
Tối ưu hóa RAG cho dữ liệu có cấu trúc với Text2SQL
Lời mở đầu
Các mô hình embedding văn bản hoạt động rất tốt ở việc encoding các đoạn văn bản (dữ liệu không có cấu trúc) và khiến cho việc tìm kiếm các văn bản giống nhau một các dễ dàng hơn. Và các mô hình embedding này đang được sử dụng phổ biến trong các kiến trúc RAG (Retrieval Augmented Generation) hiện nay, với khả năng có thể encode và truy hồi các thông tin liên quan từ tài liệu hoặc các nguồn văn bản. Tuy nhiên, đối với dữ liệu có cấu trúc, như bảng, thì việc sử dụng mô hình embedding văn bản thường gặp hạn chế và đưa ra các thông tin không chính xác.
Chúng ta có một ví dụ đơn giản như ở dưới đây :
Bộ phim nào có điểm đánh giá cao trong năm 2024?
Để trả lời câu hỏi này, chúng ta cần lọc các bộ phim theo năm phát hành và sắp xếp theo điểm đánh giá. Bài viết này sẽ xem xét cách tiếp cận của Text Embedding và Text2SQL với các câu hỏi dạng như này. Qua đó, chúng ta sẽ thấy rằng khi xử lý các truy vấn liên quan đến đến các thao tác lọc, sắp xếp, hoặc tổng hợp dữ liệu, Text2SQL là một phương pháp hiệu quả để tận dụng RAG với dữ liệu có cấu trúc, giúp đáp ứng các yêu cầu phức tạp hơn mà các mô hình embedding văn bản khó đáp ứng được.
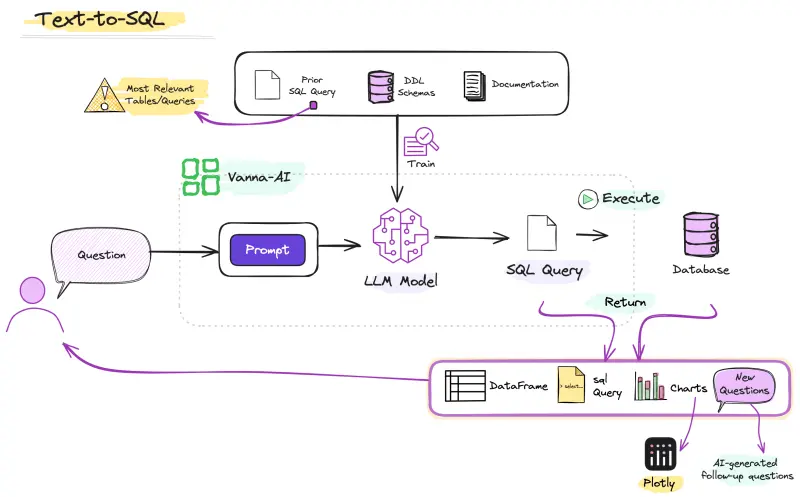
Cách tiếp cận cơ bản với Text Embedding
Chúng ta sẽ phải xem xét các trường thông tin nào nên được embed. Và khi câu hỏi của chúng ta bao gồm cả việc lọc bởi năm phát hành phim và sắp xếp theo rating. Chúng ta sẽ embed tất cả các trường này vào trong đoạn văn bản. Và đối với mỗi bộ phim chúng ta sẽ embed các trường năm phát hành, rating, tiêu đề và mô tả của bộ phim. Ví dụ một đoạn text chúng ta sẽ embed
plot: Following the journey of Alice Johnson, a small-town entrepreneur whose success in the tech world leads her into a high-stakes lifestyle, ultimately drawing attention from the authorities and risking it all.
title: Queen of Silicon Valley, The
year: 2024
imdbRating: 9.0
Sau khi thực hiện embed dữ liệu lưu vào vector database, chúng ta thực hiện quá trình truy hồi thông tin dựa trên câu hỏi đầu vào (ở đây chúng ta lấy top_k = 3)
retriever.similarity_search(
"Which movies are from year 2016?",
)
>plot: Inspired by the life of a daring entrepreneur who rose to wealth through a series of risky ventures, only to face consequences as the law catches up.
title: The Rise and Fall of an Empire
year: 2019
imdbRating: 8.5
plot: A young woman stranded on an uninhabited island embarks on a journey of self-discovery and survival, forging an alliance with a wild animal to endure the harsh elements.
title: Edge of Survival
year: 2023
imdbRating: 8.4
plot: Six interconnected tales dive into the intensity of human ambition, exploring the consequences of unbridled desire in the modern world.
title: Urban Myths
year: 2021
imdbRating: 8.7
Qua câu hỏi đơn giản như này, chúng ta có thể thấy rằng không một bộ phim nào từ năm 2016 được chọn. Có thể thấy rằng trong các trường hợp như này text embedding thường không hoạt động khi mà câu hỏi của chúng ta yêu cầu lọc data, ở trong ví dụ này là năm sản xuất của bộ phim. Thử với câu hỏi khác, nơi mà yêu cầu của người dùng cần sắp xếp dữ liệu.
retriever.similarity_search(
"Which movies are from year 2016?",
)
>plot: A struggling theater troupe attempts to adapt their classic performances for the modern audience, facing challenges and comedic mishaps along the way.
title: Laughing in the Spotlight
year: 2010
imdbRating: 8.6
plot: A vibrant exploration of the legendary music festival that captured the spirit of the 1960s, featuring iconic performances and the cultural revolution of the time.
title: Festival of Dreams
year: 2015
imdbRating: 8.4
plot: This documentary provides an immersive look into humanity's quest to explore the moon, weaving together personal stories and groundbreaking footage from the Apollo missions.
title: To the Moon and Back
year: 2019
imdbRating: 8.5
Qua hai ví dụ đơn giản ở trên chúng ta có thể thấy rằng truy hồi thông tin với text embedding không hiệu quả. Vậy hãy xem Text2SQL thực hiện trả lời những câu hỏi dạng như trên như nào nhé.
Text2SQL
Định nghĩa
Text to SQL là một tác vụ chuyển hóa các câu hỏi ngôn ngữ tự nhiên thành các truy vấn SQL tương ứng có thể thực thi trong các cơ sở dữ liệu quan hệ. Đây là một trong những ứng dụng tiêu biểu của NLP trong việc làm cho dữ liệu dễ truy cập và thân thiện với người dùng ít có chuyên môn về SQL.
Với sự ra đời của các mô hình ngôn ngữ lớn (Large Language Models - LLMs) như GPT-4, khả năng chuyển đổi từ văn bản tự nhiên sang truy vấn SQL đã được cải thiện một cách đáng kể. Các LLM có khả năng học từmột lượng dữ liệu ngôn ngữ tự nhiên lớn và kết hợp với các kiến thức về cú pháp SQL để hiểu và xây dựng các truy vấn phức tạp. Điều này giúp người dùng có thể đặt câu hỏi bằng ngôn ngữ tự nhiên để khám phá hoặc truy hồi dữ liệu một cách đơn giản.
Các thành phần chính trong RAG với Text2SQL
Hình dưới đây là một kiến trúc đơn giản Text2SQL với LLM. Các hệ thống sử dụng Text2SQL thường có 4 thành phần chính : phân tích ngôn ngữ tự nhiên, đối chiếu lược đồ, tạo truy vấn SQL và thực thi câu lệnh SQL đó để lấy về thông tin liên quan đến câu hỏi để có thể trả lời câu hỏi .
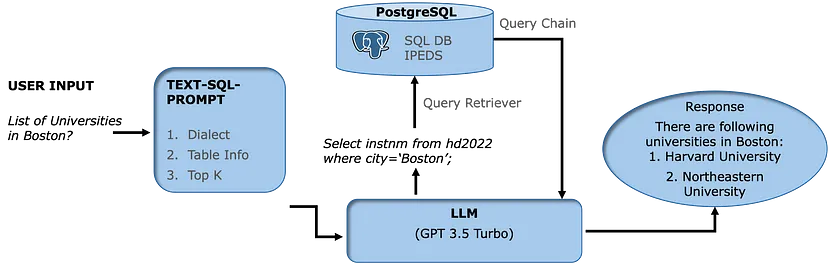
Chúng ta sẽ tìm hiểu các thành phần của hệ thống này thông qua ví dụ sau : “Give me the name of highest-grossing romance movie from last year.”
-
Phân Tích Ngôn Ngữ Tự Nhiên (Natural Language Parsing)
- Từ câu hỏi của người dùng, LLM sẽ xem xét ý định và trích xuất các thành phần chính trong câu hỏi
- Hệ thống sẽ phải trích xuất được các thành phần chính trong câu truy vấn : “highest rating”, “romance movie” và “last year”
-
Đối chiếu lược đồ (Schema Matching)
- Từ các thành phần chính được trích xuất ở bước đầu tiên, hệ thống sẽ đối chiếu các thành phần này với các cột ở trong lược đồ cơ sở dữ liệu.
- Hệ thống sẽ xác định rằng “romance movie” sẽ đề cập tới cột
genre, “highest-grossing” đề cập tới cộtrevenuevà “last year” đề cập tới cộtrealease_date
-
Tạo truy vấn SQL (SQL query generation)
-
LLM sẽ sử dụng các thông tin có được bên trên để sinh ra câu lệnh truy vấn SQL. Câu lệnh truy vấn sinh ra sẽ có dạng tương tự như
SELECT movie_title, review FROM movies WHERE genre = 'romance' AND YEAR(release_date) = YEAR(CURDATE()) - 1 ORDER BY revenue DESC LIMIT 1;
-
-
Thực thi câu lệnh SQL (SQL execution)
-
Câu lệnh SQL được sinh ra bởi LLM ở trên sẽ được thực thi để lấy về kết quả.
movie_title: "The Great Romance" review: "An emotional rollercoaster that captures the essence of love."
-
Thực hành Text2SQL với LangChain
-
Cài đặt thư viện
pip install --upgrade --quiet langchain langchain-community langchain-openai -
Thực hiện theo các chỉ dẫn ở đây để lấy database https://database.guide/2-sample-databases-sqlite/ . Sau đó thực hiện kết nối database
from langchain_community.utilities import SQLDatabase db = SQLDatabase.from_uri("sqlite:///Chinook.db") print(db.dialect) print(db.get_usable_table_names()) db.run("SELECT * FROM Artist LIMIT 10;") -
Tạo chain chuyển câu hỏi người dùng thành câu lệnh SQL
from langchain_openai import ChatOpenAI from langchain.chains import create_sql_query_chain import getpass import os os.environ["OPENAI_API_KEY"] = getpass.getpass() llm = ChatOpenAI(model="gpt-4o-mini") chain = create_sql_query_chain(llm, db)response = chain.invoke({"question": "How many employees are there"}) response > 'SELECT COUNT("EmployeeId") AS "TotalEmployees" FROM "Employee"\nLIMIT 1;' -
Thực thi câu lệnh SQL
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool execute_query = QuerySQLDataBaseTool(db=db) write_query = create_sql_query_chain(llm, db) chain = write_query | execute_query chain.invoke({"question": "How many employees are there"}) > '[(8,)]' -
Dùng LLM để sinh ra câu trả lời
from operator import itemgetter from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough answer_prompt = PromptTemplate.from_template( """Given the following user question, corresponding SQL query, and SQL result, answer the user question. Question: {question} SQL Query: {query} SQL Result: {result} Answer: """ ) chain = ( RunnablePassthrough.assign(query=write_query).assign( result=itemgetter("query") | execute_query ) | answer_prompt | llm | StrOutputParser() ) chain.invoke({"question": "How many employees are there"}) > 'There are a total of 8 employees.'
Một số lưu ý để đảm bảo tính an toàn và bảo mật
-
Luôn luôn phải kiểm tra câu lệnh do LLM sinh ra để tránh các từ khóa nguy hiểm, có thể thay đổi database
def validate_sql(sql_query): dangerous_keywords = ['DROP', 'DELETE', 'UPDATE', 'INSERT', ';', '--'] return not any(keyword in sql_query.upper() for keyword in dangerous_keywords) -
Giới hạn quyền truy cập vào database : Đảm bảo rằng kết nối chỉ cho phép các câu truy vấn đọc dữ liệu, không cho phép thay đổi dữ liệu.
def create_readonly_connection(db_path): conn = sqlite3.connect(db_path) conn.execute("PRAGMA query_only = ON;") return conn
Tổng kết
Bài viết đã giới thiệu Text2SQL như một phương pháp hiệu quả trong kiến trúc RAG (Retrieval Augmented Generation) khi cần làm việc với các thao tác phức tạp trên dữ liệu có cấu trúc, như dạng bảng. Text2SQL, nhờ sức mạnh của các mô hình ngôn ngữ lớn (LLM), cho phép chuyển đổi các câu hỏi ngôn ngữ tự nhiên thành truy vấn SQL chính xác, giúp người dùng dễ dàng truy xuất thông tin mà không cần am hiểu cú pháp SQL.
Chúng ta cũng đã phân tích các thành phần quan trọng của hệ thống Text2SQL cùng với một số lưu ý để đảm bảo an toàn và bảo mật trong quá trình triển khai. Dưới đây là các tài liệu tham khảo cho bạn nào muốn tìm hiểu kỹ hơn.
Reference
https://python.langchain.com/docs/tutorials/sql_qa/
https://neo4j.com/developer-blog/rag-text-embeddings-limitations/
All rights reserved
