nhưng lại không sử dụng constraint khi sinh output, chỉ prompt instruction-input thôi và (2) text-davinci-002 chỉ sinh instruction-input chứ không sinh constraint, và instruction-input này được đưa vào để sinh output. Kết quả thể hiện ở Bảng 2.

Có thể thấy rằng, loại bỏ constraint khi sinh output, chỉ đưa vào instruction-input sẽ làm giảm kết quả đi 3 điểm performance. Và constraint cũng ảnh hưởng đến quá trình sinh instruction-input. Loại bỏ constraint khỏi quá trình sinh instruction-input cũng làm giảm kết quả đi 2.2 điểm performance.
Sinh instruction data theo 2 bước. Thay vì sinh instruction-input-constraint rồi mới sinh output thì ta sẽ làm thí nghiệm sinh luôn tất cả cùng một lúc, kết quả thể hiện ở Bảng 3.

Kết
Phía trên là 2 kĩ thuật để mọi người có thể tạo thêm dữ liệu dạng instruction phục vụ cho training các mô hình ngôn ngữ. Về phần pipeline thì không có gì đáng nói, các bạn prompt một mô hình ngôn ngữ to tướng để tạo ra bộ instruction dataset xịn dùng để training mô hình nhỏ hơn của cá nhân chúng ta. Tuy nhiên, các thí nghiệm, phân tích trong bài viết chỉ nói về việc sử dụng GPT-3, Text-davinci-002 để sinh instruction data, và training thì sử dụng T5-11B. Nếu mọi người dùng những model khác để sinh data, hay để training, thì có thể các prompt sử dụng trong bài viết sẽ không đạt được hiệu quả tốt nhất, và lúc này chúng ta cần phải biết cách thay đổi prompt cho phù hợp.
All rights reserved
