
[Paper Explain] Mixtral of Experts: Lắm thầy thì model khỏe
Bài đăng này đã không được cập nhật trong 2 năm
Mở đầu
Với những người sử dụng Large Language Model (LLM), hẳn cái tên Mixtral 8x7B đã không còn xa lạ gì nữa. Nhưng có ai thắc mắc tại sao lại là "8x7B" chứ không phải là 56B hay 7B như các model khác? Bài viết này sẽ giải đáp về cái tên của Mixtral 8x7B, cũng như là kĩ thuật mà mà Mixtral 8x7B đã sử dụng: Mixture of Experts (MoE).
Nhìn lại một chút về Transformer
Chắc hẳn bây giờ ai cũng đã biết về Transformer. Và nhắc đến Transformer thì mọi người hay nghĩ tới Self-Attention, thành phần chính của Transformer. Tuy nhiên, model Transformer thì được tạo thành từ việc xếp chồng các Transformer Block (Hình 1) lên nhau, và ta có thể thấy, ngoài Self-Attention thì còn một thành nữa cũng quan trọng không kém: Feed Forward Network (FFN)
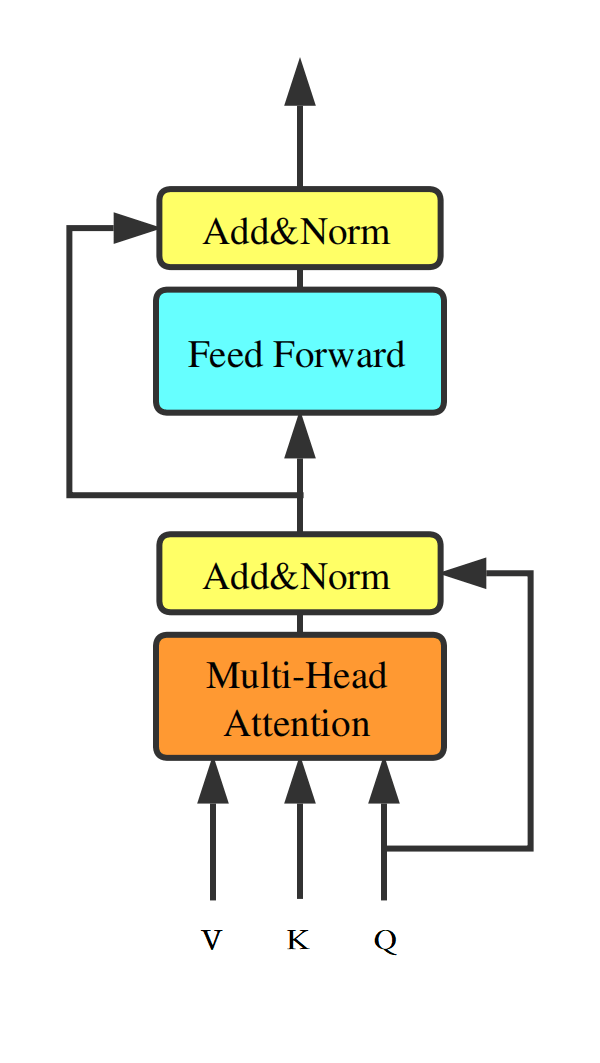
Và cách làm việc của FFN được thể hiện ở Hình 2. FFN sẽ nhận một sequence có độ dài , biến đổi thành độ dài , rồi trở lại độ dài
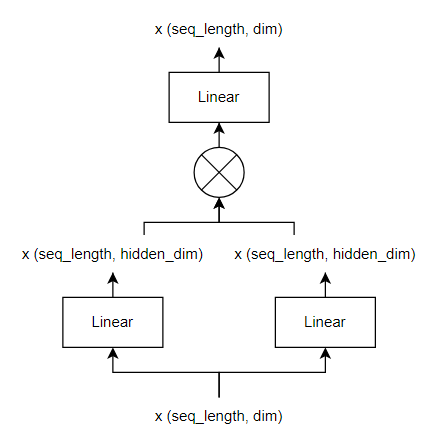
Khi scale một LLM lên, ví dụ từ 7B 70B, ngoài việc tăng số lượng Transformer Block lên, thì ta còn tăng cả và . Và khi chúng tăng lên, thì số lượng parameters ở FFN sẽ trở nên cực kì lớn. Thế nên, việc giảm số lượng parameters ở FFN là điều cần thiết.
Hơn nữa, mọi token trong một sequence sẽ đều đi qua một FFN cố định, tức là mỗi token đều được đối xử như nhau. Vậy nên thay vì có một FFN, ta sẽ có nhiều FFN, và làm nó như kiểu Multi-head FFN?
Mixture of Experts
Khái quát
Mixture of Expert (MoE) là câu trả lời cho cả 2 vấn đề vừa nêu ra ở phần trên.
Để giảm số lượng parameters ở FFN, ta sẽ sử dụng một khái niệm mới: sparsity. Trong trường hợp này có nghĩa là, với một input được đưa vào, ta không phải sử dụng toàn bộ parameters của model để thực hiện inference, mà ta sẽ chỉ sử dụng một phần parameters của model. Nhìn vào Hình 3, ta có 4 FFN, tuy nhiên, ta sẽ chỉ thực hiện inference với một FFN được chọn.
Tăng số lượng FFN lên để làm nhiều heads, lúc này mỗi FFN sẽ được gọi là một expert. Đi kèm theo đó sẽ là một router để xác định xem là token này nên được đưa vào expert nào. Kiến trúc của một MoELayer được thể hiện ở Hình 3.
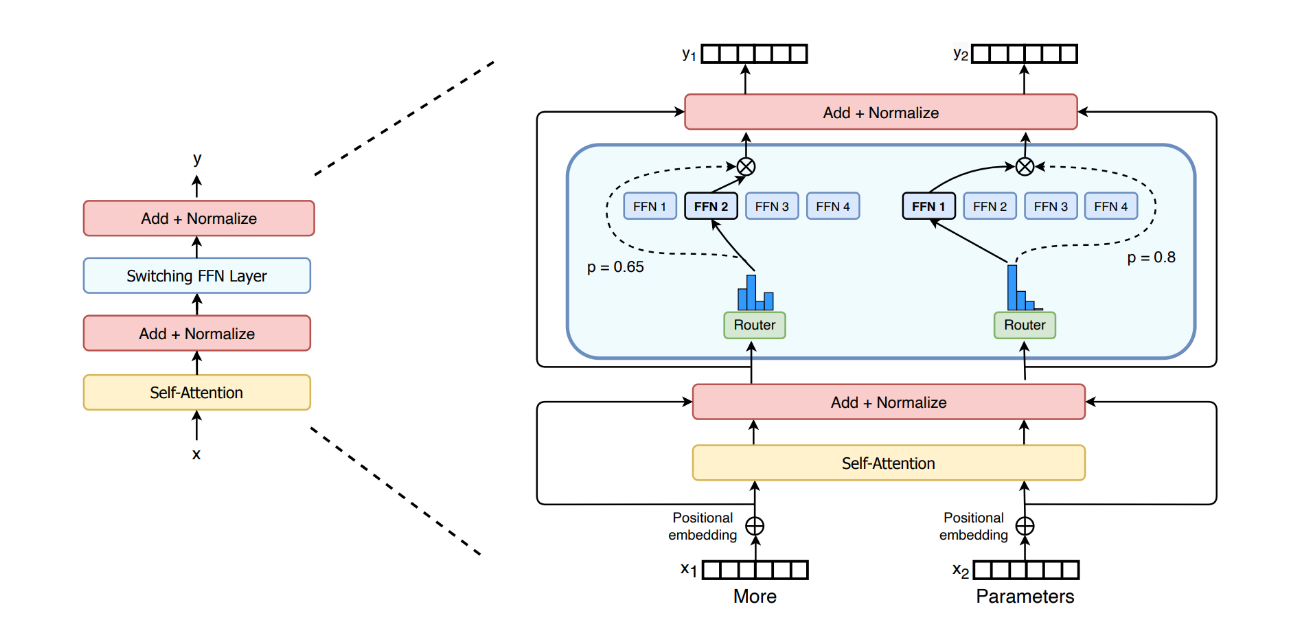
Cụ thể
Ý tưởng của MoE chỉ đơn giản tóm gọn lại ở phần trên, phần này sẽ trình bày chi tiết hơn một chút về mặt toán học của MoE, mọi người hoàn toàn có thể bỏ qua phần này nếu muốn. Và ở đây, mình sẽ giải thích về MoE được sử dụng ở trong Mixtral 8x7B.
Mixtral là một model Transformer với 32k context length, tuy nhiên, FFN Layer được thay thế bởi MoELayer. Kiến trúc model của Mixtral ở dưới Bảng 1.

Output của MoELayer khi nhận một input sẽ là tổng trọng số (weighted sum) các output của các experts, với việc trọng số sẽ được quyết định bởi một Gating Network. Với experts , output của expert layer được tính như sau:
là output của Gating Network cho expert thứ , và là output của expert thứ
Nếu vector output của Gating Network là sparse (tức là chỉ có 1 số thành phần khác 0), ta sẽ có thể bỏ qua được việc tính toán các experts mà có Gating score là 0. Có nhiều cách để tạo , tuy nhiên Mixtral chọn cách đơn giản là sử dụng softmax lên top-k output logits từ một FC layer, cụ thể:
Với nếu nằm trong giá trị lớn nhất của vector logit , và nếu ngược lại. Ở đây là một hyper-parameters để kiểm soát số lượng experts sử dụng cho một token trong sequence. Nếu ta tăng số lượng , tức là tăng số lượng experts, mà vẫn giữ nguyên số lượng , tức là giữ nguyên số lượng experts dùng cho một token, thì ta sẽ tăng số lượng parameters tổng của model, tuy nhiên số lượng parameters dùng cho tính toán thì không đổi. Và như Bảng 1, Mixtral chỉ sử dụng experts cho từng token và sử dụng experts. Số lượng parameters tổng của Mixtral 8x7B không phải là 56B, mà lại là 47B (vì chỉ MoE các FFN thôi), và số lượng parameters sử dụng trong lúc inference chỉ có 13B thôi.
Expert Parallelism
 Phần này chỉ dành cho các máy có nhiều hơn 1 GPU
Phần này chỉ dành cho các máy có nhiều hơn 1 GPU
Áp dụng kĩ thuật model parallelism lên các expert, ta sẽ chia các expert vào các GPU khác nhau. Trong quá trình tính toán expert, output của Gating Network sẽ chia token cho expert ở GPU thì token đó sẽ được đưa từ GPU ban đầu sang GPU có chứ expert đó, sau khi tính toán xong thì token đó lại được trả về GPU ban đầu
Tổng kết
Phía trên là cách hoạt động của Mixture of Expert (MoE) cũng như là Mixtral 8x7B
All rights reserved
