
RAG 2.0: Một số kỹ thuật được đề cập để cải thiện thêm về RAG - Tiếp
Trong bài này chúng ta sẽ đi tiếp một số kỹ thuật còn lại để cải thiện cho bài toán RAG.
In-Context RALM
Điểm “có thể thay đổi” là việc họ thêm phần rerank có thể training được.

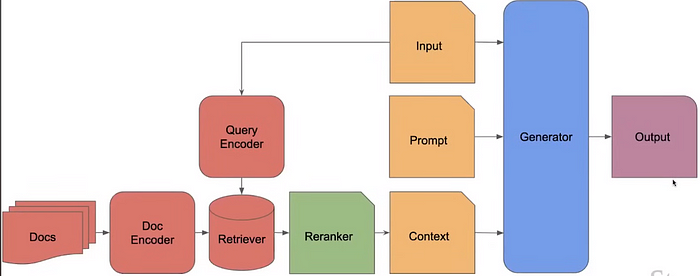
In-Context RALM là một phương pháp kết hợp giữa mô hình ngôn ngữ cố định (Frozen RAG) và BM25 để cải thiện khả năng truy xuất thông tin thông qua việc xếp hạng lại (reranking). Dưới đây là các bước chính và khái niệm của In-Context RALM:
- Sử dụng Frozen RAG và BM25:
- Frozen RAG (Retrieval-Augmented Generation) là một mô hình mà các tham số của mô hình ngôn ngữ (LLM) được giữ cố định.
- BM25 là một thuật toán tìm kiếm văn bản phổ biến, được sử dụng để tìm các tài liệu liên quan đến truy vấn.
- Xếp hạng lại (Reranking):
- Sau khi truy xuất các tài liệu sử dụng BM25, các tài liệu này được xếp hạng lại dựa trên mức độ liên quan đến truy vấn.
- Xếp hạng lại được thực hiện bởi một mô hình reranker đã được huấn luyện.
- Huấn luyện Reranker:
- Trong thiết lập này, chỉ có phần reranker được huấn luyện, trong khi mô hình ngôn ngữ vẫn giữ nguyên.
- Điều này giúp giảm thiểu độ phức tạp và tài nguyên cần thiết cho việc huấn luyện toàn bộ mô hình ngôn ngữ.
- Sử dụng reinforce style loss:
- Vì không thể truy cập vào các tham số của LLM, nên sử dụng phong cách mất mát reinforce để huấn luyện các retrievers.
- Hiệu quả của retriever được đánh giá dựa trên mức độ cải thiện đầu ra của mô hình ngôn ngữ.
- Tối đa hóa hiệu quả truy xuất:
- Các cải tiến cho retriever tập trung vào việc tối đa hóa sự cải thiện thông tin truy xuất.
- Điều này bao gồm việc điều chỉnh chiến lược truy xuất dựa trên các chỉ số hiệu suất như sự mạch lạc, mức độ liên quan và độ chính xác thực tế của văn bản được tạo ra.
Combined Contextualized Retriever and Generator
Thay vì tối ưu hóa mô hình ngôn ngữ lớn (LLM) hoặc Bộ truy xuất riêng biệt, chúng ta có thể tối ưu hóa toàn bộ quy trình.

RAG-token vs. RAG-Sequence:
- RAG-token: Trong mô hình này, tài liệu được truy xuất tại các token mục tiêu khác nhau trong quá trình sinh văn bản. Điều này cho phép mô hình truy cập thông tin liên quan vào các thời điểm khác nhau của quá trình sinh văn bản.
- RAG-Sequence: Truy xuất tài liệu một lần duy nhất cho toàn bộ chuỗi. Cách tiếp cận này đơn giản hơn nhưng có thể không tận dụng tối đa thông tin khi cần thiết. Một số hướng tiếp cận:
Fusion In Decoder:

Sử dụng bộ mã hóa để mã hóa tất cả các tài liệu k và sau đó hợp nhất chúng. Sau đó, quá trình giải mã sẽ thực hiện trên dữ liệu đã được hợp nhất trước khi đưa vào làm ngữ cảnh cho câu lệnh đầu vào.
**k-NN LM: **
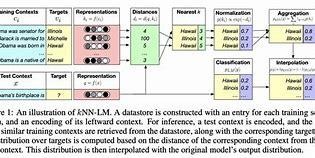
Ý tưởng chính là kết hợp mô hình ngôn ngữ với kỹ thuật k-NN để truy xuất và tích hợp thông tin từ các tài liệu có liên quan nhằm tạo ra văn bản chính xác hơn. Phương pháp này sử dụng cơ chế lân cận gần nhất để tìm kiếm các đoạn văn bản tương tự trong cơ sở dữ liệu và sử dụng chúng để cải thiện kết quả sinh văn bản.
SOTA Contextualization
Có giới thiệu về REALM: Retrival-Augmentaed Language Model Pre-Training
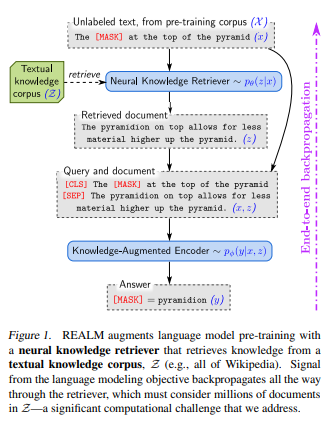
REALM là một thuật toán kết hợp giữa mô hình ngôn ngữ và hệ thống truy xuất thông tin. Nó được thiết kế để cải thiện khả năng của mô hình ngôn ngữ trong việc trả lời các câu hỏi và thực hiện các nhiệm vụ yêu cầu kiến thức cụ thể mà mô hình không thể lưu trữ toàn bộ trong các tham số của nó. REALM sử dụng một mô hình truy xuất để tìm kiếm các đoạn văn bản liên quan từ một cơ sở dữ liệu lớn và sử dụng chúng để cung cấp ngữ cảnh cho mô hình ngôn ngữ.
Có một số cách tiếp cận khá thú vị nữa là ATLAS.
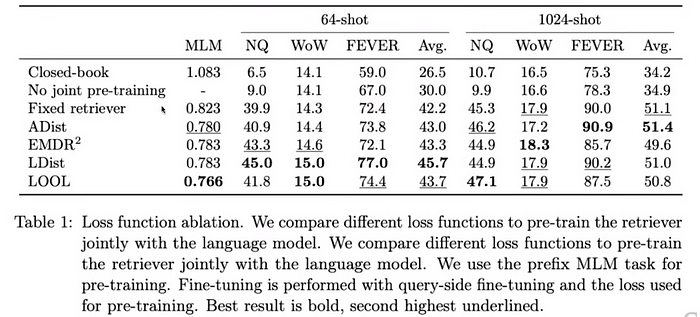
ATLAS là một mô hình ngôn ngữ tăng cường truy xuất được thiết kế và huấn luyện cẩn thận, có khả năng học các nhiệm vụ đòi hỏi nhiều kiến thức với rất ít ví dụ huấn luyện. ATLAS tích hợp các hàm mất mát này vào một quy trình huấn luyện nhất quán cho phép bộ truy xuất được tinh chỉnh trực tiếp dựa trên ảnh hưởng của nó đến hiệu suất của mô hình ngôn ngữ, thay vì dựa vào các chú thích bên ngoài hoặc điểm số liên quan được định nghĩa trước. Sự tích hợp này cho phép hệ thống cải thiện theo thời gian bằng cách thích ứng với các yêu cầu cụ thể của các nhiệm vụ mà nó được huấn luyện. ATLAS sử dụng một khung làm việc mã hóa kép cho hệ thống truy xuất của mình, trong đó một bộ mã hóa dành riêng để mã hóa truy vấn và bộ kia dành cho các tài liệu. Các tài liệu được truy xuất sau đó được đưa vào, cùng với truy vấn, vào một mô hình ngôn ngữ mạnh mẽ theo chuỗi dựa trên kiến trúc T5, hoạt động như bộ giải mã trong hệ thống, tạo ra đầu ra văn bản cuối cùng. ATLAS sử dụng phương pháp Fusion-in-Decoder, tích hợp thông tin từ các tài liệu được truy xuất trực tiếp trong bộ giải mã của mô hình theo chuỗi. Phương pháp này cho phép mô hình ngôn ngữ sử dụng động thông tin được truy xuất trong suốt quá trình tạo văn bản, tăng cường sự liên quan và độ chính xác của đầu ra của nó.
Summary
Sau khi đọc và viết ra thì mình thấy bài này chủ yếu đề cập những hướng xử lý hay tư duy trong việc phát triển RAG lên thành những RAG linh động hơn.
Tóm tắt lại họ giới thiệu với chúng ta một số khái niệm và hướng đi:
- Frozen RAG: Chúng ta thấy loại này rất phổ biến trong ngành công nghiệp, chúng chỉ là các bản thử nghiệm (POCs).
- SemiFrozen RAG: Ở đây, chúng ta triển khai các bộ truy xuất thông minh và cố gắng làm cho chúng thích ứng theo một cách nào đó. Chúng ta không đụng đến mô hình ngôn ngữ lớn (LLM), chỉ điều chỉnh các bộ truy xuất và kết hợp chúng với đầu ra cuối cùng.
- Fully trainable RAG: Khá khó để huấn luyện toàn bộ từ đầu đến cuối nhưng nếu làm đúng cách, nó mang lại hiệu suất tốt nhất. Tuy nhiên, loại này tiêu tốn rất nhiều tài nguyên.
Reference
https://contextual.ai/introducing-rag2/
https://medium.com/aiguys/rag-2-0-retrieval-augmented-language-models-3762f3047256
https://arxiv.org/pdf/2004.12832
https://arxiv.org/pdf/2302.07452
All rights reserved
