
[Paper Explain] RTMDet: YOLO của OpenMMLab
Bài đăng này đã không được cập nhật trong 3 năm
Mở đầu
Mình khá là thích OpenMMLab, một team nghiên cứu đã cung cấp rất nhiều repo tăng tốc các thử nghiệm như MMDetection, MMSegmentation, MMCV,... Đây là lần đầu mình đọc, và phân tích một paper của OpenMMLab. Về cơ bản thì đây chỉ là một họ model Object Detection rất là nhanh, và chính xác gọi là Real-Time Models for Object Detection: RTMDet. Ngoài Object Detection, RTMDet còn có thể thực hiện Real-Time Instance Segmentation, Rotated Object Detection và đạt State-of-the-art cả 2 tác vụ nói trên. Các paper về các phiên bản YOLO (YOLOv6, DAMO-YOLO,...) hay paper này: RTMDet, là các paper rất hay. Nó cho ta thấy rất nhiều khía cạnh khi làm ra một model: Suy nghĩ về kiến trúc, hàm loss, label assignment hay cả những thứ mang tính engineering cực cao như kĩ thuật training, cách sử dụng data augmentation, các kĩ thuật tối ưu,...
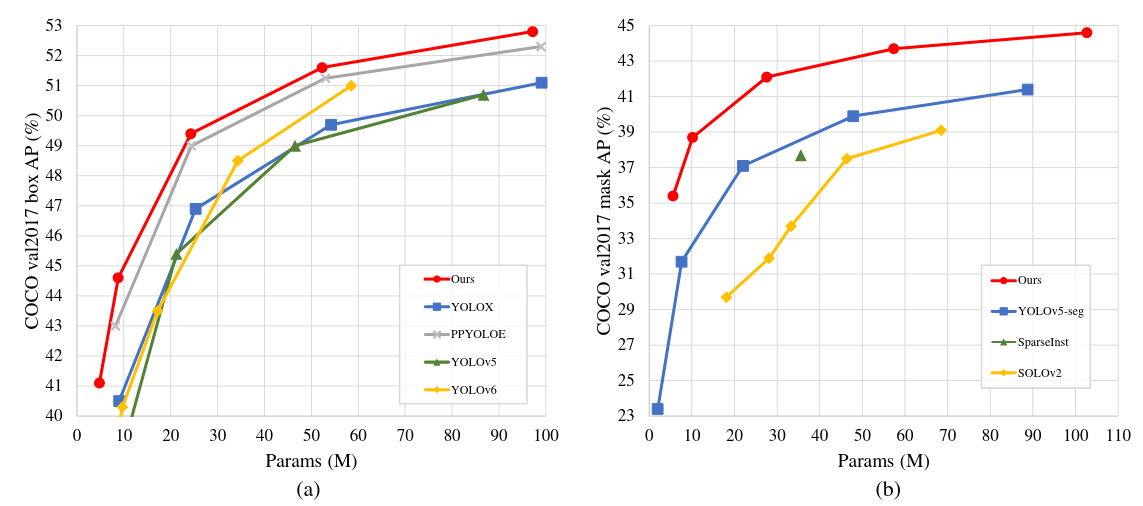
RTMDet
Để tạo ra RTMDet, trước tiên ta sẽ phải cân nhắc về Macro Architecture (Kiến trúc tổng quát). Sau đó, ta khám phá về các block nhỏ, depth và width của model cũng như sự cân bằng tính toán giữa Backbone và Neck. Sau khi kết thúc phần kiến trúc, ta sẽ xét đến Label Assignment (LA) và các kĩ thuật trong training như Data Augmentation, Optimization.
Macro Architecture
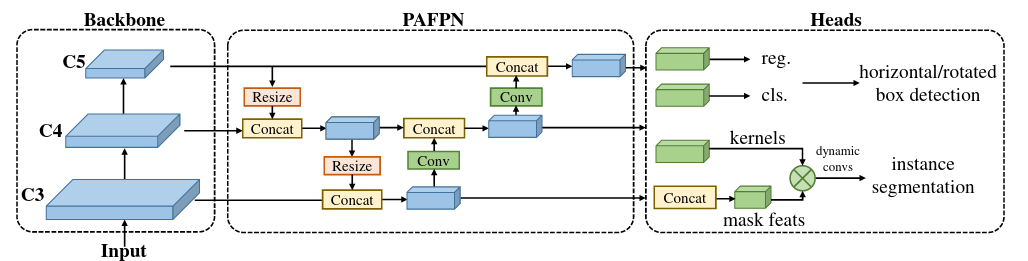
Ta chia một model chính ra làm 3 phần: Backbone, Neck và Heads. Các phiên bản YOLO gần đây (YOLOv4, YOLOv5) sử dụng Backbone là biến thể của CSPDarkNet, bao gồm 4 stage và mỗi stage thì được tạo bởi các block cơ bản như Hình 3. Neck sử dụng kĩ thuật Feature Pyramid, nhận 3 scale từ backbone, và gồm 2 đường top-down và bottom-up của PANet. Head có nhiệm vụ predict Bounding Box và Class của object ứng với mỗi scale. Để xây dựng một Macro Architecture khỏe, ta sẽ xét đến các block cơ bản tạo nên nó, sau đó sẽ cân nhắc đến việc tối ưu Macro Architecture thông qua việc tối ưu depth, width của Backbone và Neck.
Model Architecture
Basic Building Block (Các block cơ bản). Những bài toán dense prediction (Object Detection, Segmentation,...) được cải thiện rất nhiều nếu ta có được Effective Receptive Field (ERF) lớn. Để hiểu hơn về khái niệm Receptive Field hay Effective Receptive Field thì các bạn có thể đọc ở đây. Tuy nhiên, nếu sử dụng những module như Dilated Convolution, hay Non-Local Block (tương tự Self-Attention á) thì tính toán sẽ rất là nặng, và khó để đưa vào Real Time được. Một nghiên cứu gần đây, thay vì sử dụng Dilated Convolution hay Non-Local Block, thì sử dụng Depth-wise Convolution với kernel size lớn và cho thấy độ hiệu quả tuyệt vời trong các bài toán dense prediction. Với Depth-wise, tính toán sẽ không còn quá nặng nữa, các bạn có thể đọc bài phân tích về nghiên cứu đấy tại đây. Vì vậy, nhóm tác giả của RTMDet đã thêm vào trong basic block một Depthwise Conv có kernel size lớn là 5 (thật ra không lớn lắm) để tăng ERF (Hình 3b).
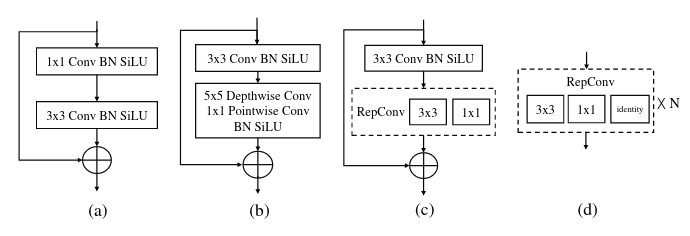
Đáng chú ý rằng có một vài nghiên cứu gần đây đã tận dụng Reparameterized Conv (RepConv) (Hình 3cd) để tăng sức mạnh của model trong lúc inference, tuy nhiên đánh đổi là thời gian training rất lâu. Hơn nữa, khi thực hiện quantization thì model lại tệ đi rất nhiều, và buộc phải sử dụng thêm những kĩ thuật như RepOpt hay Quantization Aware Training. Vì vậy, sử dụng DWConv thì hiệu quả cho training hơn và thân thiện hơn sau Quantization.
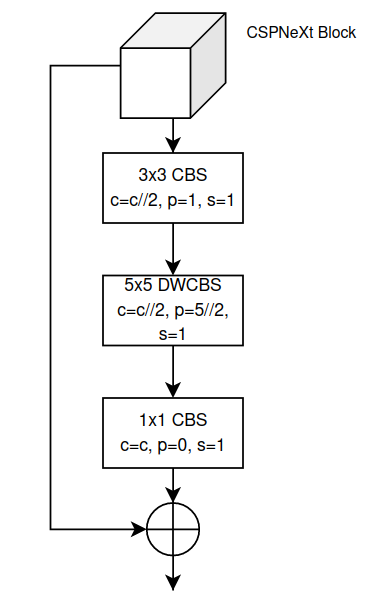
Cụ thể, một block cơ bản của RTMDet, gọi là CSPNeXt sẽ như Hình 4
CSPLayer. Backbone của YOLO, từ YOLOv4, thường sử dụng kĩ thuật CSP để làm giảm độ nặng tính toán. RTMDet sử dụng phiên bản CSP của chính họ. Một CSPLayer sẽ được tạo từ CSPBlock kèm theo Channel Attention. Nếu các bạn chưa rõ về kĩ thuật Attention sử dụng trong Computer Vision, các bạn có thể đọc ở đây. Cấu tạo của một CSPLayer như Hình 5.
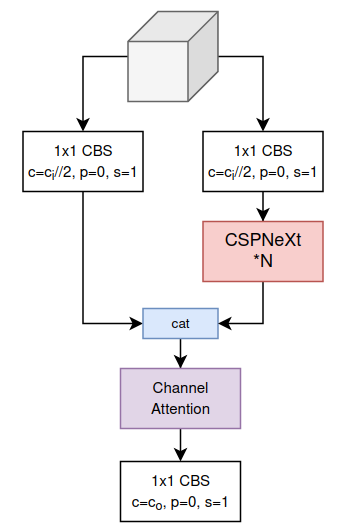
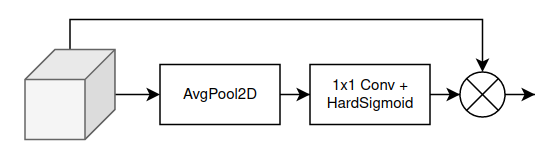
Channel Attention của CSPLayer cực kì đơn giản, có cấu tạo như Hình 6.
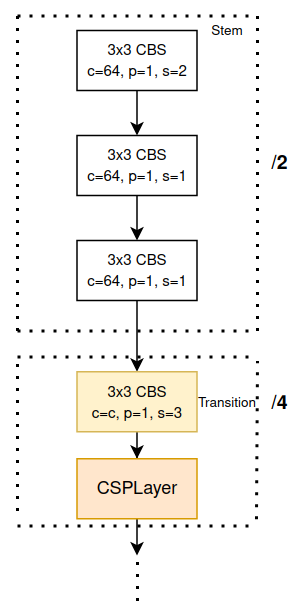
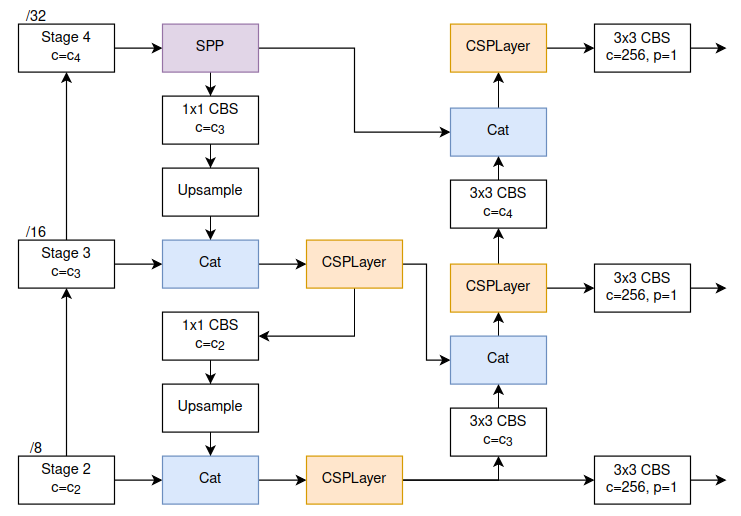
Backbone. Một backbone được tạo nên từ 1 stem và 4 stage đặt liên tiếp nhau. Stem là phần được đặt ở ngay đầu của mạng, và 4 stage sẽ được tạo nên từ các CSPLayer và một Transition Layer. CSPLayer sử dụng để học các đặc trưng cần thiết và Transition Layer dùng để giảm chiều dữ liệu. Cụ thể như Hình 7.
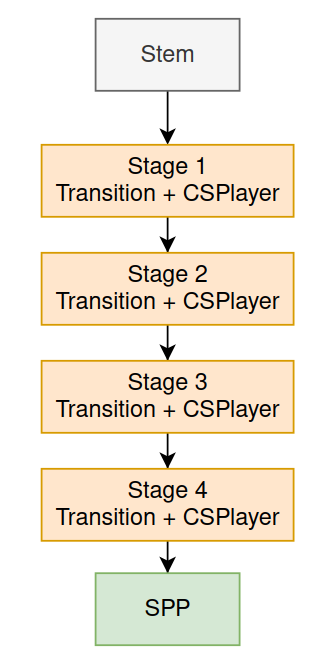
Ở cuối backbone của RTMDet là một SPP y như của YOLOv4. Tóm lại, Backbone của RTMDet được tổng hợp lại ở Hình 8
Neck. Như đã nói bên trên, Neck của RTMDet giống như các phiên bản YOLO khác, gồm 1 đường đi xuống (top-down) và 1 đường đi lên (bottom-up). Nhưng thay vì cứ cho kết nối thẳng với nhau, thì RTMDet còn sử dụng thêm CSPLayer để xử lý. Nhìn chung là giống với neck của YOLOv7, tuy nhiên module xử lý trong Neck của RTMDet (CSPLayer) khác với của YOLOv7 (CSP-OSA), và module down sample ở trong bottom-up cũng khác ( CBS vs Transition). Các bạn có thể xem Neck của YOLOv7 ở đây. Neck của RTMDet có kiến trúc như ở Hình 9.
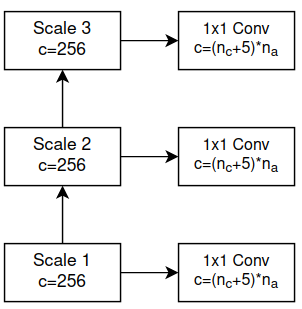
Head. Ở các phiên bản YOLO thông thường, object được predict ở 3 scale khác nhau và mỗi scale sẽ có một Head tương ứng cho scale đó. Head này sẽ đảm nhiệm cả Classification, Regression và Objectness (Hình 10).
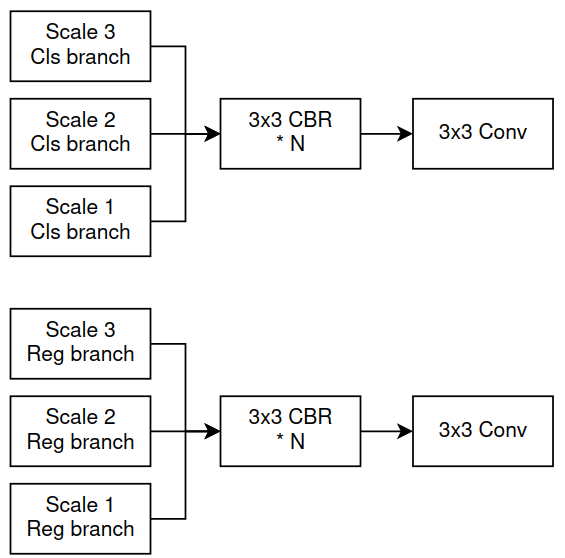
Còn với những model Object Detection khác, như RetinaNet, FCOS,... 3 scale sẽ chỉ sử dụng chung một Head, và chia ra làm 2 nhánh (De-coupled Head được nhắc tới trong YOLOX) để thực hiện Classification và Regression riêng (Hình 10)
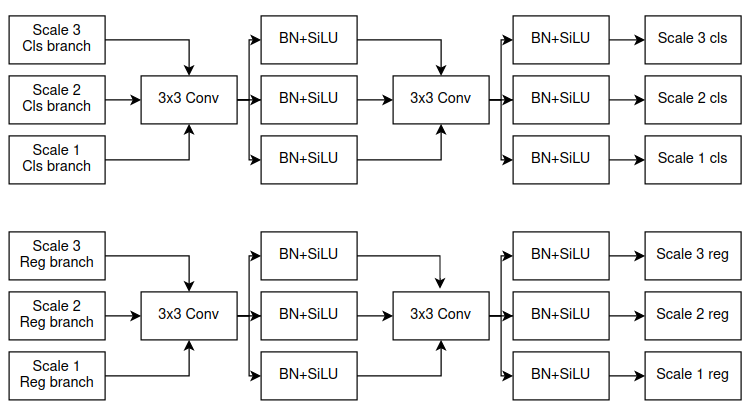
RTMDet sử dụng Decoupled Head, chung lớp Conv cho cả 3 scale, tuy nhiên, lại sử dụng 3 lớp BN riêng biệt cho 3 Scale (Hình 11). Việc này có 2 lợi ích: (1) việc sử dụng Decoupled Head sẽ khiến model có độ chính xác cao hơn, tuy nhiên để Head không bị tính toán quá nặng, ta sử dụng chung các lớp Conv cho cả 3 Scale như Hình 10. Điều này lại khiến việc xác định object ở các scale khác nhau khó hơn nên, (2) với việc có các lớp BN riêng biệt ta sẽ phần nào làm giảm sự khó khăn khi xác định object ở các scale khác nhau
Training Strategy
Label assignment (LA) và Loss. Có rất nhiều những kĩ thuật Label Assignment được phát triển trong thời gian qua, và 2 cái đáng chú ý nhất gần đây chính là OTA/simOTA được YOLOv7, YOLOX sử dụng, cái còn lại là TAL được sử dụng trong YOLOv6, YOLOv8 và PPYOLOE.
RTMDet sử dụng một biến thể tự chế từ simOTA. RTMDet nhận thấy rằng, quá trình tính cost để chọn ra positive anchor của simOTA có hơi thiếu sót. Cost function mới được thay đổi như sau:
Với là Classification cost, Center Prior cost và Regression cost.
Nhắc lại một chút, ở simOTA có cái gọi là Center prior, khiến cho anchor nằm tập trung ở phần center của object. Tuy nhiên, simOTA lại coi các anchor gần center là như nhau. Còn ở RTMDet, các khác nhau sẽ có Center Prior cost là khác nhau. Center Prior cost sẽ được tính như sau:
Với và
Với Classification cost, RTMDet sử dụng Quality Focal Loss thay vì Binary Cross Entropy loss như YOLOX, đây là lý do tại sao RTMDet không có nhánh Objectness. Còn Regression cost thì sử dụng giống như YOLOX.
Cached Mosaic và MixUp. Các kĩ thuật data augmentation như Mosaic và MixUp được sử dụng rất nhiều trong Object Detection. 2 kĩ thuật này rất mạnh tuy nhiên nó có 2 nhược điểm:
- Ở mỗi iteration, ta cần phải tìm các ảnh khác nhau, xếp chúng vào với nhau để tạo thành một training sample data loading cost lớn quá trình training bị chậm đi
- Training sample được tạo ra khá noisy và có thể không nằm trong phân phối của dataset. Điều này đã được kiểm chứng từ YOLOX
RTMDet cải tiến Mosaic và MixUp sử dụng cơ chế caching để giảm data loading cost. Quá trình cache được điều chỉnh thông qua độ dài cache và popping method (cách chọn ảnh). Độ dài cache cực lớn và popping method là random thì sẽ trở về Mosaic/ MixUp thông thường. Còn độ dài cache bé và First-In-First-Out (FIFO) popping method sẽ cho phép Mix cùng một ảnh nhưng với loại data augmentation khác nhau của ảnh đó.
Two-stage training. Để giảm thiểu sự noisy của training sample do Mosaic và MixUp, YOLOX đã sử dụng chiến thuật training 2 bước: Bước đầu dùng các augmentation mạnh như Mosaic và MixUp, còn bước sau thì dùng augmentation yếu. Các augmentation mạnh bao gồm cả random rotation và shear, sẽ khiến ảnh object và bounding có một chút lệch nhau, do đó trong stage 2, YOLOX còn thêm vào L1 Loss để fine-tune nhánh Regression.
RTMDet chọn không sử dụng rotation và shear trong stage 1, kéo dài trong 280 epochs. Ở stage 2 (20 epochs cuối), RTMDet sử dụng Large Scale Jittering (LSJ) [1]. Để quá trình training ổn định hơn, thay vì dùng optimizer là SGD như các model khác, RTMDet sử dụng AdamW, optimizer thường thấy ở trong các model Transformer thay vì CNN.
Kết quả
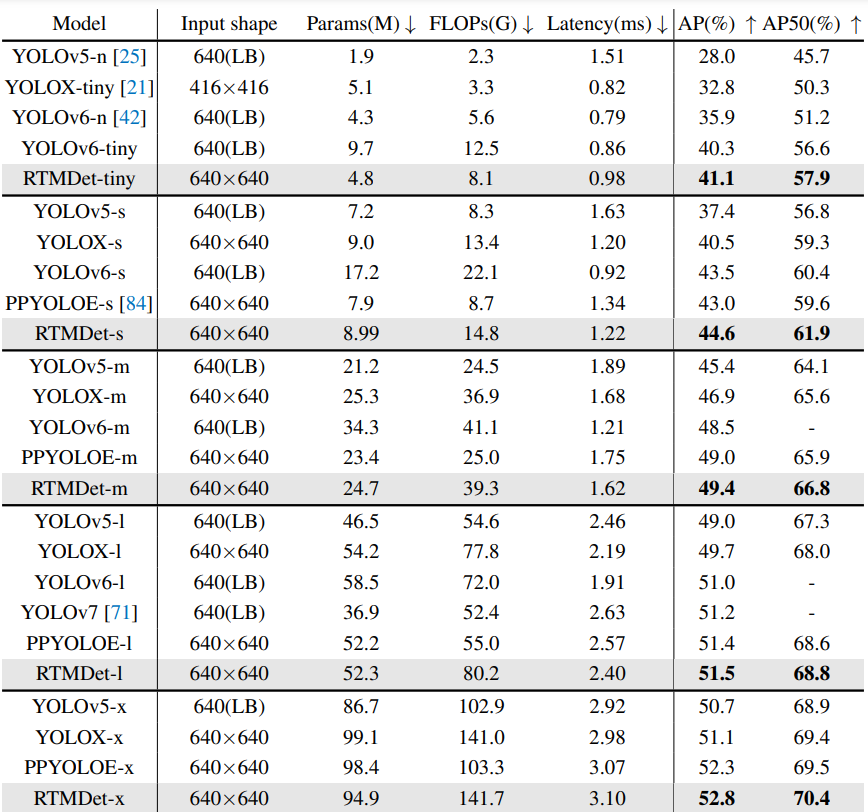
Ablation Study
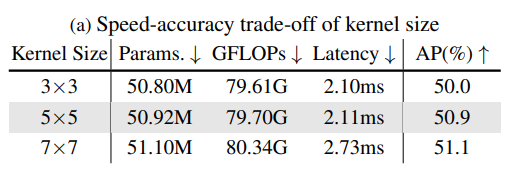
CSPNeXt Block. Ở phần có nói rằng sử dụng Depth-wise Conv với kernel size lớn thì sẽ mang lại kết quả tốt hơn trên các Dense Prediction task. Thế tại sao lại chỉ sử dụng kernel ? Đơn giản là vì tốc độ (Bảng 1). Khi tăng kernel size lên, kết quả có tăng nhưng không quá nhiều, và không đáng để đánh đổi tốc độ.
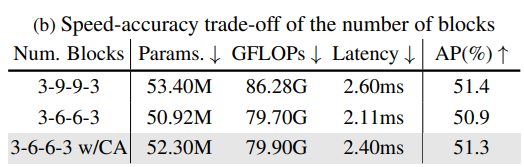
Số lượng block ở từng stage. Ở những model khác, ta thường thấy stage 2 và 3 sẽ có khá nhiều block. Tuy nhiên, với việc sử dụng Depth-wise Conv, tức là mỗi block đã phải thêm 1 layer khá là không hiệu quả về tốc độ rồi, nên ta giảm số lượng block ở trong stage 2 và 3 của RTMDet xuống. Việc này làm của RTMDet giảm kha khá. Tuy nhiên, với việc thêm Channel Attention vào cuối mỗi stage, thì kết quả lại khá là ổn, và tốc độ cũng tốt (Bảng 2).
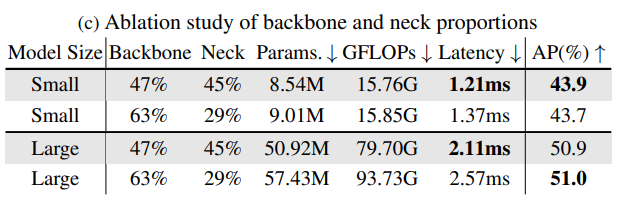
Cân bằng Backbone và Neck. Ở những model Object Detection khác, để tăng hiệu năng của model (từ ) thì ta thường sử dụng kĩ thuật model scaling và chỉ áp dụng lên backbone. Tuy nhiên, RTMDet nhận thấy rằng, bằng việc giảm computation của Backbone, và thêm vào Neck, thì kết quả sẽ tốt hơn cả về tốc độ và độ chính xác (Bảng 3).
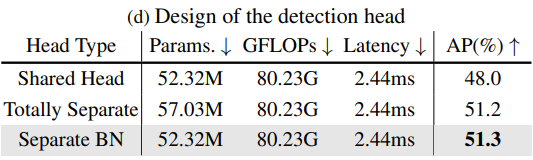
Head. Head của RTMDet là Decoupled Head, tuy nhiên lại tách BN ra riêng cho từng scale. Các thí nghiệm ở Bảng 4 cho thấy, dùng BN chung vào sẽ giảm hiệu quả của model.
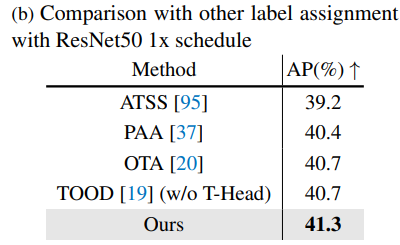
Label Assignment. Kết quả ở Bảng 5, LA tự chế của RTMDet có hiệu quả khá là tốt.
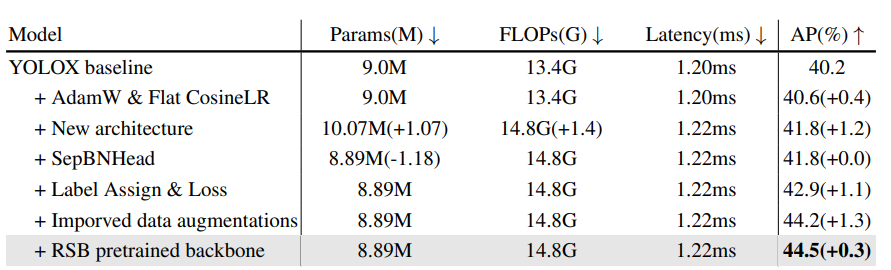
Quá trình biến đổi từ YOLOX sang RTMDet. Thể hiện ở Bảng 6
All rights reserved
