
[B5'] Piracy Resistant Watermarks for Deep Neural Networks
Bài đăng này đã không được cập nhật trong 6 năm
Đây là một bài trong series Báo khoa học trong vòng 5 phút.
Nguồn
Được viết bởi Li et. al, University of Chicago. Hiện vẫn là preprint.
https://people.cs.uchicago.edu/~huiyingli/publication/watermark.pdf
Có một phiên bản slide tại đây, tuy nhiên đọc cũng khá khó hiểu nên cũng đừng cố quá.
Ý tưởng chính
Paper nói về cách làm thế nào có thể chứng minh rằng một model của mình. Cụ thể, chúng ta bắt đầu bằng cách ký một chuỗi nào đó với chữ ký riêng (private key) của mình - đương nhiên có thể thấy là chỉ có ta mới có thể tạo lại ra lại cái cryptographic signature đó.
Sau đó, với chữ ký đó, chúng ta thả qua vài hàm hash để ra các giá trị không thể đảo ngược để giả mạo. Các giá trị hàm băm đó sẽ được sử dụng để tạo ra một cái watermark nho nhỏ gọi là null embedding và nơi đặt nó:
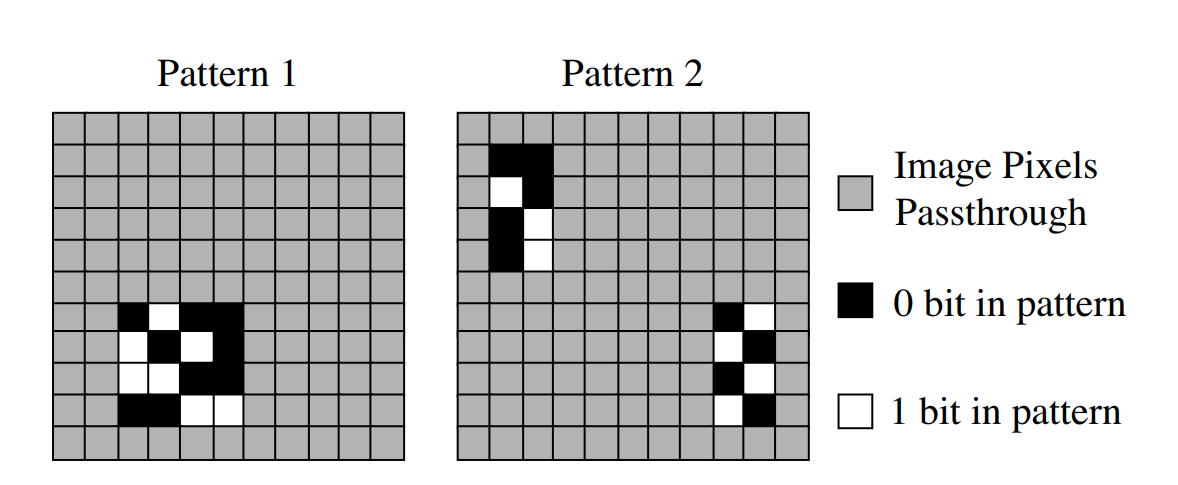
Đồng nghĩa, là chỉ có tác giả mới có thể nhúng một ảnh mới vào watermark. Ngoài null embedding ra, tác giả còn tạo một pattern khác gọi là true embedding: về cơ bản là ngược lại của null embedding:
true_embedding = -null_embedding
và sẽ được nhúng vào cùng vị trí mà null embedding sẽ được gán. Những ví dụ đã được nhúng true embedding sẽ là các backdoor của mô hình này, và sẽ phải predict ra một class cũng được xác định bằng chữ ký sau băm. Cuối cùng, mô hình sẽ được dạy một lúc cả 3 task sau:
- Với data gốc, mô hình phải predict ra đúng ground truth.
- Với data kèm null embedding: mô hình cũng phải predict ra đúng ground truth.
- Với data kèm true embedding: mô hình phải predict ra một backdoor class .
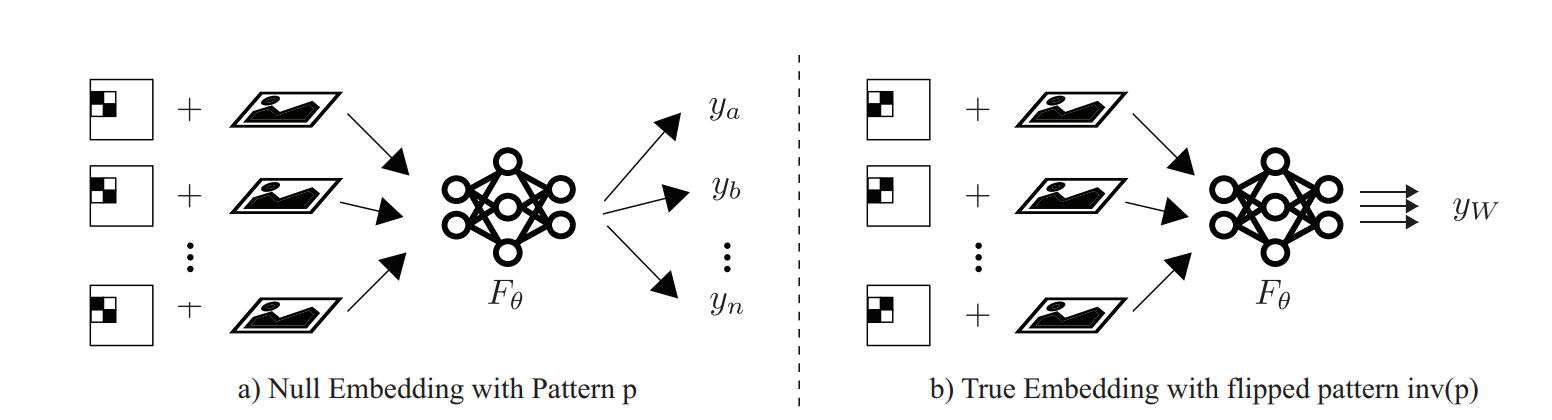
Sau khi làm thế này, mô hình sẽ học được phân bố của các data được chiếu xuông vùng có liên quan chặt chẽ với pattern watermark trên. Từ đó, nếu kẻ tấn công muốn xóa hoặc ghi đè watermark, chất lượng của mạng sẽ bị ảnh hưởng nặng nề.
Trong 3 task đó, 2 task sau không thể bỏ cái nào, vì:
- Nếu bỏ true embedding đi, thì mạng sẽ học là có watermark hay không sẽ cho cùng kết quả, và nghĩa là vùng đó không có gì có ý nghĩa cả. Từ đó, mạng sẽ không quan tâm đến vùng có watermark.
- Nếu bỏ null embedding đi, cấu trúc mạng sẽ giống với Zhang et. al mà mình đã viết ở đây. Trong paper này, tác giả cho biết phương pháp này bị detect và ghi đè watermark dễ dàng bằng Neural Cleanse, một paper khác tác giả có tham gia viết.
Đồng thời với khá nhiều thí nghiệm, tác giả kết luận là nhúng watermark theo phương pháp này không thể bị tấn công bằng xóa/ghi đè watermark, pruning, fine-tuning, hay knowledge distillation.
Các bước implementation (kèm code)
Việc đầu tiên là chúng ta cần lấy ra chữ ký của một message gì đó bằng chữ ký bí mật của bạn:
printf "<message_ở_đây>" | openssl dgst -sha256 -sign <private_key_ở_đây> -hex
Tiếp theo là chúng ta tạo ra watermark và vị trí nhúng như sau:
Với là kích cỡ của ảnh đầu vào, là kích cỡ của watermark sắp được tạo, và là số class để phân lớp; đồng thời , , , là 4 hàm hash bảo mật, ta có:
- Class sẽ predict true embedding là
- Content của null embedding sẽ là
- Vị trí đặt watermark sẽ là
- Và giá trị lớn sẽ là .
Trong đó, các hàm hash được chọn là SHA-256 để an toàn. Trong code sau, null embedding sẽ thay bằng để đơn giản về sau.
def get_patch(hexdigest, patch_size=(6,6)):
# hexdigest is SHA-256-hashed signature
signature = int(hexdigest, 16)
bits_size = patch_size[0] * patch_size[1]
# true embedding class
y_w = signature % num_classes
# null embedding content
bits_int = signature % (2 ** bits_size)
bits = []
for i in range(bits_size - 1, -1, -1):
bits.append((bits_int >> i) % 2)
null_embed = np.array(bits).astype(np.int).reshape(patch_size) * 2 - 1
# embedding position
pos = signature % (input_shape[0] - patch_size[0]), signature % (input_shape[0] - patch_size[1])
return null_embed, pos, y_w
Với null embedding, các bit 0 sẽ được thay thế bằng và bit 1 bằng ; còn true embedding thì ngược lại. Từ đó, ta tạo ra một Keras layer chỉ để nhúng watermark:
class WatermarkEmbedder(tf.keras.layers.Layer):
def __init__(self, watermark: np.array, mask_position: tuple, lambda_: float):
super(WatermarkEmbedder, self).__init__()
self.watermark = watermark[:,:,np.newaxis]
self.pos = mask_position
self.lambda_ = lambda_
def build(self, input_shape):
if len(input_shape) == 4:
input_shape = input_shape[1:]
self.mask = np.zeros(input_shape)
self.mask[self.pos[0] : self.pos[0] + self.watermark.shape[0],
self.pos[1] : self.pos[1] + self.watermark.shape[1],
:
] = self.watermark * lambda_
def call(self, inputs):
return tf.where(self.mask == 0, inputs, self.mask)
Trước khi định nghĩa mô hình có phần nhúng, chúng ta cần tạo mô hình không nhúng trước. Đây là cấu trúc mạng phân lớp MNIST trong paper, bạn có thể thay đổi để phù hợp với task của bạn.
def create_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))
return model
Và định nghĩa bản vẽ của model của chúng ta: trong đó, với một ảnh đầu vào, mô hình sẽ ra 3 đầu ra: đó là kết quả phân lớp của ảnh đầu vào gốc, ảnh có null embedding, và ảnh có true embedding. Trong đó, 3 đầu ra đó chia sẻ chung trọng số của cùng một lõi mạng phân lớp.
class WatermarkedModel(tf.keras.models.Model):
def __init__(self, null_embed, true_embed, embed_pos, lambda_,
watermarked: tf.keras.layers.Layer=None):
super(WatermarkedModel, self).__init__()
if watermarked is None:
self.watermarked = create_model()
else:
self.watermarked = watermarked
self.true_embedder = WatermarkEmbedder(true_embed, embed_pos, lambda_)
self.null_embedder = WatermarkEmbedder(null_embed, embed_pos, lambda_)
def call(self, inputs):
null_embedded = self.null_embedder(inputs)
true_embedded = self.true_embedder(inputs)
original_class = self.watermarked(inputs)
null_emb_class = self.watermarked(null_embedded)
true_emb_class = self.watermarked(true_embedded)
return {
'original_class': original_class,
'null_emb_class': null_emb_class,
'true_emb_class': true_emb_class
}
Tiếp theo, chúng ta tạo hàm để tạo ra các ground truth tương ứng:
def generate_true_emb_label(shape, cls=y_w):
ret = np.zeros(shape)
ret[:, cls] = 1
return ret
def generate_output(y, cls):
return {
'original_class': y,
'true_emb_class': generate_true_emb_label(y.shape, cls),
'null_emb_class': y
}
Và tạo hàm chúng ta có thể gọi để train một cách dễ dàng: trong paper, loss weight (watermark injection rate) được tác giả đặt bằng .
def get_watermarked_model(hexdigest, injection_rate=0.5):
# signature is confined in a 6x6 patch
patch_size = (6, 6)
null_embed, pos, y_w = get_patch(hexdigest, patch_size)
lambda_ = 2000
true_embed = -null_embed
watermarked_embedded = WatermarkedModel(null_embed, true_embed, pos, lambda_)
# loss weights
alpha = injection_rate
beta = injection_rate
loss_weights = {
'original_class': 1,
'true_emb_class': alpha,
'null_emb_class': beta
}
watermarked_embedded.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.SGD(0.001),
loss_weights=loss_weights,
metrics=['accuracy'])
return watermarked_embedded
Chạy thử
kwkt wuz hia
Thử ký private key của mình với dòng trên, chúng ta có watermark:

Mình có đính kèm cái digest để các bạn có thể tái tạo lại được thí nghiệm này. Chúng ta train model trong 300 epochs:
hexdigest = '0144fa1ac5013e0401fc3741ac12fef415d12374c31c8f5b6987228a63cd4e144ab11bb05c368c1a8335d4a11ca7e095008bfece123c47398296c25319a47e2c72889be320b577356bcbb46b6feac1d5e31c67a0a83715f241184060e76742194de479dd71f8716d788f621e0e882be914a8317a21012781a480125168d2905c10f4d2c8a4f878020112aa57d43b670676dc68d50fd18dda9cf29be511ea7a1edccaf3cfb67733c993f44f2db539d710e9faf185afaee69bd3b6cab8dd42aa6782b49363030a0590ecd35a593c064607d28fc9613b6755fc543726a1f9950c3445ef88dd3c1f8f6fddfb95c49a4cba261bc84e3edf13244cdc0be60f81d0dc46'
watermarked_embedded = get_watermarked_model(hexdigest, 0.5)
watermarked_embedded.fit(
x_train,
generate_output(y_train, y_w),
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, generate_output(y_test, y_w))
)
score = watermarked_embedded.evaluate(x_test, generate_output(y_test, y_w), verbose=0)
print('Original accuracy:', score[5])
print('True embedding accuracy:', score[6])
print('Null embedding accuracy:', score[4])
Và ra được kết quả:
Original accuracy: 0.9860000014305115
True embedding accuracy: 0.5570999979972839
Null embedding accuracy: 0.5403000116348267
Với accuracy plot như sau:
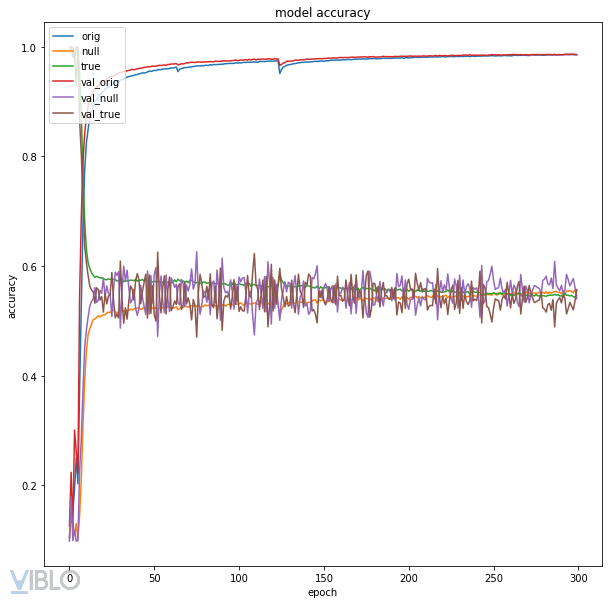
Do kết quả toác quá nên mình thử lại với một string khác.
Mình đã chạy lại code nhiều lần nên không phải do thiếu may mắn về initialization hay gì đâu.
o kawaii koto
Khi ký dòng trên với private key của mình và SHA-256 chúng ta có:
hexdigest = '6958372ae25b822a8e380106f5e0c22fe5c33bbba6adbbaf549b03a911cc088ef7c5f09610a343c4f96c3d9c76960a8ab9a641803a17846ef4ecc59dcec04fad9164a50823db2b1533415b4d89b8a09612d4bf8e89c1b463f1d20639f1b608e167801f6234350a8e97bf87d7d7055e30edaa668e6d66cd1b6810ff689a0842936faec30d4d2b6cc5eb2c35e829f1511a734f896704bccb869c1be4f176238d4d711ae4db7223216ccad92ab38db8c2011df2e0e29c395a9fa985f0e513552a8477f5b8af340e6adf7124305837921e7cc187ba82594c201c4c23b54efe475f8d36198d23052e2a3d34056dd49fcfb825e353b6362ae3f9cb16caf2674859e5cf'
Hash này tương ứng với watermark sau:

Chạy với code i xì như trên, chúng ta ra kết quả:
Original accuracy: 0.9858999848365784
True embedding accuracy: 1.0
Null embedding accuracy: 0.9825000166893005
Với accuracy graph như sau:
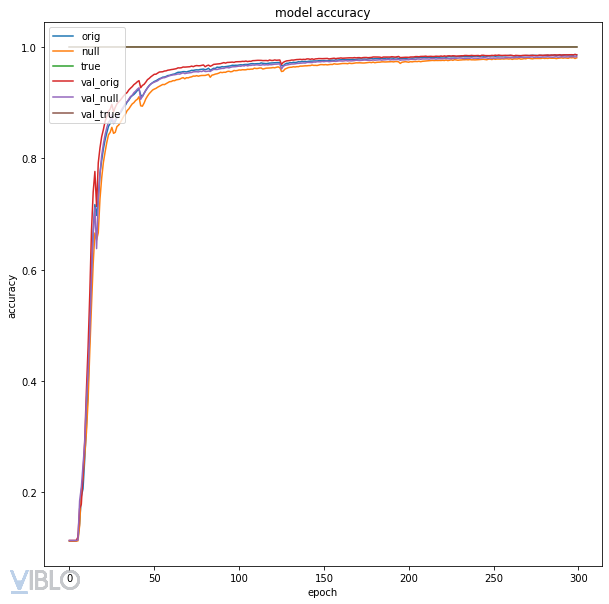
Bỗng nhiên kết quả đúng như mong đợi! Vậy tại sao lại có hiện tượng này? Mình sẽ thử giải thích trong các phân tích dưới đây.
Điểm cộng
- Paper đề rất cao về khả năng không bị attack, đặc biệt với attack vector đổi watermark.
- Khó fake watermark do hàm băm một chiều.
Điểm trừ sẽ cho thấy cả 2 ý trên không hợp lý.
Điểm trừ
- Có các giá trị hash sẽ không train được. Cụ thể, dòng
kwkt wuz hiasẽ ra kết quả không tốt, trong khio kawaii kotothì chạy được. Giả thiết là do sau khi hash và mod thì vị trí của watermark rơi vào vùng ít thông tin (góc dưới bên phải trong các ảnh chữ số thường không có nét vẽ), nên mạng lờ đi luôn từ những epoch đầu tiên và quên luôn. - Paper chỉ xem xét attack vector về ghi đè watermark, nhưng có các attack vector khác dành riêng cho scheme các tác giả đề xuất. Cụ thể, sau một hàm băm ra một kết quả 256-bit, nhưng sau đó sẽ lấy mod với các giá trị nhỏ hơn rất nhiều. Cụ thể, với mô hình MNIST của paper, giá trị đó được mod 10 lấy , mod 22 lấy vị trí đặt, và chỉ lấy least significant 36-bit để làm watermark. Với modulus nhỏ như vậy, khả năng hash collision sẽ cao. Tuy hiên tại mình không có một tấn công cụ thể, nhưng thực sự có cảm giác rằng đây là một hướng tấn công khả thi.
- Cả slide có nói về việc sử dụng giá trị "out-of-bound" , tuy nhiên không có giải thích nào có ý nghĩa cả. Thậm chí, với các giá trị lớn như vậy sẽ gây việc train rất khó (như trong slide đã nói!): với các giá trị to như vậy, trong vector cuối trước softmax chúng ta sẽ có 1 giá trị rất cao so với còn lại, khiến sau softmax sẽ có 1 vector one-hot. Với hàm mất mát cross-entropy, chúng ta sẽ có loss là (hoặc
nan). Cụ thể, inputkwkt wuz hiavới thì mình không thể train được, vì trên 20 lần thử thì 19 lần sẽ gặpnantừ batch đầu tiên của epoch đầu tiên, và 1 lần còn lại thì cũng vẫn không train được: loss không giảm, và accuracy đứng yên ở .
Hết.
Hãy like và subscribe vì nó miễn phí?
All rights reserved
