
Retrieval-Augmented Generation: Làm một project nho nhỏ với RAG (phần 2)
Bài đăng này đã không được cập nhật trong 2 năm
Lời mở đầu
Xin chào mọi người, lại là mình đây. Như ở phần một thì mình cũng đã trình bày sương sương về khái niệm của RAG và cách hoạt động của nó. Vậy thì ở cái phần 2 này mình sẽ cùng mọi người thực hành tạo một con bot với RAG sử dụng framework llamaindex nhé.
Trước khi vào bài thực hành thì mọi người có thể download file notebook và datasets ở đây nhé: prepare
Thực hành
Cài đặt một số package cần thiết:
Đầu tiên mọi người sẽ tiến hành cài đặt framework llamaindex:
pip install llama-index
Trong bài này, mình sẽ cùng mọi người sử dụng API free đến từ nhà google. Đó là gemini AI, con này nói chung là cũng khá mạnh là đối thử xứng tầm với chatGPT của nhà OpenAI.
Đầu tiên mọi người cài các package liên quan tới gemini:
pip install llama-index-llms-gemini
pip install -q llama-index google-generativeai
Tiếp đến, trong bài này mình sẽ cần phải embedding các chunk dữ liệu. Vậy nên, cần phải có một mô hình embeding. Ở đây mình sẽ dử dụng của nhà huggingface.
Ở đây mọi người sẽ cài đặt huggingface cho llamaindex:
llama-index-embeddings-huggingface
Lấy google gemini API
Như mình đã đề cập, thì trong bài này chúng ta sẽ sử dụng gemini-pro đến từ nhà google. Con này thì mạnh cũng ko kém quá nhiều so với chatGPT nhà openAI.
Đầu tiên mọi người hãy truy cập vào: https://aistudio.google.com/
Tiếp theo mọi người truy cập vào phần Get API key và tiến hành Create API key cho riêng mình.
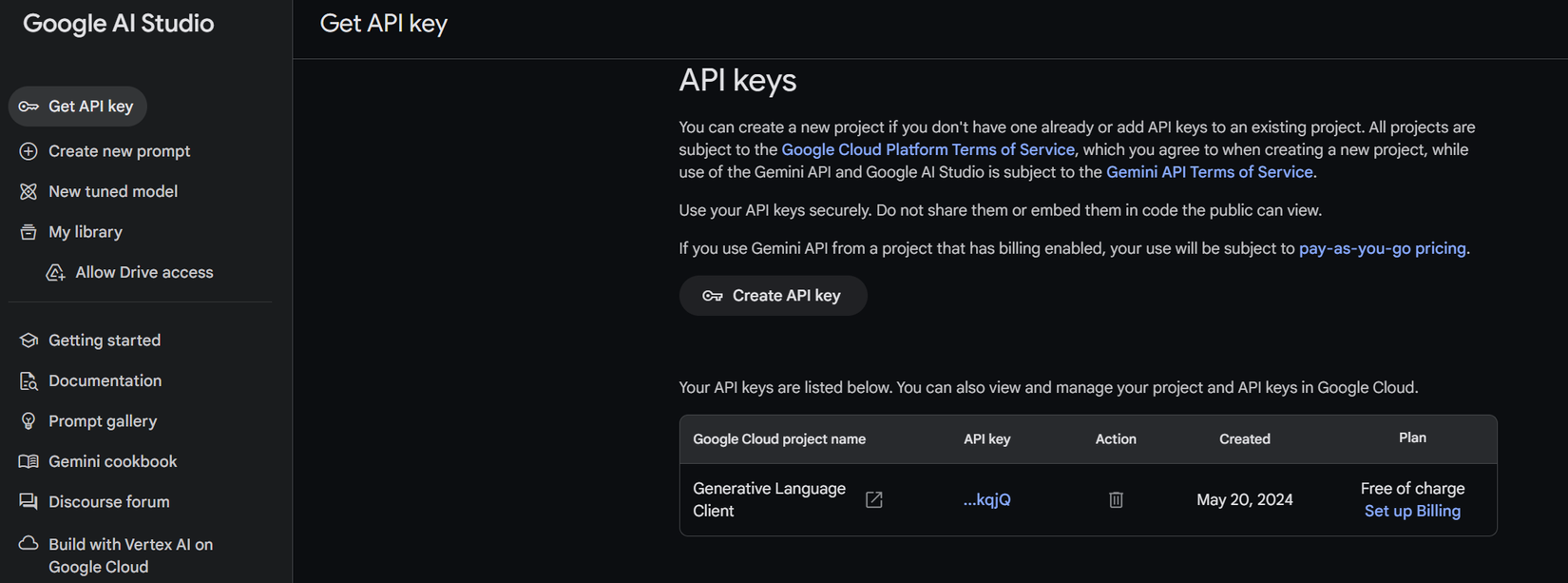
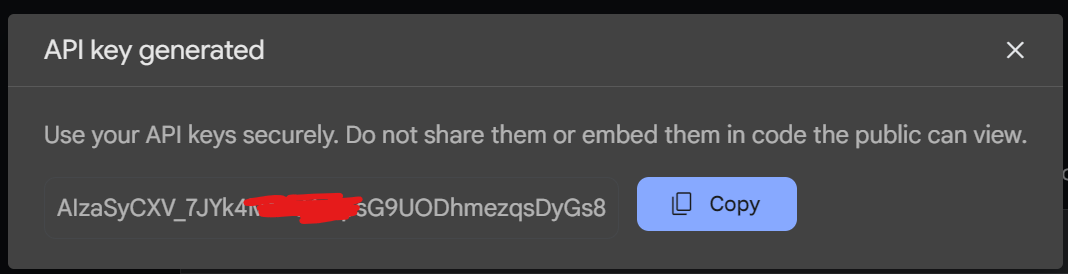
Sau khi Create API key, phần API key sẽ hiện lên và mọi người tiến hành copy phần key này lại. Lưu ý: phần API key này không được để lộ ra bên ngoài.
Để tiến hành kiểm tra xem API của mình đã hoạt động chưa. Thì google có suggest cho mọi người một dòng lệnh terminal mà mọi người có thể run thử:
curl \
-H 'Content-Type: application/json' \
-d '{"contents":[{"parts":[{"text":"Explain how AI works"}]}]}' \
-X POST 'https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent?key=YOUR_API_KEY'
Tiến hành xây dựng RAG với llamaindex
Setup gemini API và mô hình embedding
Đầu tiên mọi người sẽ tiến hành setup gemini API của mình vào biến môi trường như sau
google_gemini_api = "AIzaSyD0iBVrNDJ8e2-----9p8DiuNEXCaykqjQ"
import os
os.environ["GOOGLE_API_KEY"] = google_gemini_api
os.environ["MODEL_NAME"] = "models/gemini-pro"
Tiếp đến mình sẽ phải thiết lập mô hình embedding dữ liệu và mô hình llm sử dụng trong pipeline RAG. Ở đây, với mô hình emdedding sẽ sử dụng bge-small-en-v1.5 và với gemini sẽ là gemini-pro.
from llama_index.llms.gemini import Gemini
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
#llm model
llm = Gemini(model_name="models/gemini-pro", api_key=os.environ["GOOGLE_API_KEY"])
#embed model
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
Sau khi xong, chúng ta sẽ phải làm thêm một bước nữa. Là setting cho llamaindex biết nó sẽ sử dụng mô hình embedding và mô hình LLM nào bằng cách:
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model
Chunk data và storage
Trong phần này, giả sử chúng ta đang xây dựng một mô hình RAG về chủ đề animal. Do đây là phần demo, vậy nên dữ liệu của mình chỉ bao gồm 2 con vật là bear và tiger. Cấu trúc thư mục sẽ như phía bên dưới.
data_animal/
├── bear.txt
└── tiger.txt
Trong llamaindex, việc sử dụng SimpleDirectoryReader sẽ là cách đơn giản nhất để load dữ liệu từ local. Đối với llamaindex, thì mỗi file .txt nằm trong thư mục data_animal sẽ là một Document object.
Tiếp theo thì sẽ tiến hành thực hiện chunker các Documents này thành các chunk nhỏ hơn. Trong llamaindex, thì mỗi chunk dữ liệu sẽ chính là một Node object.
Trong bài này, mình sử dụng thuật toán text splitter là TokenTextSplitter, thuật toán này phân tách dữ liệu thành các chunk dựa vào việc count số lượng token.
Mọi người cũng có thể xem thêm các thuật toán parser/Text Splitters tại đây: Node Parsers / Text Splitters LlamaIndex
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import TokenTextSplitter
# Đọc dữ liệu từ thư mục data_animal bằng SimpleDirectoryReader
reader = SimpleDirectoryReader(input_dir="/home/trinh.quang.huy/LLM_project/data_animal")
documents = reader.load_data()
print("len documents: ", len(documents))
# Tách chunk bằng TokenTextSplitter
splitter = TokenTextSplitter(
chunk_size=512,
chunk_overlap=10,
separator=" ",
)
nodes = splitter.get_nodes_from_documents(documents)
print("len nodes: ", len(nodes))
Bước cuối cùng sẽ là indexing dữ liệu và tiến hành lưu trữ nó.
index = VectorStoreIndex(nodes)
index.storage_context.persist(persist_dir="./animal_index_storage")
Index_storage sau khi lưu trữ sẽ có cấu trúc như sau:
animal_index_storage/
├── default__vector_store.json
├── docstore.json
├── graph_store.json
├── image__vector_store.json
└── index_store.json
Trong đó, docstore.json sẽ lưu trữ các Nodes dữ liệu và một số metadata của nó. Còn default__vector_store.json sẽ lưu trữ Node dữ liệu được embedding.
Load vector index
Tiến hành load vector index từ storage đã lưu trữ trước đó.
from llama_index.core import StorageContext, load_index_from_storage
PERSIST_DIR = "animal_index_storage"
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
Prompt template
Ở đây, mình có yêu cầu cho gemini là nó chỉ sử dụng contex information được cung cấp để trả lời các câu hỏi do user đưa vào. Và yêu cầu nó trả lời đầy đủ nghĩa (vì trong quá trình chạy thử thì mình thấy nó trả lời hơi cộc lốc).
Đây chỉ là một template sample thôi. Còn trong quá trình làm, tuỳ vào bài toán mà mọi người làm thì sẽ có các template khác nhau hay các rules khác nhau cho con bot trả lời smooth và chính xác hơn. Người ta gọi cái này là prompt engineering.
from llama_index.core import PromptTemplate
QA_PROMPT_TMPL = (
"Your task is to answer all the questions that users ask based only on the context information provided below.\n"
"Please answer the question at length and in detail, with full meaning.\n"
"In the answer there is no sentence such as: based on the context provided.\n"
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_prompt = PromptTemplate(QA_PROMPT_TMPL)
print(qa_prompt)
Tạo query engine:
Mặc định thì khi sử dụng index.as_query_engine() thì Llamaindex thực hiện luôn việc khởi tạo retriever với similarity_top_k setup ở đây là 2. Retriever mặc định Llamindex sử dụng là VectorIndexRetriever
Tiếp theo, Llamaindex sẽ sử dụng một prompt mặc định. Vậy nên, khi muốn custom lại prompt chúng ta sẽ phải tiến hành upate prompt để thay thế prompt cũ của Llamaindex.
query_engine = index.as_query_engine(similarity_top_k=2)
query_engine.update_prompts(
{"response_synthesizer:text_qa_template": qa_prompt}
)
Query
Tiến thành query và kiểm tra thử xem thành quả thế nào nhé.
response_type = query_engine.query(question)
print(response_type)
Một vài kết quả:
Câu 1: Câu này thì mình có thử hỏi nó một câu về màu lông của con gấu, thì dữ liệu này có trong datasets. Vậy nên nó trả lời chính xác và đầy đủ.
question_1 = "What color is the polar bear?"
Answer: Polar bears have thick, double-layered fur that is white in color. The white color helps them camouflage well in snow and ice environments.
Câu 2: Ở câu này, mình thử xem mô hình nó có "chỉ sử dụng context information" được cung cấp để trả lời câu hỏi, hay nó sử dụng cả knowledge của nó. Bằng cách hỏi về con Hippo, con này thì ko có trong datasets. Thì nó cũng trả lời đúng ý mình muốn luôn.
question_2 = "Average weight of Hippo?" #không có trong vector database
Answer: The provided context does not mention anything about hippos, so I cannot answer this question.
Như vậy thì con bot của chúng ta xây dựng nó đã hoạt động rất là tốt rồi. Hehe.
Một số bài tập thực hành:
Mọi người có thể thực hành thêm RAG với llamaindex bằng cách:
- Thay đổi các thuật toán reviever khác, thay vì sử dụng mặc định của Llamaindex
- Tìm cách lấy các related chunks ra xem nó hình dáng như nào
- Hay thay đổi thử các thuật toán chunk dữ liệu khác.
- ...v...v.
Lời kết:
Như vậy thì mình đã cùng mọi người tìm hiểu và thực hành một bài cơ bản về RAG rồi. Từ những kiến thức nền tảng này, mình có thể thực hành và tìm hiểu chuyên sâu hơn về các pipeline RAG khác nhau. Xây dựng riêng cho mình một con chatbot. Nếu mọi người thấy hay hãy cho mình xin một Upvote nhé! Cám ơn mọi người.
References:
1. LlamaIndex
All rights reserved
