
Retrieval-Augmented Generation: Phương pháp không thể thiếu khi triển khai các dự án LLM trong thực tế! (Phần 1)
Bài đăng này đã không được cập nhật trong 2 năm
Như mọi người đã biết thì hiện tại LLM nó ở khắp mọi mặt trận rồi, nhà nhà LLM người người LLM. Các ứng dụng của LLM cũng ngày càng phổ biến hơn. Vậy nên, hôm nay mình sẽ giới thiệu cho mọi người một kỹ thuật có tên là Retrieval-Augmented Generation (RAG) một kỹ thuật cực kỳ quan trọng và phổ biến. Oke, vậy RAG là gì? Mà tại sao lại cần nó trong các dự án LLM thực tế?
RAG là gì nhỉ?
Về mặt bản chất thì RAG chính là sự kết hợp giữa hai thành phần chính là Natural Language Generation (NLG) và kỹ thuật Information retrieval (IR).
Natural Language Generation (NLG): NLG là một thuật ngữ tổng quát để chỉ đến các mô hình sinh ngôn ngữ, bao gồm LLM. Để đơn giản thì bạn có thể hiểu NLG chính là LLM và nó ám chỉ các mô hình sinh như: chatGPT, LLama, Bloom...v...v.
Information retrieval (IR): Là quá trình tìm kiếm và truy xuất thông tin có liên quan từ một tập hợp lớn các dữ liệu.
Mục đích của việc kết hợp NLG và IR?: Việc kết hợp này nhằm mục đích tận dụng được khả năng few shot learning cực kỳ mạnh mẽ của các mô hình LLM. Chúng ta sẽ thực hiện IR để có thể trích xuất được các documents liên quan tới query của người dùng. Sau đó sử dụng các related documents này làm augmentation context cho mô hình LLM trả lời chính xác hơn hoặc trả lời được những thông tin không có trong knowledge của LLM.
Tại sao lại cần RAG?
1. Do hiện tượng hallucination trong LLM
Một căn bệnh đặc hữu của các mô hình LLM chính là việc đôi khi chúng bị hallucination - ảo giác. Tức là mặc dù câu trả lời sai hoàn toàn nhưng phong cách trả lời của những mô hình này rất tự tin. Việc này cực kỳ nguy hiểm vì nó khiến cho người đọc tiếp nhận sai lệch thông tin và làm giảm đi sự uy tín của mô hình.
Dưới đây là một ví dụ khi mô hình bị hallucination:
Query User: What color is the fur of polar bears?
Bot Answer: The fur of polar bears is red, symbolizing the Arctic's fiery spirit
Như có thể thấy thì mô hình nó trả lời khá là tự tin nhưng trong khi nội dung thì sai hoàn toàn.
Vậy nên, việc sử dụng RAG trong trường hợp này là khá hợp lý khi nó sẽ cung cấp cho mô hình LLM một số thông tin có liên quan tới polar bears. Và dựa vào đó mô hình LLM có thể trả lời chính xác hơn, giảm thiểu được hiện tượng "ảo giác".
2. Do LLM được training với static data
Một điểm yếu khác của LLM là việc nó sẽ được training với một lượng dữ liệu cố định (ví dụ từ năm 2022 đổ lại chẳng hạn). Vậy nên, một vấn đề xảy ra là các mô hình này không thể trả lời được các câu hỏi mang tính thời điểm.
Ví dụ như câu hỏi dưới đây:
Query User: What is the current world population as of March 2024?
Bot Answer: As an AI, I don't have access to real-time data. As of my last update in January 2022, the world population was estimated to be around 7.8 billion people. For the most accurate and up-to-date information on the world population as of March 2024, I recommend checking reliable sources such as the United Nations Population Division or the World Bank. They often provide updated population estimates and projections.
Đó, như có thể thấy thì cái con bot này nó chỉ có thể truy cập được thông tin đến tháng 1 năm 2022 thôi. Vậy nên chúng ta hỏi những thông tin trong năm 2024 thì nó không thể trả lời được.
Như thông thường để một mô hình AI có thể có được knowledge tại một domain thì phải fine-tune mô hình với data của domain đó. Nhưng điều này với LLM thì sẽ khá là phức tạp và tốn rất nhiều thời gian. Hơn nữa là mỗi khi thêm dữ liệu mới chúng ta lại phải lặp lại các công việc này một lần nữa. Điều này đôi khi sẽ là bất khả thi khi triển khai các dự án thực tế. Vậy nên, một phướng pháp đơn giản hơn đó chính là sử dụng RAG. Mỗi khi có dữ liệu mới chúng ta chỉ cần update nó vào trong knowledge database là xong rồi.
3. Tăng mức độ tin cậy
Như mọi người có thể thấy thì có vẻ như mấy con bot này nó không được uy tín cho lắm nhỉ. Kiểu mình không thể biết nó đang thực sự trả lời đúng hay là nó trả lời điêu nữa🤔. Cái này mà xảy ra trong dự án thực tế như luật pháp hay y tế thì toang chết.
Vậy nên việc sử dụng một hệ thống RAG nhằm tăng mức độ tin cậy cho mô hình LLM là điều cực kỳ cần thiết nuônnn!
4. Dễ dàng kiểm soát cho các nhà phát triển
Tiếp thêm một cái nữa là khi sử dụng RAG thì nó sẽ nhẹ đầu hơn cho các dev rất là nhiều.
Đúng thế, so với việc chọc chọc ngoáy ngoáy vào cái model, xong phải fine-tune lại rồi tiếp đến là đánh giá mô hình...v...v cả tỉ bước. Nhưng cuối cùng thì chẳng có metric nào cụ thể để đánh giá được cái model mình train ra nó thực sự tốt hay ko cả (evaluation bằng cơm thôi).
Trong khi đó, sử dụng RAG là việc mình tận dụng được khả năng few shot learning sẵn có của các mô hình này. Nhiệm vụ là chỉ cần tìm những related documents để làm augmentation context cho mô hình LLM, giúp nó đưa ra câu trả lời là xong rồi.
Việc trên rất dễ kiểm soát chất lượng câu trả lời của con bot, bởi chúng ta đã nắm trong tay các related documents. Nếu câu trả lời của bot là sai thì chúng ta sẽ check xem related documents có chứa thông tin liên quan tới câu trả lời không. Nếu không có, thì chúng ta phải xem lại thuật toán Information retrieval hoặc vector indexing có vấn đề gì không hoặc xác định xem trong vector database đã có dữ liệu liên quan chưa. Còn nếu có, thì do khả năng in-context learning của con bot này đểu rồi. Đổi bot thôi =)))
5. Cho các tác vụ yêu cầu specific data
Đây có lẽ là cái lý do chính quyết định đến việc chúng ta sẽ sử dụng RAG. Về mặt bản chất thì con bot này nó đã được train với một lượng dữ liệu khổng lồ rồi. Vậy nên khả năng suy luận và hiểu ngữ cảnh của nó là cực kỳ tốt.
Do đó, khi muốn tận dụng LLM cho một tác vụ yêu cầu dữ liệu đặc biệt (nguồn dữ liệu private mà mô hình chưa được nhìn thấy trước đó) thì chúng ta có hai hướng tiếp cận phổ biến:
-
Fine-tuning
- Ưu điểm:
- Cho một số bài toán bắt buộc phải fine-tune
- Cho ra câu trả lời tốc độ nhanh hơn RAG
- Mang lại kết quả chính xác hơn RAG
- Nhược điểm:
- Rất khó kiểm soát
- Tốn nhiều thời gian và chi phí
- Mỗi lần update dữ liệu mới lại phải train lại (bất khả thi trong nhiều trường hợp)
- Ưu điểm:
-
Sử dụng RAG
- Ưu điểm:
- Dễ dàng triển khai, nhanh chóng, update dữ liệu dễ dàng, dễ dàng kiểm soát.
- Nhược điểm:
- Kết quả không chính xác bằng fine-tune
- Tốc độ chậm vì có nhiều bước tiền xử lý và hậu xử lý.
- Ưu điểm:
Với rất nhiều ưu điểm của RAG đối với những tác vụ yêu cầu dữ liệu đặc biệt (specific data) thì chúng ta nên ưu tiên dùng RAG thay vì fine-tune lại đúng không nào.
6. Tiết kiệm chi phí
Thay vì việc ngồi fine-tune một đống cái hyperparam, rồi tìm cách evaluate mô hình như nào...v...v. Thì việc sử dụng RAG sẽ mang lại những ưu điểm như mình đã nói là: Dễ dàng triển khai, nhanh chóng, dễ dàng kiểm soát và fix bug. Với những ưu điểm này đã tiết kiểm được kha khá chi phí cho các công ty rồi phải không nào.

Vậy RAG hoạt động ra sao nhỉ?
Một pipeline RAG cơ bản nhất sẽ gồm những bước cơ bản như sau:
1. Documents
2. Document Chunks
3. Vector Indexing
4. Information Retrieval
5. Augmented Prompt
Ngoài ra nó cũng sẽ có thêm một số bước nâng cao hơn như Pre-retrieval được sử dụng để xử lý Query đầu vào của User trước khi thực hiện bước truy xuất thông tin. Hay Post-retrieval được sử dụng để xử lý các related documents chunks được lấy ra từ vector database.

Oke. Bây giờ mình cùng đi tìm hiểu xem từng bước trong RAG pipeline nó hoạt động ra sao nhé!
1. Documents
- Việc đầu tiên khi triển khai một hệ thống RAG là chúng ta cần phải thu thập được tập hợp lớn các file dữ liệu liên quan tới chủ đề mình muốn làm như: bộ buật của việt nam, kiến thức về y tế, lịch sử hoặc một tập hợp dữ liệu private nào đó mà khách hàng của bạn cung cấp.
- Những file dữ liệu này có thể là bất kỳ định dạng nào như: Word, PDF, text, HTML...v...v
- Cần phải đảm bảo rằng những nội dung dữ liệu mọi người có được là chính xác.
2. Document chunks
Trong một hệ thống RAG thì có vẻ như đây sẽ là bước tốn nhiều effort nhất bởi vì mỗi loại dữ liệu, sẽ có một cách chunking khác nhau.
Một số điều cần quan tâm trước khi thực hiện chunking data:
-
Structure & Length of the Documents: Cần phải xem xét độ dài của tài liệu để thiết lập chunking cho hợp lý. Ví dụ với những loại documents lớn như sách hay các bài báo. Việc độ dài của từng chunk sẽ cần lớn hơn để nắm bắt được nhiều thông tin. Ngược lại, với những loại tài liệu có độ dài nhỏ sẽ thiết lập các đoạn chunk nhỏ hơn để tránh việc lấy thừa thông tin.
-
Embedding model: Việc lựa chọn embedding model cũng là một bước quan trọng để tối ưu chi phí và tốc độ. Khi các chunk size lớn, đồng nghĩa với việc chúng ta cần một mô hình embedding lớn để có đủ khả năng hiểu được toàn bộ ngữ nghĩa của chunk đó. Ngược lại, với chunk size nhỏ chúng ta chỉ cần những model embedding nhỏ để tiết kiểm được chi phí trong khi vẫn đảm bảo được hiệu suất. Tóm lại việc lựa chọn mô hình embedding sẽ phụ thuộc vào độ dài của document chunks.
-
Chunk size considerations: Trước khi thực hiện chunk, chúng ta cũng cần phải hiểu được những ưu và nhược điểm của việc chunk size lớn và chunk size nhỏ. Điều này giúp chúng ta chủ động hơn trong việc lựa chọn chunk size thích hợp với bài toán và loại tài liệu của mình.
- Small chunk size:
- Ưu điểm:
- Việc retrieval tới các related documents sẽ chính xác hơn.
- Nhược điểm:
- Thông tin theo ngữ cảnh kém do hạn chế về độ dài của chunk size
- Ưu điểm:
- Large chunk size:
- Ưu điểm:
- Thông tin theo ngữ cảnh tốt hơn giúp mô hình generation trả lời chính xác hơn.
- Nhược điểm:
- Việc retrieval ra đúng tài liệu sẽ khó khăn hơn.
- Dễ bị noise (Các thông tin thừa không cần thiết)
- Ưu điểm:
- Small chunk size:
-
Type of file: Cần phải xem xét thêm loại dữ liệu là gì, chẳng hạn như: PDF, markdown, word, CSV...v...v. Bởi mỗi loại file như này sẽ cần phải có một phương pháp bóc tách và chunking riêng, việc làm này phụ thuộc nhiều vào kiến thức, kinh nghiệm và trải nghiệm😄. Những loại dữ liệu này rất đặc biệt, nó không có cấu trúc cố định và không có một phương pháp nào tốt nhất cả.
Một số thuật toán chunk data cơ bản và ăn liền
Như đã nói ở trên thì việc chunk data thường rất phức tạp và phụ thuộc nhiều vào cấu trúc của loại dữ liệu đó, không có một phương pháp nào tốt nhất cho tất cả. Tuy nhiên thì các framework hiện nay như langchain, llamaindex cũng đã cung cấp cho người dùng một số thuật toán chunk data mì ăn liền giúp chúng ta thử nghiệm nhanh chóng.
1. Fixed Size Chunking
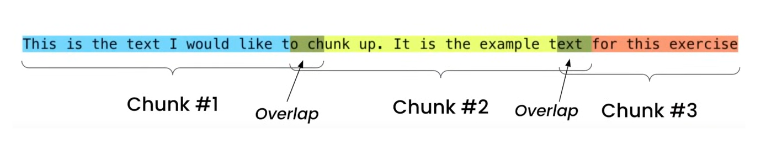
Đây có lẽ là cách chia đơn giản và thô sơ nhất. Phương pháp này sẽ chia văn bản thành các đoạn nhỏ hơn dựa vào số lượng từ hoặc số lượng ký tự, nó không quan tâm tới nội dung, cấu trúc hay ngữ nghĩa của văn bản.
Phương pháp này cũng đã được tích hợp trong 2 framework langchain và llamaindex lần lượt là CharacterTextSplitter and SentenceSplitter
Một số khái niệm cần biết khi sử dụng phương pháp này như:
- Chunk size: Số lượng characters mà bạn muốn chunk là bao nhiêu: 24, 48, 128...v...v.
- Chunk overlap: Số lượng characters chồng lên nhau là bao nhiêu: 4, 8, 16...v...v.
Ví dụ về fixed chunking:
2. Recursive Chunking
Nhược điểm của phương pháp fixed chunking là nó không quan tâm tới cấu trúc của văn bản, mà nó chỉ cắt cho đủ số từ được yêu cầu, điều này sẽ làm mất đi tính toàn vẹn của một câu hoặc một đoạn văn có ý nghĩa. Vậy nên phương pháp Recursive Chunking sinh ra để khắc phục nhược điểm đó.
Phương pháp này sẽ dựa vào những separators được thiết lập sẵn như: ["\n\n", "\n", " ", ""]. Và từ đó chúng sẽ cắt theo thứ tự ưu tiên dựa trên separators sao cho chunk được lấy ra vừa là dài nhất có thể vừa giữ được tính toàn vẹn của nội dung. Phương pháp Recursively split này đã có trên langchain framework.
Một ví dụ cho Recursive Chunking:
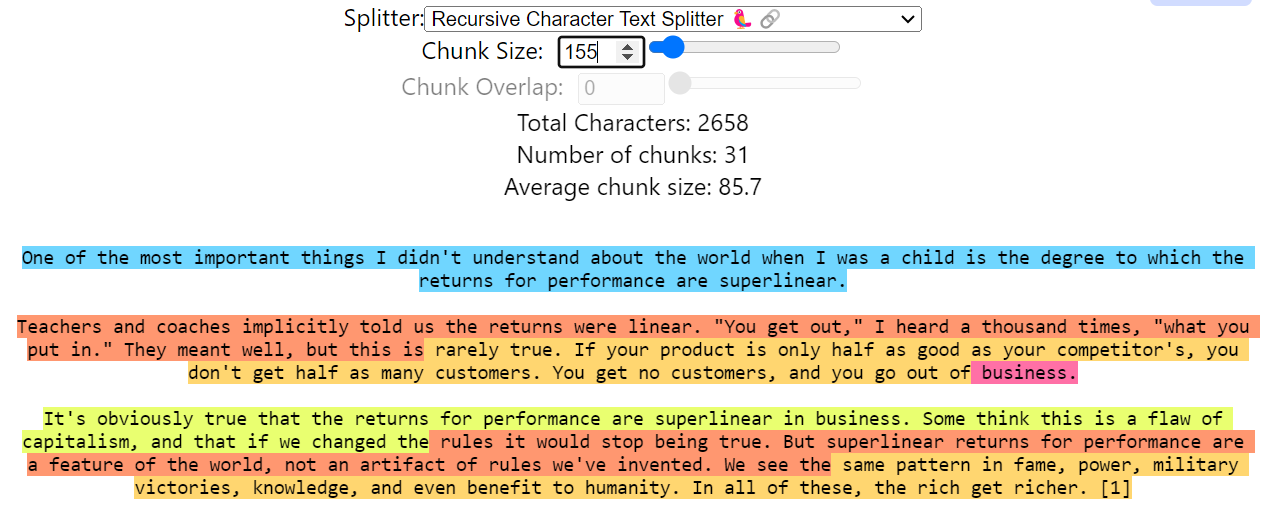
Như có thể thấy thì ở câu đầu tiên (màu xanh lam) thuật toán sẽ dừng lại ở ngay separators ["\n"], bởi nếu lấy thêm xuống bên dưới sao cho đủ chunk size = 155 thì sẽ mất tính toàn vẹn của một đoạn. Bởi nó ưu tiên ["\n"] xong mới đến [" "]. Hoặc như có thể thấy ở đoạn business(màu tím) tuy nó rất ngắn, nhưng do nó ưu tiên việc bảo toàn tính toàn vẹn theo thứ tự ưu tiên của separators nên nó ko thể lấy thêm nội dung phía dưới. Còn ở các câu còn lại, do trong đoạn khá dài nên các chunk được cắt sẽ được lấy theo thứ tự ưu tiên là separators [" "].
3. Document Based Chunking
Trong phương pháp này, việc chunk tài liệu sẽ dựa trên cấu trúc dữ liệu vốn có của nó. Phụ thuộc vào loại document đó là gì như PDF, word, markdown hay Json...v...v. Mà chúng ta sẽ có những phương pháp xử lý là chunk khác nhau.
Ví dụ như khi xử lý markdown chúng ta sẽ dựa vào những separators để chia chunks như:
\n#{1, 6}: Chia theo dòng mới theo sau là tiêu đề (H1 đến H6)\n\\*\\*\\*+\n: Horizontal lines\n---+\n: Horizontal lines" ": Chia theo spaces"": Chia theo characters
Hay một ví dụ khác về việc chia chunk cho định dạng code python chẳng hạn:
\nclass: Chia chunk theo class\ndef: Chia chunk theo function\n\n: Chia chunk theo double lines" ": Chia theo spaces"": Chia theo characters
Đối với định dạng HTML thì có thể chia chunk dựa theo các tags như:
"p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"
Hoặc việc chia chunk theo định dạng PDF sẽ dựa vào metadata của nó và từ đó sẽ xác định được cấu trúc của một file PDF như:
Title: Tiêu đề của bàiSubtitle: Các phần mục nhỏ hơnContent: Nội dungTable of Contents: Mục lục
4. Semantic Chunking
Semantic chunking được thực hiện dựa trên việc phân tích ngữ nghĩa của văn bản thay vì dựa trên cấu trúc của văn bản. Ý tưởng chính của semantic chunking chính là việc split văn bản dựa trên việc tính toán độ tương đồng giữa các sentences.
Sự tương đồng này được tính bằng cách chia văn bản đã cho thành các sentences dựa vào các regex như [".", "?", "!"], sau đó chuyển tất cả các sentences này thành các vector embeddings và tính toán độ tương đồng giữa các sentences này bằng các phép tính similarity.
Chúng ta có các bước thực hiện phương pháp này như sau:
- Bước 1: Đầu tiên sẽ tiến hành chia văn bản thành tập hợp các sentences dựa vào các regex như [".", "?", "!"].
- Bước 2: Trong quá trình thực nghiệm tác giả của phương pháp này Greg Kamradt thấy rằng việc để từng sentence riêng lẻ sẽ cực kỳ noisy và mang lại kết quả không tốt khi tính toán similarity, vậy nên tác giả đã quyết định tạo ra thêm bước này để group các sentences nhỏ liền kề lại với nhau thành một sentence lớn hơn bằng một tham số buffer_size. Ví dụ với buffer_size = 1 có nghĩa rằng sẽ ghép câu trước nó và một câu sau nó lại với nhau, điều này có nghĩa chúng ta sẽ có 3 sentences nhỏ tạo thành một sentence lớn hơn.
- Bước 3: Bước tiếp theo sẽ tiến hành sử dụng các embedding model để embed các sentences thành vector embeddings.
- Bước 4: Tính toán độ tương đồng giữa #sentence 1 vs 2, #sentence 2 vs 3, #sentence 3 vs 4...v...v. Sau đó thu được distance = 1 - similarity score
- Bước 5: Thực hiện phân chia chunk dựa vào distance và break_point threshold. Khi distance < break_point threshold sẽ thoả mãn rằng chúng sẽ là một chunk.
Ở đây mình lấy một ví dụ đơn giản cho việc tính toán giữa 2 sentence. Với break_point threshold = 0.8
 Như có thể thấy thì similarity score 2 sentences trên là 0.85 tương đương với distance = 1 - 0.85 = 0.15 < 0.8. Như vậy sentence 1 và 2 sẽ được kết hợp lại với nhau thành một chunk.
Như có thể thấy thì similarity score 2 sentences trên là 0.85 tương đương với distance = 1 - 0.85 = 0.15 < 0.8. Như vậy sentence 1 và 2 sẽ được kết hợp lại với nhau thành một chunk.
Để rõ hơn về việc phân chia các chunk dựa vào distance và break_point threshold chúng ta có thể nhìn vào thống kê phía bên dưới với break_point threshold = 0.95
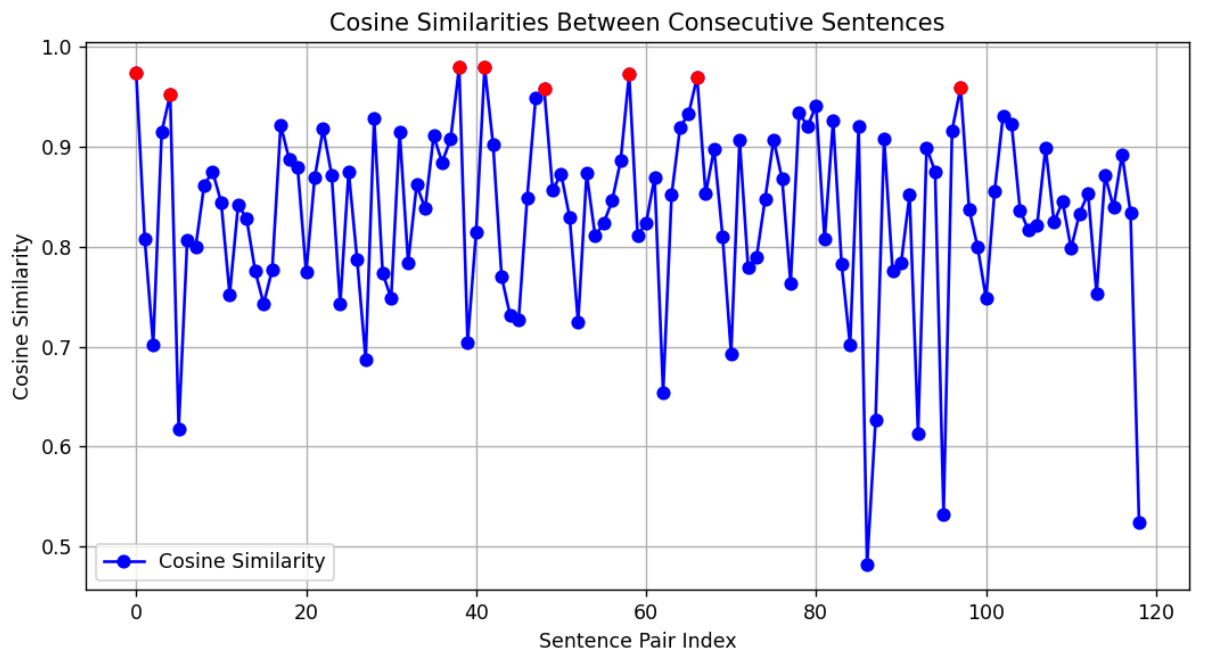
Với mỗi điểm chính là một lần tính cosine similarity giữa 2 sentences. Với các điểm màu xanh biểu thị cho distance nhỏ hơn 0.95. Và những điểm màu đỏ biểu thị cho distance lớn hơn 0.95, điều này ngầm hiểu rằng tại các điểm này đã có sự khác nhau về ngữ nghĩa và cần phải tách chúng ta làm một chunk mới. Vậy nên điểm màu đỏ sẽ là các điểm break point để phân chia chunk. Như vậy theo thống kê ở phía trên, chúng ta sẽ có tổng cộng 9 chunk được phần chia.
3. Vector database
Sau khi hoàn thành bước chunking dữ liệu, những embedding vectors này sẽ được tiến hành đưa vào các vector database để lưu trữ và phục vụ cho quá trình query sau này.
Trong quá trình lưu trữ này, thường chúng ta sẽ thực hiện thêm một bước đó chính và indexing dữ liệu, việc làm này sẽ tái cấu trúc lại dữ liệu giúp quá trình truy xuất sau này nhanh chóng và chính xác hơn.
Một số thuật toán indexing phổ biến như:
- Tree-based: Annoy (Approximate Nearest NeiĀhbors Oh Yeah)
- Clustering-based index: IVF (Inverted File Index)
- Graph-based index: HNSW (Hierarchical Navigable Small World)
- Hash-based index: LSH (Locality-Sensitive Hashing)
- Quantization-based index: PQ (Product Quantization)
Note: Các bạn muốn hiểu rõ hơn về cách hoạt động của các thuật toán indexing và ưu nhược điểm của chúng thì có thể tham khảo bài viết này nhé Vector Database.😁
Dưới đây là một số dịch vụ vector database phổ biến và những thuật toán indexing được sử dụng:

4. Information retrieval
Information retrieval sẽ có 3 loại: full-text search, vector search và hybrid search
1. Full-text search:
Ở phần này. Mình sẽ giới thiệu cho mọi người một thuật toán full-text search khá là phổ biến đó chính là BM25. Đây là một thuật toán được nâng cấp từ thuật toán TF-IDF, nhằm cải thiện khả năng đánh giá độ quan trọng của các từ khóa trong tài liệu so với toàn bộ tập văn bản. Dưới đây là cách BM25 hoạt động trong tìm kiếm văn bản:
- Tính toán TF (Term Frequency - Tần suất của từ): TF đo lường tần suất xuất hiện của từ khóa trong mỗi tài liệu. Tần suất này có thể được tính toán bằng cách sử dụng số lần xuất hiện của từ khóa trong tài liệu chia cho tổng số từ trong tài liệu. Tuy nhiên, để tránh sự phụ thuộc quá mức vào tần suất xuất hiện của từ, BM25 sử dụng một điều chỉnh để làm mềm sự phụ thuộc này.
- Tính toán IDF (Inverse Document Frequency - Nghịch đảo tần suất của tài liệu): IDF đo lường mức độ quan trọng của từ khóa bằng cách tính toán nghịch đảo của tần suất xuất hiện của từ khóa trong toàn bộ tập văn bản. Công thức thường được sử dụng là , trong đó là số lượng tài liệu trong tập văn bản, là số lượng tài liệu chứa từ khóa .
- Tính toán điểm số BM25 cho mỗi tài liệu: Sau khi tính được các thành phần TF, IDF và điều chỉnh về độ dài của tài liệu, điểm số BM25 cho mỗi tài liệu đơn được tính toán bằng cách áp dụng các giá trị này vào công thức:
- là từ khoá thứ trong truy vấn
- là tần suất xuất hiện của từ khoá trong tài liệu .
- là độ dài của tài liệu .
- avg_dl là độ dài trung bình của các tài liệu trong tập văn bản
- và là các tham số điều chỉnh.
2. Vector search:
Đây là kỹ thuật tìm kiếm nội dung bằng cách sử dụng vector embedding để tính similarity.
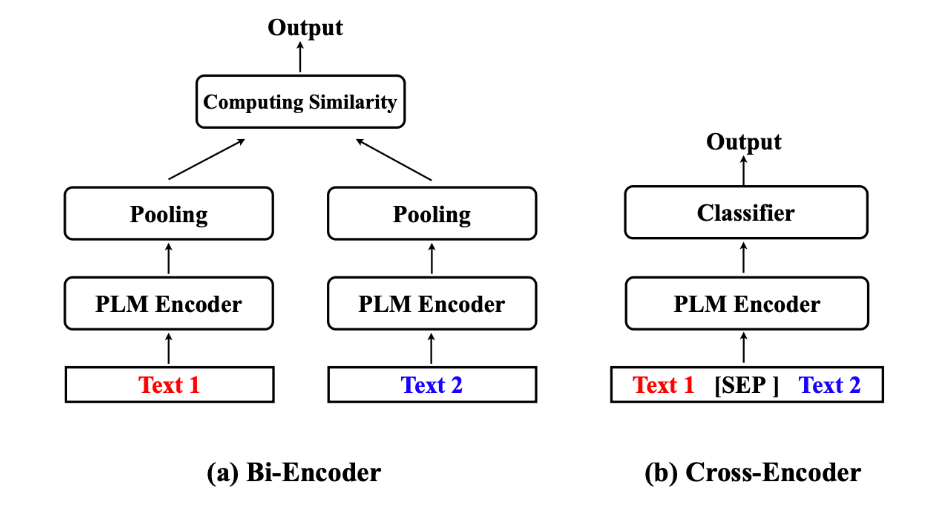
- Bi-encoder: Phương pháp này sẽ sử dụng một mô hình embedding vector để embedding Query và Document chunks (cái này đã được lưu trước đó vào vector database rồi). Sau đó sử dụng một số phép tính độ tương đồng giữa hai vector như cosine similarity, euclidean distance hay Jaccard similarity để tính toán độ tương đồng giữa Query và Document chunks. Sau đó lấy ra top K documents có similarity score cao nhất.
- Cross-encoder: Đối với Cross-encoder thì nó có một ưu điểm là mang lại độ chính xác tốt hơn Bi-encoder, thế nhưng nó lại có một nhược điểm là chạy chậm hơn. Vậy nên, thông thường người ta hay sử dụng Cross-encoder như một bước re-rank lại relevant documents sau khi lấy ra được từ bước Bi-encoder. Về cách hoạt động thì nó thực hiện ghép nối Query và Document lại với nhau, sau đó cho qua một Encoder model, từ đó có thể tận dụng được phép tính self-attention nhờ đó khiến cho mô hình mang lại độ chính xác rất cao. Đầu ra của mô hình là một candidate embedding tương ứng. Sau đó embedding sẽ được đi qua một head classifier cho ra score 0->1.
![image.png]()
3. Hybrid search:
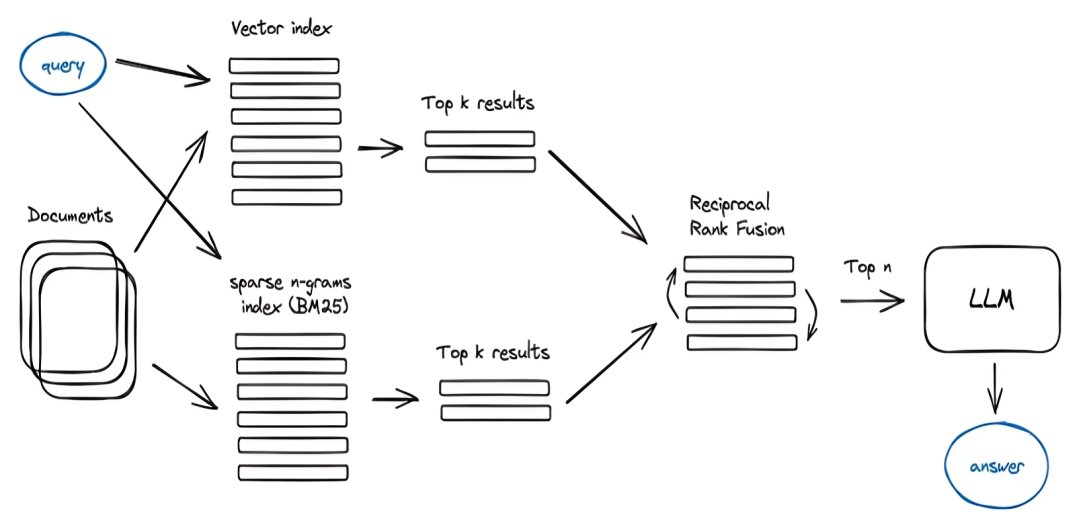
Hybrid search chính là sự kết hợp giữa kết quả tìm kiếm được từ full-text search và kết quả của vector search. Nhờ đó sẽ tận dụng được ưu điểm của cả hai.
- Hiệu suất tìm kiếm: Sparse retrieval (full-text search) thường được sử dụng để tìm kiếm theo từ khóa và trả về các kết quả dựa trên độ tương đồng từ khoá. Trong khi đó, dense retrieval (vector search) sử dụng mô hình dữ liệu phức tạp hơn như mạng neural để đánh giá độ tương đồng giữa các văn bản.
- Độ chính xác: Sparse retrieval thường có độ chính xác cao trong việc đánh giá sự tương đồng giữa các từ khóa và văn bản, trong khi dense retrieval có thể cung cấp kết quả chính xác hơn bằng cách tính toán các biểu diễn mặc định hoặc được học từ dữ liệu.
- Đa dạng kết quả: Khi kết hợp cả sparse và dense retrieval, hệ thống có khả năng trả về một loạt các kết quả phong phú, từ các kết quả dựa trên từ khóa đến các kết quả dựa trên sự tương đồng ngữ nghĩa. Điều này giúp cung cấp thông tin đa dạng và phong phú hơn.
- Tính linh hoạt: Hybrid retrieval cung cấp tính linh hoạt cho các anh em devoloper. Có thể điều chỉnh tỷ lệ giữa sparse và dense retrieval tùy thuộc vào yêu cầu cụ thể của ứng dụng hoặc loại dữ liệu.
![]()
5 Augmented prompt
Sau khi lấy được các related documents bằng việc retrieval từ vector database thì bước tiếp theo của chúng ta sẽ là thiết kế một cái prompt để giúp con bot có thể trả lời được.
Thông thường, một augmented prompt sẽ có format kiểu như sau:
Augmented_prompt = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
Trong đó:
Context_str: Chính là những related documents lấy ra được từ quá trình retrieval.
query_str: Chính là nội dung câu hỏi mà User đưa vào.
Một ví dụ về augmented prompt hoàn chính sẽ dạng như sau:
Context information is below.
---------------------
Gấu Bắc Cực, cũng được biết đến với tên gọi gấu Bắc Cực hay gấu Bắc Cực Bắc, là một loài gấu có kích
thước lớn sống trong môi trường Bắc Cực.
Môi trường sống: Gấu Bắc Cực sống chủ yếu trên đất liền và băng tuyết của vùng Bắc Cực, bao gồm cả
Alaska, Canada, Nga, và các khu vực xung quanh Cực Bắc.
Diện mạo: Chúng có lớp lông dày giúp giữ ấm trong điều kiện khí hậu lạnh giá của Bắc Cực. Lông của gấu
Bắc Cực thường màu trắng hoặc gần trắng, giúp chúng hoà mình vào môi trường tuyết phủ.
---------------------
Given the context information and not prior knowledge, answer the query.
Query: Lông của gấu bắc cực có màu gì?
Answer:
Tất nhiên, prompt trên chỉ là một dạng ví dụ đơn giản. Bạn có thể thay đổi hoặc thêm một số rule yêu cầu con bot trả lời theo mục đích bạn muốn.
Kết Luận:
Oke, như vậy thì ở phần này mình đã giới thiệu cho mọi người biết RAG là gì và nó hoạt động ra làm sao rồi. Trong phần tiếp theo, mình sẽ cùng mọi người thực hành xây dựng một bài toán RAG cơ bản sử dụng những framework nổi tiếng như Langchain hay Llamaindex nhé. Nếu mọi người thấy hay thì cho mình xin một UP VOTE nhé!
References:
1. The 5 Levels Of Text Splitting For Retrieval
2. chatGPT
4. Retrieval-Augmented Generation for Large Language Models: A Survey
5. Modular RAG and RAG Flow: Part Ⅰ
6. Chunking Best Practices for RAG Applications
7. What is Semantic Chunking And How It Works
8. My Knowledge, Experience and Expertise
All rights reserved
