
Data Visualization với thuật toán t-SNE sử dụng Tensorflow Projector
Bài đăng này đã không được cập nhật trong 7 năm
Data Visualization với thuật toán t-SNE sử dụng Tensorflow Projector
-
Data Visualization là một trong những kĩ năng quan trọng đòi hỏi các Data Science hoặc BI Analysis phải xử lí thành thạo và trau dồi kĩ năng hàng ngày. Với tiêu chí "Learn by doing", trong bài blog lần này, mình sẽ giới thiệu và hướng dẫn cho các bạn sử dụng Tensorflow Projector để visual trên tập dữ liệu embedding với thuật toán t-SNE.
-
Thành quả đạt được sau khi các bạn hoàn thành bài tutorial này: https://huyhoang17.github.io/Visual_Embedding_Tutorial
-
Link Github: https://github.com/huyhoang17/Visual_Embedding_Tutorial
-
Các bước thực hiện:
- Chuẩn bị dữ liệu
- Huấn luyện mô hình
- Trich rút đặc trưng
- Giảm chiều dữ liệu
- Cấu hình file config cho tensorflow projector
- Deploy sử dụng github page
- Sử dụng Tensorflow Projector cho project của bạn
Chuẩn bị dữ liệu (Data Preparation)
-
Tập dữ liệu mình sử dụng là MNIST, bao gồm các ảnh chữ số viết tay, gồm 10 class, từ 0 đến 9. Training data bao gồm 60.000 ảnh, testing data bao gồm 10.000 ảnh.
-
Tiền xử lí cho tập dữ liệu ảnh, ở đây mình load dữ liệu MNIST từ keras framework
from keras.datasets import mnist
(X_train, y_train), (_, _) = mnist.load_data()
y_train = np_utils.to_categorical(y_train, 10)
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_train /= 255
Huấn luyện mô hình (Training Model)
- Về phần model cũng không có gì quá phức tạp, mình sử dụng 1 mạng CNN cơ bản. Đầu ra của mạng với 10 node, sử dụng Softmax thể hiện phân phối theo xác suất ứng với từng class:
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=[28, 28, 1]))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
-
Về phần
fetchdữ liệu, mình có viết 1 hàmdata_generatorreturn vềgenerator object. Đối với tập dữ liệu tương đối nhỏ như MNIST, các bạn có thể sử dụng luôn methodfittrongkeras, nhưng đối với các bài toán đặc thù hơn, khi mà lượng dữ liệu đa dạng và phong phú hơn thì việc viết code theo kiểu.fitlà hoàn toàn không phù hợp. Trong 1 bài blog sắp tới, mình sẽ đề cập tới vấn đề này và 1 vài cách custom data generator trong keras. -
Chú ý: thực ra trong code các bạn thấy mình vẫn lưu giữ toàn bộ data trong 1 numpy array
X_train, nhưng trong thực tế các bạn không cần thiết và không phải làm như vậy. Chỉ nên load dữ liệu theo từng batch, train tới đâu load tới đó. Ở đây mình chỉ minh họa về cách viết data generator trong keras mà thôi!
def data_generator():
(X_train, y_train), (X_test, y_test) = mnist.load_data()
y_train = np_utils.to_categorical(y_train, 10)
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
while True:
for i in range(1875): # 1875 * 32 = 60000 -> # of training samples
if i % 125 == 0:
print("i = {}".format(str(i)))
# (32, 1, 28, 28), (32, 10)
yield X_train[i * 32:(i + 1) * 32], y_train[i * 32:(i + 1) * 32]
- Training mô hình
model.compile(
loss='categorical_crossentropy', optimizer='adadelta',
metrics=['accuracy']
)
model.fit_generator(
data_generator(), steps_per_epoch=60000 // 32, nb_epoch=10,
validation_data=None
)
model.save_weights('../models/best_weight.h5')
json_string = model.to_json()
with open('../models/config.json', 'w') as f:
f.write(json_string)
- Kết quả thu được sau khi huấn luyện mô hình với 10 epochs
...
Epoch 10/10
115/1875 [>.............................] - ETA: 1:07 - loss: 0.0105 - acc: 0.9967
240/1875 [==>...........................] - ETA: 1:03 - loss: 0.0113 - acc: 0.9965
364/1875 [====>.........................] - ETA: 58s - loss: 0.0104 - acc: 0.9972
490/1875 [======>.......................] - ETA: 53s - loss: 0.0096 - acc: 0.9972
614/1875 [========>.....................] - ETA: 48s - loss: 0.0088 - acc: 0.9975
740/1875 [==========>...................] - ETA: 43s - loss: 0.0084 - acc: 0.9974
865/1875 [============>.................] - ETA: 40s - loss: 0.0094 - acc: 0.9972
989/1875 [==============>...............] - ETA: 35s - loss: 0.0090 - acc: 0.9973
1115/1875 [================>.............] - ETA: 31s - loss: 0.0094 - acc: 0.9971
1240/1875 [==================>...........] - ETA: 26s - loss: 0.0095 - acc: 0.9971
1365/1875 [====================>.........] - ETA: 21s - loss: 0.0097 - acc: 0.9971
1489/1875 [======================>.......] - ETA: 17s - loss: 0.0093 - acc: 0.9971
1615/1875 [========================>.....] - ETA: 11s - loss: 0.0090 - acc: 0.9972
1739/1875 [==========================>...] - ETA: 6s - loss: 0.0090 - acc: 0.9973
1864/1875 [============================>.] - ETA: 0s - loss: 0.0085 - acc: 0.9973
1875/1875 [==============================] - 84s 45ms/step - loss: 0.0088 - acc: 0.9973
Trích rút đặc trưng (Feature Extraction)
- Trong một bài blog gần đây của mình về Semantic Search, mình cũng đã nói khá rõ về Feature Extraction trong Deep Learning. Cụ thể với mô hình trong bài này, mình sử dụng fully connected layer ngay trước Softmax làm Feature Extraction. Điều đó có nghĩa, mỗi ảnh đầu vào sẽ được biểu diễn bằng 1 vector 4096 chiều (4096D). Có một chú ý là lần này mình chỉ sử dụng 10.000 sample để predict, quá nhiều sample dẫn tới việc tính toán và visual trên browser khá lâu. Code mình họa:
from keras.models import model_from_json, Model
(X_train, y_train), (_, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_train /= 255
ids = random.sample(range(0, 60000), 10000)
X_train = X_train[ids]
y_train = y_train[ids]
with open('../oss_data/MNIST_labels.tsv') as f:
for label in y_train:
f.write(str(label) + '\n')
model = model_from_json(config)
model.load_weights('../models/best_weight.h5')
new_model = Model(model.inputs, model.layers[-3].output)
new_model.set_weights(model.get_weights())
embs_4096 = new_model.predict(X_train) # (10000, 4096)
...
Giảm chiều dữ liệu (Dimension Reduction)
- Một vấn đề nữa là một ảnh MNIST hiện tại được biểu diễn bởi 1 vector 4096D, 1 con số khá lớn. Do đó, mình dùng thuật toán PCA, giảm chiều dữ liệu về còn 128, thuận tiện cho việc tính toán sau này:
from sklearn.decomposition import PCA
...
pca = PCA(n_components=128)
embs_128 = pca.fit_transform(embs_4096) # (10000, 128)
Cấu hình file config cho tensorflow projector (Setup Tensorflow Projector config)
- Repo chính của tensorflow projector đã cung cấp sẵn 1 file index.html, bao gồm cả code Javascript thực hiện việc tính toán và visual mô hình, nên các bạn chỉ cần clone về và sử dụng mà thôi. Nhưng như thế chưa đủ, chúng ta cần định nghĩa 1 file json config bao gồm các thông số như bên dưới:
{
"embeddings": [
{
"tensorPath": "oss_data/MNIST_tensor.bytes",
"tensorShape": [
10000,
128
],
"metadataPath": "oss_data/MNIST_labels.tsv",
"tensorName": "MNIST2Vec",
"sprite": {
"imagePath": "oss_data/MNIST_sprites.png",
"singleImageDim": [
28,
28
]
}
}
],
"modelCheckpointPath": "Visual Vector Embedding"
}
-
tensorShape: kích thước của ma trận đầu raembs_128, thông số này chỉ dùng để hiển thị metadata trên tensorflow projector. -
tensorName: tên của mô hình, các bạn đặt thế nào cũng được -
metadataPath: file chứa label dữ liệu, cùng order vớiembs_128, mỗi dòng 1 label. Code minh họa:
...
y_train = y_train[ids]
with open('../oss_data/MNIST_labels.tsv') as f:
for label in y_train:
f.write(str(label) + '\n')
tensorPath: lưu giữ embedding array của dữ liệu. Được tạo ra bằng đoạn code như bên dưới, chú ý kiểu dữ liệu của từng biến, ở đây mình đều sử dụngnp.float32:
...
embs_128.tofile('../oss_data/MNIST_tensor.bytes')
- Và cuối cùng,
sprite: là ảnh tổng hợp ghép bởi nhiều ảnh con. Mình sử dụng 10000 để visual nên ảnhspritetạo ra sẽ có kích thước 100 ảnh x 100 ảnh. Code minh họa tạosprite image(chú ý:singleImageDimphải để chính xác kích thước ảnh):
def images_to_sprite(data):
"""
Creates the sprite image
:param data: [batch_size, height, weight, n_channel]
:return data: Sprited image::[height, weight, n_channel]
"""
if len(data.shape) == 3:
data = np.tile(data[..., np.newaxis], (1, 1, 1, 3))
data = data.astype(np.float32)
min = np.min(data.reshape((data.shape[0], -1)), axis=1)
data = (data.transpose(1, 2, 3, 0) - min).transpose(3, 0, 1, 2)
max = np.max(data.reshape((data.shape[0], -1)), axis=1)
data = (data.transpose(1, 2, 3, 0) / max).transpose(3, 0, 1, 2)
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = ((0, n ** 2 - data.shape[0]), (0, 0),
(0, 0)) + ((0, 0),) * (data.ndim - 3)
data = np.pad(data, padding, mode='constant',
constant_values=0)
data = data.reshape((n, n) + data.shape[1:]).transpose(
(0, 2, 1, 3) + tuple(range(4, data.ndim + 1))
)
data = data.reshape(
(n * data.shape[1], n * data.shape[3]) + data.shape[4:])
data = (data * 255).astype(np.uint8)
return data
- và tiến hành lưu lại ảnh trong folder
oss_data:
import scipy.misc
...
simg = images_to_sprite(X_train) # X_train: 10000 samples
scipy.misc.imsave('../oss_data/MNIST_sprites.png', np.squeeze(simg))
- Kết quả thu được 1 ảnh
spritesnhư vậy
![]()
Deploy sử dụng github page (Deploy with github page)
- Như link demo các bạn thấy ở đầu blog, mình sử dụng github page để deploy mô hình của mình. Sau khi đã hoàn tất các công đoạn bên trên, nếu muốn test thử trên máy, các bạn thực hiện như sau:
python3 -m http.server
# hoặc clone repo cuả mình về và thực hiện
git clone git@github.com:huyhoang17/Visual_Embedding_Tutorial.git
cd Visual_Embedding_Tutorial
python3 -m http.server
-
và truy cập vào đường dẫn localhost: 127.0.0.1:8000. Chọn tab t-SNE và cho chạy khoảng 200 iterations sẽ thấy dữ liệu của mình được phân cụm khá rõ. Những ảnh thuộc cùng 1 class sẽ ở gẩn nhau và thuộc cùng 1 cụm, tách biệt hẳn với các class khác.
-
Hoặc các bạn cũng có thể upload code lên github, tạo mới 1 branch tên
gh-pagesvà push code lên branch đó. Khi đó, mặc định github sẽ serving mô hình của bạn tại đường dẫn: https://username-here.github.io/project-name. Vậy là xong! -
Các bạn có thể để ý thấy 1 vài chi tiết thú vị như: class 7 được phân cụm thành 2 phần khá tách biệt, 1 cụm gồm các hình số 7 hai nét, 1 cụm ba nét chẳng hạn, .. =D
Sử dụng Tensorflow Projector cho project của bạn (Custom Tensorflow Projector)
-
Trên đây là bài hướng dẫn sử dụng Tensorflow Projector trên tập dữ liệu MNIST của mình. Các bạn hoàn toàn có thể sáng tạo và áp dụng thêm vào các tập dữ liệu embedding khác nhau, hi vọng giúp ích cho các bạn
-
Đây là 1 link demo khác mình sử dụng Tensorflow Projector: https://huyhoang17.github.io/128D-Facenet-LFW-Embedding-Visualisation cho project Face Recognition hồi trước. Tập dữ liệu sử dụng là LFW (Label Face in the Wild), mỗi ảnh mặt người sau khi đi qua model sẽ được biểu diễn bởi 1 vector 128 chiều (128D), 1 người có nhiều ảnh. Các bạn chọn tab t-SNE và cho chạy khoảng 200 iterations sẽ thấy phân cụm khá rõ rệt, các ảnh của cùng 1 người sẽ ở gần nhau và thuộc cùng 1 cụm:
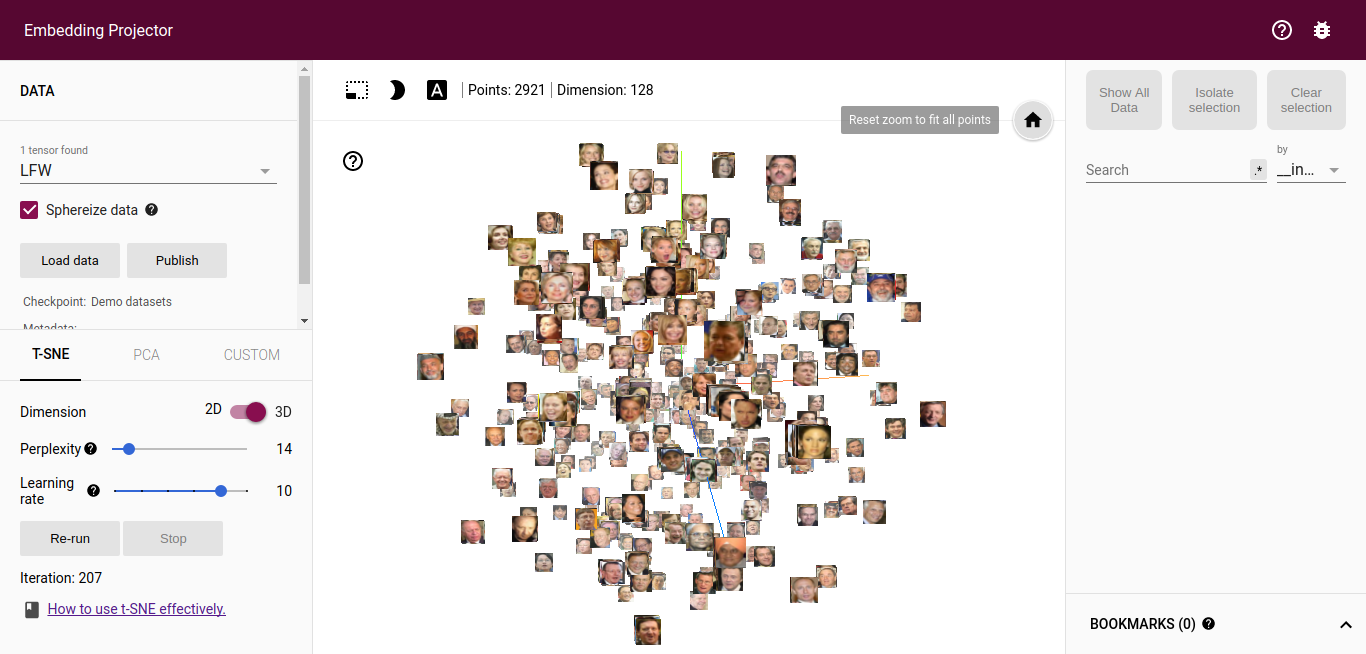
- Hãy upvote và star repo của mình nếu hữu ích với các bạn nhé! Xin chào và hẹn gặp lại trong các bài blog tiếp theo!
Reference
All rights reserved
