
[Từ Transformer Đến Language Model] Tổng quan về Large Language Model (phần 1)
Bài đăng này đã không được cập nhật trong 2 năm
Ở 2 bài viết trước mình đã trình bày các kiến thức cơ bản về mô hình transformer. Để tiếp nối series tìm hiểu về large language model, lần này mình sẽ trình bày tổng quan về Large Language Model. Nhóm bài viết sẽ tập trung vào 4 khía cạnh chính của LLMs: pre-training, adaptation tuning, utilization, và capacity evaluation. Ở bài này, mình sẽ tập trung vào các khái niệm cơ bản của LLM và LLM pretraining
Introduction
Ngôn ngữ về cơ bản là một hệ thống phức tạp, bao hàm nhiều loại biểu đạt của con người và tuân theo các quy tắc ngữ pháp khau nhau cho từng loại ngôn ngữ. Trong khi đó, đối với máy móc, chúng không thể tự nhiên nắm bắt được khả năng hiểu và giao tiếp dưới dạng ngôn ngữ của con người, trừ khi được trang bị các thuật toán trí tuệ nhân tạo (AI) mạnh mẽ. Để đạt được mục tiêu này, hướng nghiên cứu Language Modeling từ lâu đã trở thành một trong những đề tài chính rất được quan tâm trong suốt hai thập kỷ qua. Với sự khởi nguồn là "Statistical Language Model" (SLM), sau đó phát triển thành "Neural Language Model" (NLM) và tiếp đến là "Pretrained Language Model" (PLM) đã chứng minh được rằng mô hình ngôn ngữ hoàn toàn có khả năng giải quyết các tác vụ xử lý ngôn ngữ tự nhiên (NLP) khác nhau. Như chúng ta đã biết là với một bài toán nhất định, nếu tăng kích thước mô hình hoặc tăng số lượng dữ liệu training thì khả năng cao sẽ có sự cải thiện performance của model trên bài toán đó. Tuy nhiên với PLM thì nhiều nhà nghiên cứu đã nhận ra rằng nếu tăng kích thước model lên một mức độ đáng kể nào đó thì model mới sẽ xuất hiện một số khả năng mới chưa từng có (emergent abilities) ở các model cũ nhỏ hơn, các khả năng này cho phép model giải quyết nhiều chuỗi tác vụ phức tạp mà trước đây chỉ con người mới có thể xử lý. Những model có kích thước và khả năng như vậy được gọi chung là Large Language Model.
Vậy LLM khác PLM ở những điểm nào ?
- Đầu tiên, LLM thể hiện một số khả năng nổi bật đáng ngạc nhiên mà chưa từng được thấy trong các PLM nhỏ hơn trước đó. Những khả năng này là chìa khóa cho sự thành công của các mô hình ngôn ngữ trong các tác vụ phức tạp.
- Thứ hai, LLM đã cách mạng hóa cách con người phát triển và sử dụng thuật toán AI. Con người phải hiểu cách LLM hoạt động và biến đổi prompt theo cách mà LLM có thể tuân theo.
- Thứ ba, sự phát triển của LLM đã dần xóa bỏ hàng rào giữa research và engineer. Việc training LLM đòi hỏi kinh nghiệm thực tế sâu rộng về big data processing và distributed training parallel. Để phát triển LLM , các nhà nghiên cứu phải giải quyết các vấn đề engineering rất phức tạp, để thực hiện điều này thì hoặc là phải làm việc với các Engineer hoặc là hóa thân thành Engineer :v.
Language Model lớn đến mức nào thì được gọi là Large Language Model ?
Có 2 thuộc tính chính để phân biệt LLM với các mô hình ngôn ngữ khác: một là định lượng, hai là định tính.
- Về mặt định lượng, sự khác biệt ở đây là số lượng tham số được sử dụng trong mô hình. Các LLM hiện tại thường có kích thước > 1B param. Thông tin này được mình tham khảo từ 🤗 Open LLM Leaderboard, với model nhỏ nhất trong leaderboard có kích thước 1.1B và lớn nhất là 180B.
- Về mặt định tính, khi một mô hình ngôn ngữ có kích thước "lớn" đến một mức nhất định nào đó, nó sẽ thể hiện một số khả năng nổi bật (zero-shot learning abilities). Đây là những thuộc tính chỉ xuất hiện khi một mô hình ngôn ngữ đạt đến kích thước đủ lớn, khả năng này sẽ dần mạnh hơn khi kích thước model được tăng lên (xét trong trường hợp data và training strategy không đổi)
Các khả năng đặc biệt của LLM
- In-context learning: In-context learning lần đầu tiên được nhắc đến là ở paper của GPT-3. Giả sử chúng ta đưa một số hướng dẫn cơ bản hoặc một số ví dụ minh họa của tác vụ nào đấy vào prompt cho LLM và yêu cầu nó tạo ra 1 phiên bản tương tự thì LLM hoàn toàn có thể tạo ra kết quả chúng ta muốn mà không cần training hay finetune thêm gì hết.
- Instruction following: Thông qua finetuning với bộ dữ liệu đa tác vụ dưới định dạng instruction, LLM cho thấy khả năng hoạt động tốt với các tác vụ tương tự có định dạng instruction. Với khả năng này, LLM có thể hiểu và thực hiện các task mới mà không cần cho ví dụ.
- Step-by-step reasoning: Người ta phát hiện ra rằng với những tác vụ phức tạp (kể cả đối với con người), nếu chúng ta hướng dẫn LLM thực hiện tác vụ từng bước 1 bằng cách sử dụng cơ chế prompting thì LLM hoàn toàn có thể giải quyết các nhiệm vụ như vậy.
RESOURCES OF LLMS
Open-source LLMs
Những ai tiếp xúc với open-source LLM từ sớm thì chắc không còn xa lạ với cụm từ LLaMA. Lần đầu tiên được giới thiệu với công chúng là vào tháng 2 năm 2023, LLaMA 1 là một họ LLM được tạo ra bởi Meta AI, có kích thước lần lượt là 7B, 13B, 33B, 65B. Vì sao lại có sự ra đời của LLaMA 1 trong khi tại thời điểm đó thì ChatGPT đang là 1 thế lực không thể địch nổi ? Điều này là nhờ có Yan LeCunn - cây đại thụ của giới AI và đồng thời cũng là VP & Chief AI Scientist ở Meta. Khi ChatGPT ra đời, Yan LeCunn đã thực sự cảm thấy rất phản cảm với cách mà "Open"AI "closed" source của họ, gần như họ không chia sẻ bất cứ 1 thông tin nào về model của mình cho giới nghiên cứu trong khi thành quả mà họ đang có được 1 phần không nhỏ là nhờ sự "open" mà từ trước tới nay cộng đồng làm nghiên cứu vẫn luôn hướng đến. Đương nhiên là họ cũng có public technical report để thông báo cho cộng đồng, nhưng bản technical report 99 trang A4 này có nội dung hoàn toàn là để KHOE kết quả vượt trội của GPT-4 và KHÔNG CHỨA THÊM THÔNG TIN CHI TIẾT NÀO về kiến trúc (bao gồm cả kích thước mô hình), phần cứng, tài nguyên tính toán sử dụng để huấn luyện, cách xây dựng tập dữ liệu, phương pháp huấn luyện, v.v..! Chính vì điều này nên Yan LeCunn đã tập hợp các cộng sự ở Meta AI và cho ra đời LLaMA với kết quả là LLaMA 13B vượt GPT-3 175B trên hầu hết benchmark và model có license hoàn toàn mở, kể cả là nếu bạn dùng model của họ cho mục đích thương mại. Sự ra đời của LLaMA đã tạo ra một cơn sóng cực lớn trong giới nghiên cứu, đây gần như là 1 bàn đạp không thể tuyệt vời hơn cho những người đam mê nghiên cứu NLP nói chung và LLM nói riêng; ngay sau đó hàng loạt các paper nghiên cứu về LLM finetuning, quantizing, optimizing,... đã liên tục ra đời. Tiếp nối sự thành công của LLaMA 1, tháng 7 năm 2023 Meta AI lại giới thiệu LLaMA 2 tới cộng đồng nghiên cứu với vô số những cải tiến đang chú ý, nếu các bạn tò mò về LLaMA 2 thì có thể đọc qua blog của tác giả phạm văn toàn : Tất tần tật về LLaMA-2 - liệu có đủ làm nên một cuộc cách mạng mới. Đi cùng LLaMA 2 chính là CodeLLaMA - một họ phiên bản được finetune thêm với dữ liệu code của LLaMA 2, đây thực sự là một đóng góp quá ý nghĩa của Meta tới giới nghiên cứu và những người đã đang và sẽ nghiên cứu về LLM nên dành 1 lời cảm ơn đến Meta và Yan LeCunn.
Sau sự thành công của LLaMA 1 và 2, Mistral AI - một công ty mới thành lập đến từ Pháp, đã cho ra mắt mistral 7B - 1 open source model được report là mạnh hơn LLaMA 2 13B và tiệm cận LLaMA 2 70B. Ngoài mistral thì chúng ta có thể kể đến một số open-source model khác như GPT-NeoX-20B, CodeGen, PanGu, T5, Codegen, Flan-t5,... Và đặc biệt phải kể đến là các open-source model có kích thước lên đến hàng trăm tỷ param như OPT, BLOOM - BLOOMZ, Falcon. Và gần đây thì có thêm sự xuất hiện của các mô hình đến từ Trung Quốc như Qwen và Yi, trong đó mô hình Yi 34B được cho là base model mạnh nhất ở thời điểm hiện tại với điểm benchmark trên OpenLeaderboard của HuggingFace vượt qua cả falcon 180B và llama 2 70B.
Closed-Source LLMs
Với closed-source LLM thì chúng ta không thể không kể đến series GPT của OpenAI đã quá nổi tiếng rồi. Một số model GPT-3 series có thể kể đến của họ là: ada, babbage, curie, davinci, text-ada-001, text-babbage-001, và text-curie-001. Cụ thể, babbage, curie và davinci tương ứng với các mẫu GPT-3 (1B), GPT-3 (6.7B) và GPT-3 (175B). Trong số GPT-3 serie thì 4 model đầu tiên được cho phép finetune trên server của OpenAI. Ngoài ra thì còn có một series GPT-3.5 hay còn gọi là ChatGPT như nhiều người đã biết, và phiên bản GPT-3.5 mà ChatGPT đang dùng là gpt-3.5-turbo-0301 và cũng có 1 lời đồn đó là GPT-3.5 có kích thước 20B :v Khó tin nhỉ ? Cuối cùng chính là Flagship của OpenAI - GPT - 4 !!! Được giang hồ đồn có kích thước 1800 tỷ param - gấp 10 lần GPT-3, được train với kỹ thuật mixture of expert (MoE): OpenAI sử dụng 16 expert model có kích thước 111B để hỗ trợ training cho GPT - 4, dataset training là 13T tokens với nhiều ngôn ngữ khác nhau (của LLaMA 2 là 2T tokens). Nếu tất cả những lời đồn đại này là thật thì quả thực GPT- 4 chính là tượng đài bất khả chiến bại của OpenAI !
Ngoài series GPT của OpenAI thì chúng ta có thể kể đến một số closed - source khá tốt khác như Claude của Claude AI, Palm và Gemini của Google,...
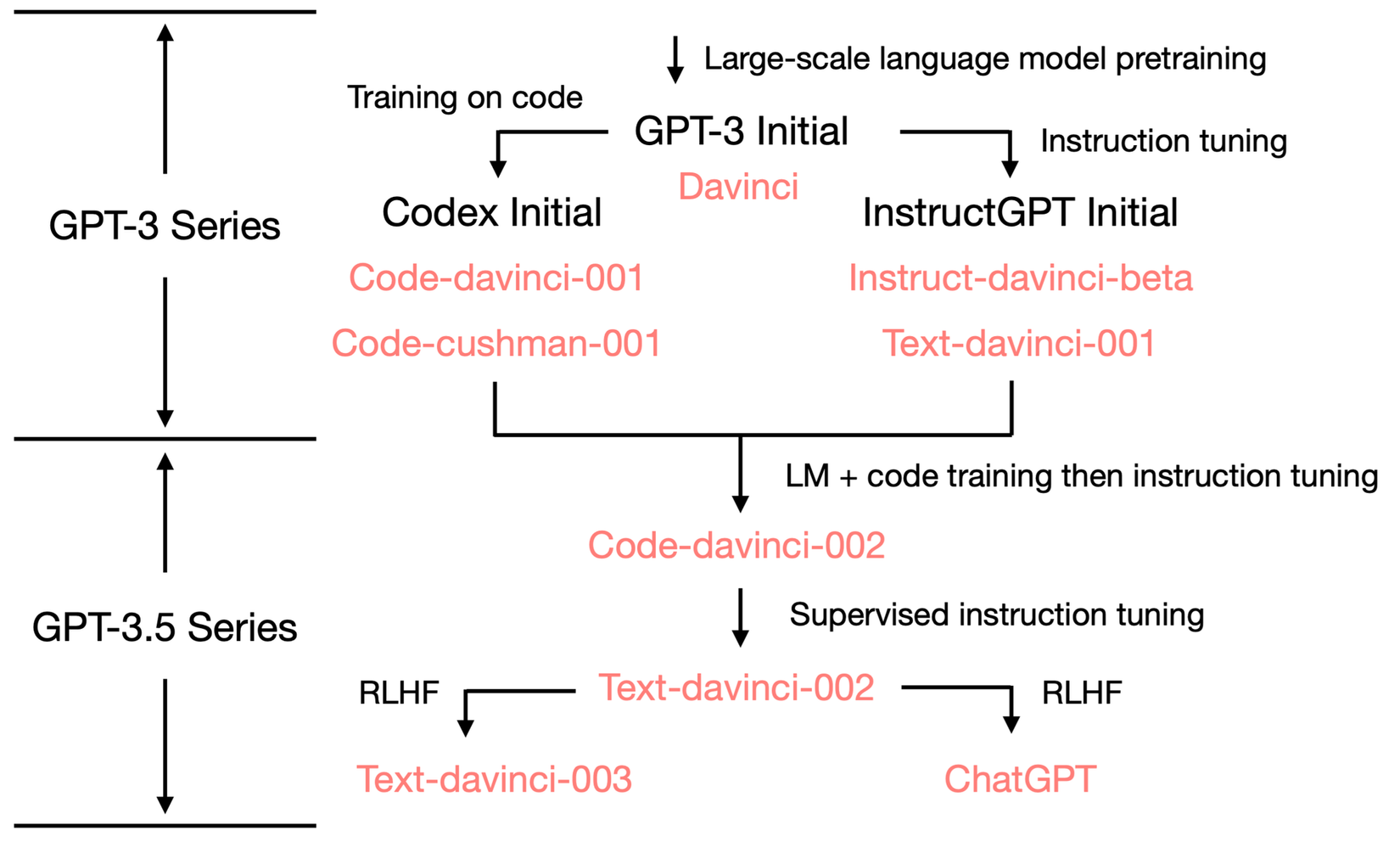
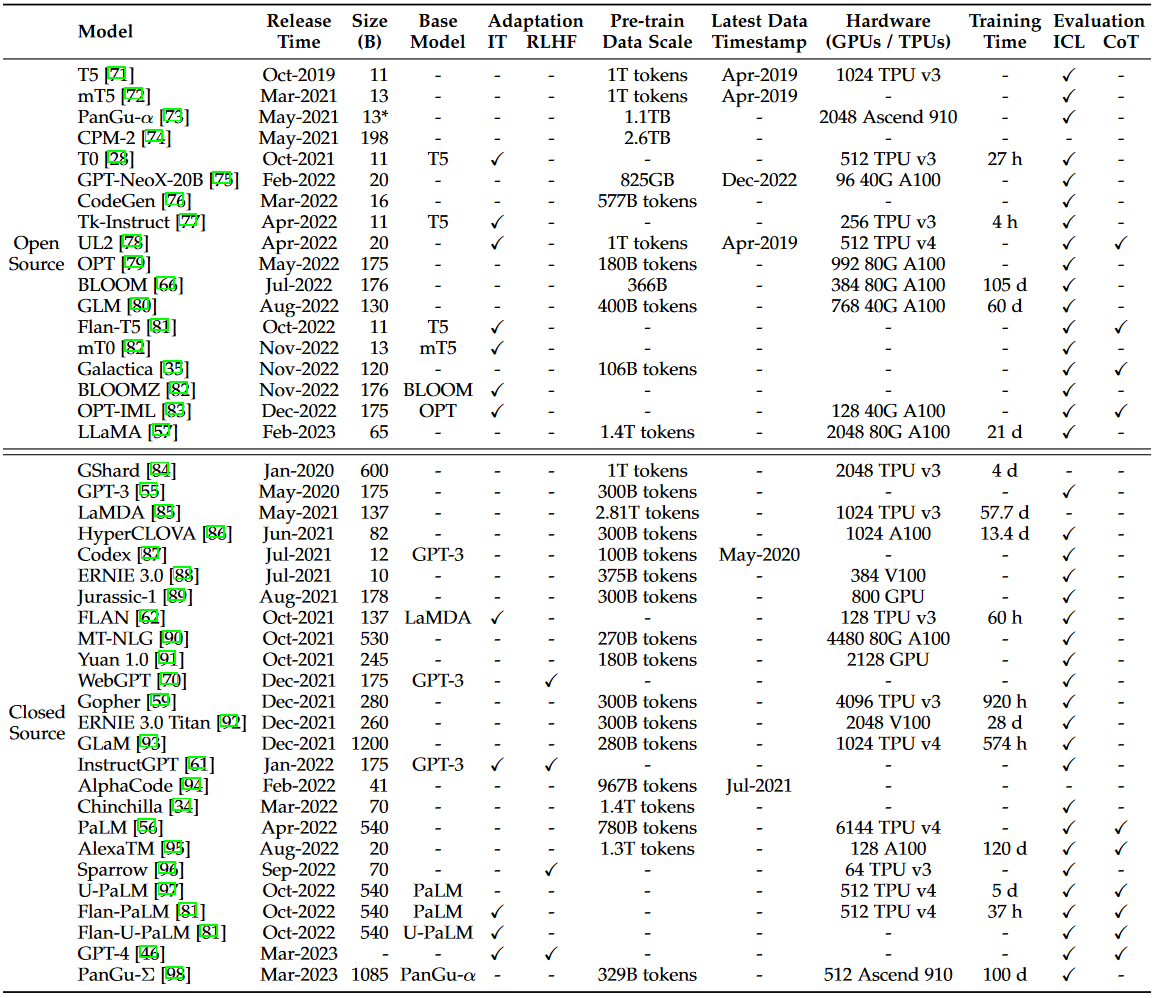
Dưới đây là bảng liệt kê một số open - source và closed - source LLM:
Libraries
Ở phần này sẽ giới thiệu cho các bạn một số library hỗ trợ việc pretrain LLM dễ dàng hơn.
- Transformer: là một open-source python library hỗ trợ xây dựng LLM một cách hiệu quả được phát triển bởi HuggingFace. Đây là một thư viện mạnh mẽ có cộng đồng người dùng và các nhà phát triển lớn, thường xuyên cập nhật và cải tiến các mô hình và thuật toán mới nhất.
- DeepSpeed : là thư viện deep learning optimization trên PyTorch do Microsoft phát triển, được sử dụng để đào tạo một số LLM, chẳng hạn như GPT-Neo và BLOOM. Thư viện cung cấp khá nhiều kỹ thuật optimization như distributed training, gradient checkpointing và pipeline parallelism.
- Megatron-LM: là thư viện deep learning dựa trên PyTorch được NVIDIA phát triển để đào tạo các mô hình ngôn ngữ lớn. Nó cung cấp các kỹ thuật optimization cho distributed training, bao gồm model và data parallelism,mix-precision training, FlashAttention và gradient checkpointing.
- Colossal-AI: là thư viện deep learning được EleutherAI phát triển. Nó được xây dựng dựa trên JAX và hỗ trợ các chiến lược tối ưu hóa cho training như mixed-precision và parallelism.
- FastMoE: là thư viện chuyên biệt dành riêng cho MoE (mixture-of-experts), được phát triển trên Pytorch và ưu tiên tính hiệu quả cùng thiết kế thân thiện với người dùng
Ngoài ra mình cũng muốn giới thiệu đến các bạn một số repo hỗ trợ finetune và quantize LLM khá hay ho như :
- Qlora: cho phép finetune mô hình với thuật toán lora trong khi base model được freeze và quantize 4bit nên tiết kiệm được khá nhiều Vram, giúp các GPU yếu cũng có thể finetune LLM.
- AutoGPTQ: hỗ trợ quantize theo thuật toán GPTQ, khá dễ sử dụng, có support finetuning LLM
- ExLLamaV2: hỗ trợ inference và quantization LLM hiệu quả.
- LLaMA.cpp: quantize và inference LLM với C/C++, có thể inference kết hợp giữa CPU và GPU.
- LLaMA-CPP-Python và CTransformers: python binding cho model được quantize với llama.cpp do llama.cpp chỉ hỗ trợ inference với c++
- AutoAWQ: hỗ trợ quantize theo thuật toán AWQ, mình chưa có cơ hội sử dụng package này nhưng có vẻ cộng đồng LLM đánh giá khá cao package nên mình sẽ giới thiệu ở đây luôn cho bạn nào cần.
- text-generation-webui: hỗ trợ build webUI giúp giao tiếp với LLM hiệu quả hơn.
Nếu sau này có thời gian thì mình sẽ lên bài hướng dẫn chi tiết về finetune, quantization và xây dựng 1 UI đơn giản cho GPU dưới 16GB Vram. Hoặc nhiều thời gian hơn nữa thì mình sẽ lên bài hướng dẫn sử dụng từng repo bên trên :v
Pre-training
Data Source
Các nguồn pretraining corpus thường được chia làm 2 loại: general data và specialized data.
General Data
- Webpages: Với sự phát triển nhanh chóng của internet, nơi đây đã trở thành kho kiến thức khổng lồ của nhân loại, tổng hợp của nhiều lĩnh vực. Vì thế rất nhiều loại dữ liệu đã được tạo ra chờ chúng ta khai phá, đây cũng là một nguồn dữ liệu rất hữu ích để huấn luyện LLM nhờ vào tính đa dạng trải dài từ kiến thức cơ bản đến nâng cao, đa ngôn ngữ, và vô vàn các chuyên ngành khác nhau. Rất may là chúng ta không phải tự crawl dữ liệu từ từng trang web mà đã có CommonCrawl làm việc đó sẵn. Tuy nhiên, chất lượng dữ liệu từ internet cũng khá tạp nham, chứa tất cả các dạng từ thượng vàng đến hạ cám nên để có được dữ liệu sạch training LLM thì ta cần phải làm bước preprocessing rất kỹ càng.
- Conversation text: Để LLM có khả năng giao tiếp như con người thì ta cần huấn luyện nó với dữ liệu dạng hội thoại trò chuyện. Dạng dữ liệu này có thể dễ dàng tìm thấy ở PushShift.io hoặc các trang mạng xã hội như reddit, facebook tuy nhiên chúng ta chỉ có thể tiếp cận các comments ở public group và các comment này thường đến từ các cuộc hội thoại do nhiều người cùng tham gia và đôi khi thứ tự của các comment sẽ khá phức tạp. Một cách xử lý hiệu quả là chuyển một cuộc hội thoại thành một cấu trúc cây, trong đó một comment sẽ được liên kết với comment trước đó mà nó phản hồi. Từ đó, một cuộc hội thoại đa phương sẽ có thể được tách thành nhiều cuộc hội thoại nhỏ để đưa vào training corpus.
- Books: So sánh với các loại văn bản khác thì văn bản đến từ sách có chất lượng khá vượt trội. Ở đây chúng ta có thể tìm thấy các đoạn văn dài với cấu trúc ngữ pháp hoàn thiện và từ vựng đa dạng, những đoạn văn như này thực sự rất có ích cho LLM trong việc học ngôn ngữ hiệu quả hơn, giúp chúng có khả năng tạo ra các câu trả lời mạch lạc. Nguồn dữ liệu open-source về sách thường được dùng là bộ dữ liệu Pile.
Ngoài General Data thì còn có Specialized Data, dạng dữ liệu này được dùng để cải thiện khả năng thực hiện các downstream task của LLM, có thể kể đến một vài loại trong đó như:
- Multilingual text
- Sciencetific text
- Code
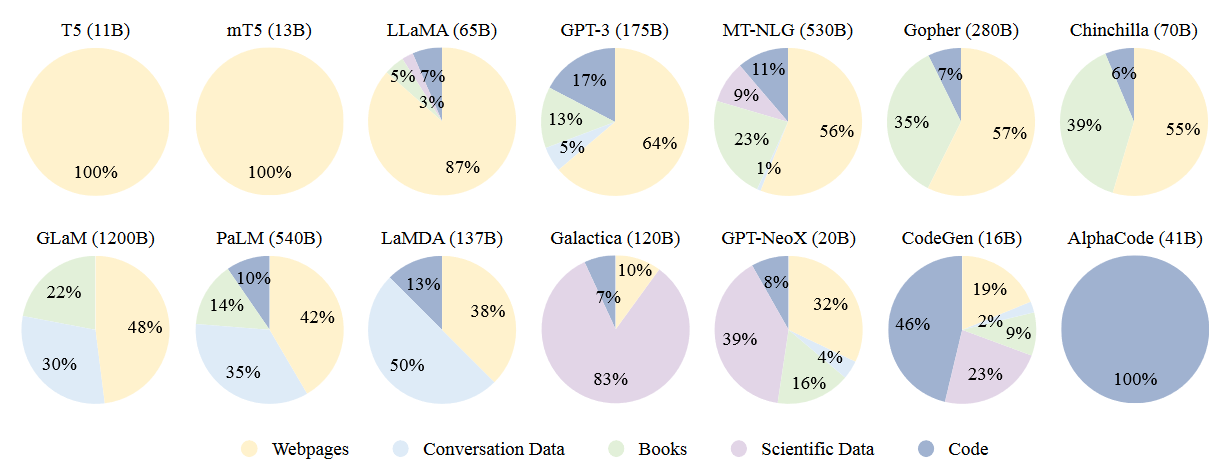
Dưới đây là đồ thị biểu diễn tỷ lệ các loại dữ liệu được sử dụng để pretrain các mô hình khác nhau.
Data Preprocessing
Thông thường dữ liệu raw khi mới thu thập thường chứa khá nhiều thông tin dư thừa, gây nhiễu hoặc thậm chí là chứa thông tin độc hại. Vì vậy nên việc tiền xử lý dữ liệu raw là bước không thể thiếu khi muốn xây dựng tập pretrain data chất lượng. Quy trình tiền xử lý điển hình cho dữ liệu pretrain của LLM được mô tả ở hình dưới:

Quality Filtering: Để loại bỏ dữ liệu chất lượng thấp khỏi dataset, hiện tại người ta thường áp dụng hai phương pháp: (1) classifier-based và (2) heuristic-based. Với hướng thứ nhất, chúng ta sẽ phải train một mô hình classifier dựa trên dữ liệu chất lượng cao và thấp, sau đó dùng model này để phân loại dữ liệu thấp ra khỏi dataset. Tuy nhiên nhiều nghiên cứu đã chỉ ra rằng hướng này vẫn có thể vô tình loại bỏ các đoạn text có chất lượng cao ở những lĩnh vực đặc thù gây mất tính cân bằng và đa dạng của dữ liệu. Với hướng thứ 2, người ta sẽ loại bỏ các văn bản chất lượng thấp thông qua một bộ quy tắc được thiết kế tốt:
- Language filtering: Nếu LLM chủ yếu được sử dụng trong các tác vụ của một số ngôn ngữ nhất định thì văn bản bằng các ngôn ngữ khác có thể được loại bỏ.
- Metric filtering: Áp dụng các metrics đánh giá chất lượng văn bản (ví dụ như perplexity) để loại bỏ các câu có nội dung không được tự nhiên.
- Statistic filtering: sử dụng các đặc trưng mang tính thống kê của dữ liệu dạng text như symbol-to-word ratio, sentence length để xác định chất lượng văn bản từ đó loại bỏ các văn bản có chất lượng thấp
- Keyword filtering: loại bỏ các ký tự gây nhiễu như HTML tags, links hoặc các từ thô tục thông qua một bộ keyword.
De-duplication: Một số nghiên cứu đã chỉ ra rằng dữ liệu bị trùng lặp sẽ làm giảm tính đa dạng trong kho dữ liệu, điều này làm cho quá trình training mất ổn định từ đó làm giảm chất lượng mô hình, vì vậy việc loại bỏ dữ liệu bị trùng lặp là vô cùng cần thiết. Việc loại bỏ trùng lặp có thể được thực hiện ở các mức độ khác nhau bao gồm loại bỏ trùng lặp ở cấp độ câu, cấp độ tài liệu và cấp độ kho dữ liệu. Đầu tiên, ta nên loại bỏ những câu chất lượng thấp có chứa các từ và cụm từ lặp lại vì nếu chúng ta để mô hình học những câu như thế này thì kết quả là mô hình sẽ gặp tình trạng nói lắp thường thấy ở trẻ em. Ở cấp độ tài liệu thì đơn giản là loại bỏ các đoạn dài bị trùng lặp hoặc có nội dung tương tự, ở cấp độ kho dữ liệu ta cũng sẽ làm tương tự như vậy. Người ta đã chứng minh rằng loại bỏ trùng lặp ở 3 cấp độ cải thiện quá trình training LLM lên rất nhiều và phương pháp này đã được ứng dụng rộng rãi trong thực tế.
Privacy Redaction: Phần lớn pretraining text data được lấy từ các trang web, chúng bao gồm cả những thông tin cá nhân hoặc thông tin nhạy cảm, điều này có thể gây ra nguy cơ vi phạm quyền riêng tư. Vì vậy nên ta cần loại bỏ thông tin cá nhân ra khỏi dữ liệu pretrain. Để loại bỏ dạng thông tin này thì người ta thường dùng keyword để lọc ra tên, địa chỉ, số điện thoại,...
Pretraining Tasks
Hiện tại người ta thường dùng 2 task để pretrain LLM là language modeling và denoising autoencoding.
Language Modeling: Cho một chuỗi token , nhiệm vụ của model lúc này là dự đoán token dựa trên chuỗi token đã cho trước đó: . Hàm objective của bài toán được biểu diễn như sau:
Denoising Autoencoding: Gần giống với task language modeling, input của DAE cũng là 1 chuỗi token nhưng 1 vài vị trí trong chuỗi đã bị thay thế bằng một giá trị const (ta sẽ coi các vị trí này là các từ bị che), nhiệm vụ của model chính là dự đoán token nằm ở vị trí bị che đó. Hàm objective của DAE được biểu diễn như sau:
Scalable Training Techniques
Khi kích thước mô hình và dữ liệu tăng lên, việc đào tạo LLM một cách hiệu quả với nguồn lực tính toán hạn chế đã trở nên khó khăn. Đặc biệt, hai vấn đề kỹ thuật chính cần được giải quyết, đó là tăng thông lượng đào tạo và đưa các mô hình lớn vào bộ nhớ GPU. Do đó chúng ta không thể áp dụng các kỹ thuật training thông thường với LLM mà phải sử dụng đến một số kỹ thuật đặc biệt như 3D parallelism, ZeRO và mixed precision.
3D Parallelism: 3D parallelism thực ra là tổ hợp 3 kỹ thuật parallel training: data parallelism, pipeline parallelism và tensor parallelism.
- Data parallelism: data parallelism là kỹ thuật cơ bản nhất để tăng thông lượng cho quá trình training. Nó sao chép model và optimizer rồi đưa vào mỗi GPU, sau đó chia đều dữ liệu trong 1 batch vào các GPU này. Bằng cách này, mỗi GPU chỉ cần xử lý dữ liệu được chỉ định cho nó và thực hiện quá forward và backward để thu được gradient. Gradient được tính toán trên các GPU khác nhau sẽ được tổng hợp để có được gradient của 1 batch nhằm cập nhật mô hình trong tất cả các GPU.
- Pipeline parallelism: pipeline parallelism nhắm vào việc phân chia các layer trong một model LLM vào các GPU khác nhau. Tuy nhiên kỹ thuật này có một điểm yếu là GPU sau phải chờ gradient từ GPU trước dẫn đến việc tính toán không được hiệu quả. Để cải thiện nhược điểm này, GPipe và PipeDream đã đề xuất phương pháp cập nhật gradient không đồng bộ giữa các GPU và padding batch data để cải thiện tính hiệu quả của pipeline parallelism.
- Tensor parallelism: tensor parallelism nhắm đến việc phân chia khối lượng tính toán 1 ma trận tensor vào các GPU khác nhau. Ví dụ ta cần thực hiện phép toán nhân ma trận , thông thường ta sẽ cần nhân tuần tự hàng của với cột của và việc này có thể thực hiện riêng biệt, với tensor parallelism ta sẽ cần tách ma trận thành 2 ma trận con theo cột (ví dụ ma trận 3x3 sẽ được tách thành 2 ma trận 3x1 và 3x2), phép toán ban đầu sẽ trở thành . Khi đó chỉ cần đặt ma trận và ở 2 GPU là ta đã có thể tính toán song song phép nhân ở 2 GPU. Hiện tại thì tensor parallelism đã được hỗ trợ bởi một số open-source như Megatron-LM, Colossal-AI.
ZeRO: ZeRO là kỹ thuật được đề xuất bởi DeepSpeed, tập trung vào giải quyết vấn đề sử dụng bộ nhớ hiệu quả trong data parallelism. Ở bên trên mình đã đề cập đến việc để thực hiện kỹ thuật data parallelism ta cần lưu một bản copy của model data bao gồm model parameters, model gradients và optimizer parameters vào bộ nhớ của mỗi GPU. Tuy nhiên cách này lại khá bất cập đối với model có kích thước khổng lồ như LLM, để giải quyết vấn đề này thì ZeRO sẽ để mỗi GPU lưu 1 phần model data và phần còn lại sẽ được lấy từ từ các GPU khác khi cần. ZeRO cung cấp 3 giải pháp để xử lý 3 loại model data được gọi là: optimizer state partitioning, gradient partitioning và parameter partitioning. Kết quả thực nghiệm chỉ ra rằng hai giải pháp đầu tiên không làm tăng chi phí tính toán và giải pháp thứ ba tăng khoảng 50% chi phí tính toán nhưng tiết kiệm bộ nhớ tỷ lệ thuận với số lượng GPU. PyTorch đã triển khai một kỹ thuật tương tự như ZeRO, được gọi là FSDP.
Mixed Precision Training: một số mô hình PLM trước đây như BERT sử dụng dấu phẩy động 32-bit hay còn gọi là FP32 trong quá trình pre-training. Những năm gần đây thì người ta bắt đầu sử dụng dấu phẩy động 16-bit (FP16) để giảm khối lượng tính toán và bộ nhớ cần dùng. Tuy nhiên một số nghiên cứu gần đây đã chỉ ra rằng FP16 có thể dẫn đến thiếu chính xác trong quá trình tính toán, để giải quyết vấn đề này thì kiểu biểu diễn dữ liệu BF16 (Brain Floating Point) đã ra đời và đã chứng minh được sự ưu việt so với FP16.
Lời kết
Bài viết đến đây cũng đã dài, trong quá trình đọc có thấy sai sót mong mọi người tích cực góp ý để mình cải thiện hơn ở các bài viết sau. Nếu thấy bài hữu ích có thể tặng mình một Upvote cho mình có thêm động lực để chuẩn bị cho một số bài viết khác sắp tới. Cảm ơn mọi người đã ủng hộ !
References
All rights reserved
