
[Paper Explain] A Simple Framework for Contrastive Learning of Visual Representations
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Trong những năm gần đây, chủ đề về các bài toán liên quan tới dữ liệu chưa được gắn nhãn đang được xem là xu hướng nghiên cứu, một số bài toán phổ biến như self-supervised learning, semi-supervised learning, active learning ... đã và đang đem lại rất nhiều thành quả cũng như là một hướng đi tiềm năng trong lĩnh vực nghiên cứu về công nghệ AI. Một trong những bài báo khoa học được biết đến trong lĩnh vực này đã chứng minh được tính hiệu quả và khả năng tận dụng thông tin từ dữ liệu không nhãn, A Simple Framework for Contrastive Learning of Visual Representations với sự kết hợp giữa self-supervised learning(học tự giám sát) và constrastive learning đạt độ hiệu quả đáng kinh ngạc trên nhiều tập dữ liệu với hướng tiếp cận từ dữ liệu chưa được gán nhãn. Vậy thì bài báo này đã làm cách nào để có thể học được thông tin từ dữ liệu không nhãn và thuật toán nào đã đưa SimCLR đạt được hiệu suất như vậy, chúng ta hãy cùng tìm hiểu sâu hơn về bài báo này nhé.
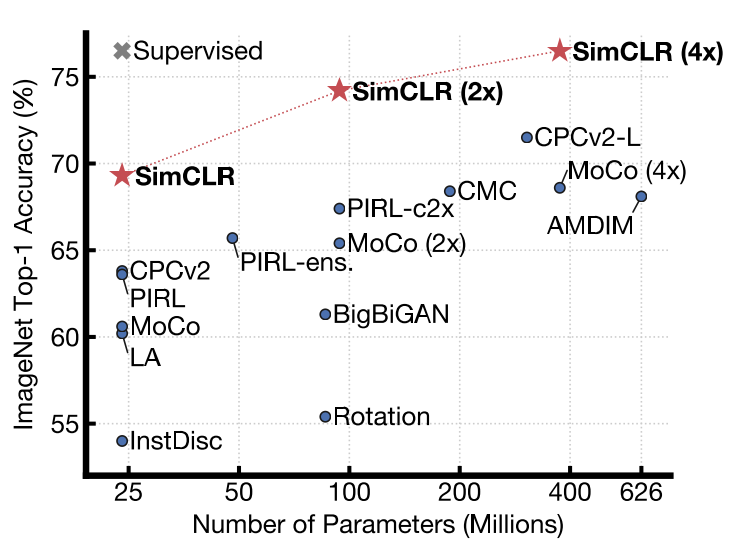
Một số khái niệm
Unsupervised Representation Learning
Unsupervised Representation Learning các bạn có thể hiểu đơn giản làm thế nào để mô hình có thể học được những biểu diễn tốt nhất của dữ liệu không được gán nhãn. Tại sao lại cần biểu diển tốt dữ liệu không được gán nhãn ?, để trả lời cho câu hỏi này thì chúng ta hay đặt ra vấn đề về dữ liệu. Ví dụ trong một bài toán supervised (dữ liệu đã được gắn nhãn) và số lượng lớn dữ liệu không có nhãn nếu bạn đã tối ưu mô hình và đạt được một kết quả nhất định trên tập dữ liệu đã được gắn nhãn đó thì có còn cách nào khác để tăng performance cho bài toán. Câu trả lời là chúng ta có thể tận dụng thông tin từ chính tập dữ liệu không được gắn nhãn. Đó chỉ là một ví dụ nhỏ trong các bài toán nghiên cứu mà mình thường hay gặp phải. Tuy nhiên thì ứng dụng của Unsupervised Representation Learning không dừng lại ở đó, nó còn giúp cải thiện các bài toán trên các tập dữ liệu mang tính đặc thù như dữ liệu y tế, dữ liệu về con người ... nơi mà để tạo ra dữ liệu đã được gắn nhãn tiêu tốn rất nhiều nguồn lực, tài nguyên. Các bạn có thể tham khảo bài viết trước của mình về self supervised leaning để có cái nhìn tổng quan hơn về một số phương pháp khai thác thông tin từ dữ liệu không nhãn nhé
Contrastive Learning
Contrastive Learning hướng tới việc học các biểu diễn của dữ liệu bằng cách kéo các biểu diễn của các mẫu dữ liệu giống nhau về gần nhau và tăng khoảng cách biểu diễn của các mẫu dữ liệu khác nhau trong một không gian biểu diễn. Phương pháp này đã và đang được áp dụng cho rất nhiều bài toán unsupervised learning. Để hiểu được tư tưởng của constrastive learning chúng ta hãy cùng xem hàm loss của nó để hiểu được cách huấn luyện và tối ưu của mô hình
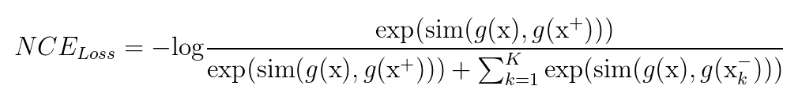
Trong hàm loss, các giá trị như một điểm dữ liệu tương tự như dữ liệu đầu vào , các cặp mẫu ( , ) thường được gọi là cặp mẫu positive. Thông thường, là kết quả của một số phép biến đổi trên . Đây có thể là một biến đổi hình học nhằm mục đích thay đổi kích thước, hình dạng hoặc hướng của , hoặc một phương pháp tằng cường dữ liệu nào đó như cắt, xoay, thay đổi màu sắc ...
Mặt khác, là là những mẫu dữ liệu khác với . Cặp mẫu ( , ) hay được gọi là các cặp mẫu negative và chúng không có ý nghĩa tương quan với nhau. NCE loss sẽ buộc các mẫu negative phải khác với các mẫu positive. Lưu ý: đối với mỗi một cặp mẫu positive( , ) thì sẽ có k tập mẫu negative.
sim(.) hiểu đơn giản là một hàm tính khoảng cách giữa 2 vector ví dụ . Nó có trách nhiệm tối thiểu hóa khoảng cách giữa các cặp mẫu positive đồng thời tối đa hóa khoảng cách của các cặp mẫu negative. Thường thì sim(.) được định nghĩa là cosine similarities.
g(.) là một mạng neuron networks để học những biểu diễn nhúng của các mẫu positive và negative. Các biểu diễn này sẽ làm đầu vào cho hàm loss.
Trình bày qua từng thành phần của hàm loss chắc hẳn các bạn cũng đã hình dung ra được tư tưởng chính của constrastive learning rồi, vậy làm thế nào để ứng dụng vào một bộ dữ liệu và chứng mình được tính hiệu quả của phương pháp . Chúng ta hãy cùng xem phần tiếp theo nhé.
Phương pháp được xây dựng trong bài báo
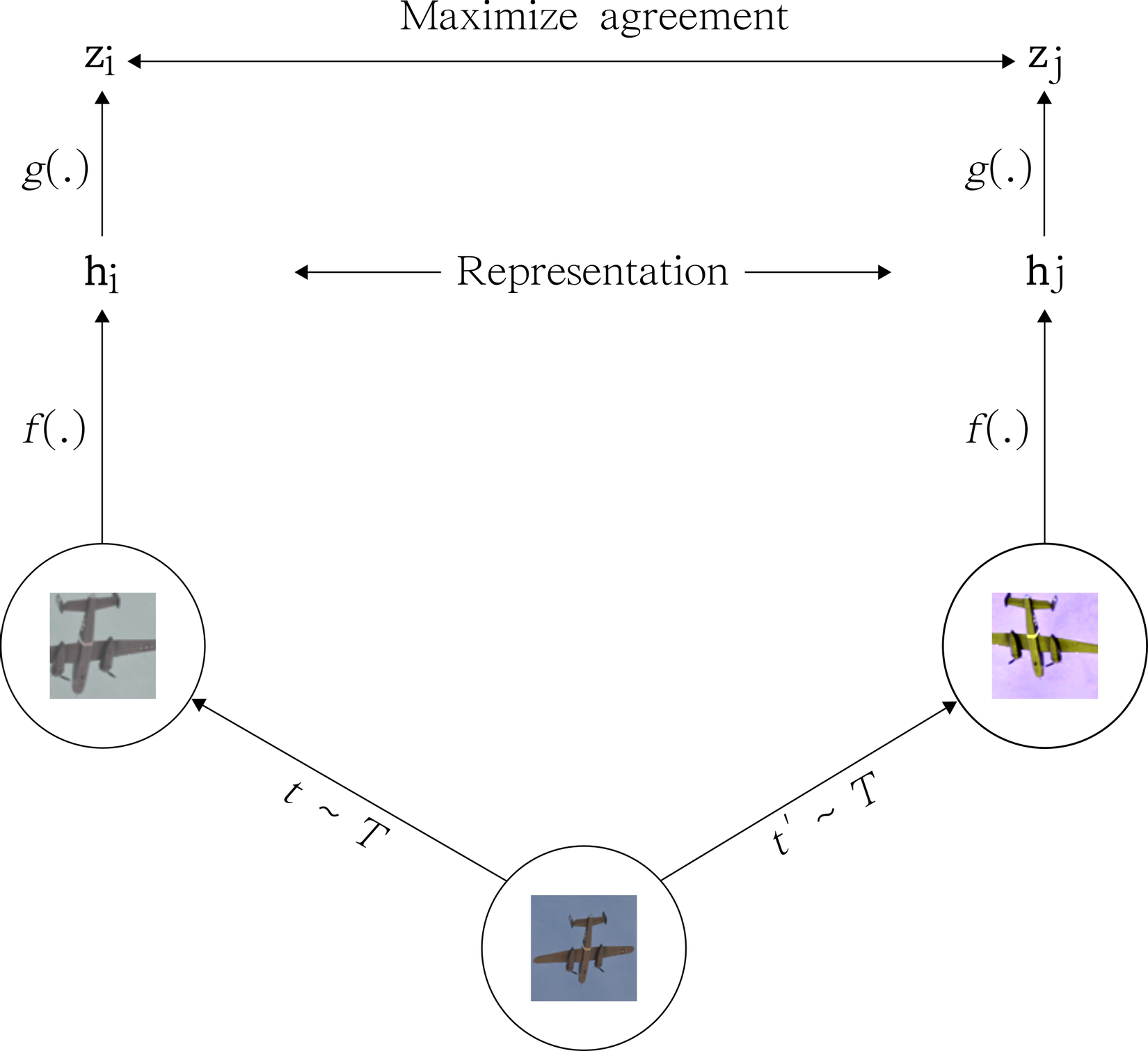
SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) áp dụng tư tưởng của Contrastive Learning. Trong bài báo, phương pháp này đạt được SOTA trong một số tập dữ liệu về self-supervised và semi-supervised. Bài báo giới thiệu một hướng tiếp cận đơn giản để học được các biểu diễn từ hình ảnh không được gắn nhãn dựa quá trình tăng cường dữ liệu. Hiểu nôm na cùng một ảnh nhưng qua 2 phép biến đổi khác nhau và mô hình sẽ học để phân biệt được đó là cùng một hình ảnh.
Sử dụng Contrastive Learning
SimCLR học các biểu diễn của dữ liệu (representation) thông qua quá trình các biểu diễn bằng cách tối đa hóa sự giống nhau tương quan (agreement) giữa 2 chế độ tăng cường dữ liệu khác nhau của cùng một mẫu dữ liệu thông qua constrastive loss trong không gian tiềm ẩn.
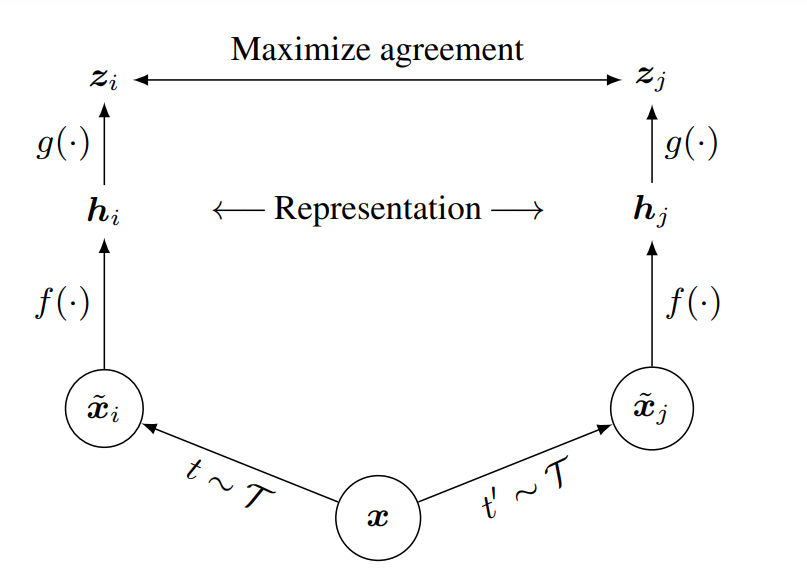
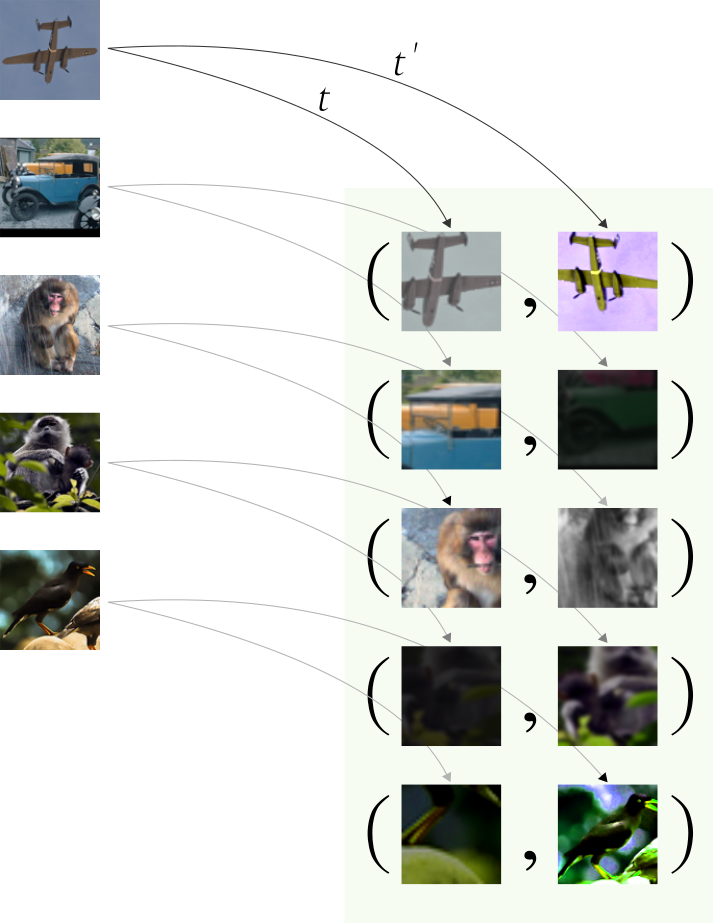
- Data augmentation module ( mô đun tăng cường dữ liệu): Phép biến đổi một mẫu dữ liệu thành 2 kết quả biến đổi khác nhau(ví dụ ảnh được qua phép biến đổi quay ngang, tương tự ảnh đó cũng qua phép biến đổi về màu sắc. Chúng ta thu được 2 sample với các biến đổi khác nhau của cùng một hình ảnh). Trong bài báo họ sử dụng các phép biến đổi: random cropping, random color distortions và random Gaussian blur.
- Mạng nơ-ron trích xuất các vectơ đặc trưng từ dữ liệu sau khi được tăng cường. Trong bài báo họ sử dụng ResNet trong đó trong đó
![image.png]()
- Một kiến trúc mạng neuron network nhỏ ánh xạ các các representations(biểu diển dữ liệu) sang không gian khác thấp hơn để áp dụng constrastive loss. Trong bài báo họ đề xuất sử dụng MLP đầu ra sau MLP sẽ thu được , trong đó là 1 khối ReLU().
- Một hàm constrastive loss được định nghĩa cho nhiệm vụ dự đoán sự sai khác (constrastive prediction task)
![image.png]()
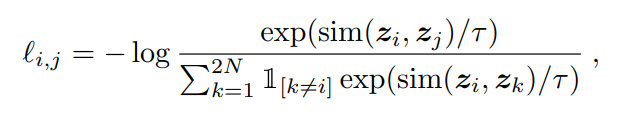
Nếu các bạn xem qua hàm loss của contrastive learning mình giới thiệu ở trên thì có thể dể hình dung hơn cho hàm loss trong phần này nhé. Khi đào tạo mô hình thì chúng ta sẽ chia dữ liệu thành các batch dữ liệu nhỏ để forward qua mô hình và tính loss. Đối với một batch có N sample trước khi đi vào mô hình thì nó được qua một mô dun tằng cường dữ liệu chúng ta sẽ thu được 2N sample. Quay lại với tư tưởng của constrastive learning thì làm thế nào để chúng ta có thể lấy được các cặp mẫu positive và các cặp mẫu negative để áp dụng vào hàm contrastive loss, thì trong bài báo này họ xem đối với 1 sample họ sẽ chọn được 1 cặp mẫu positive( 2 sample được tằng cường từ 1 hình ảnh) và mẫu còn lại là mẫu negative. Khi đó mẫu số của hàm loss chỉ tính trên các mẫu với
- Giải thuật huấn luyện mô hình
Phần này khá quan trọng vì nó giúp chúng ta hiểu hơn về cách triển khai của thuật toán.

Đối với một batch N dữ liệu, temperature parameter (constant), các kiến trục mạng neuron và data augmentation module . Với mỗi một sample sẽ đi qua 2 phép biến đổi (data augmentation) và sau đó forward qua 2 mạng tạo ra và . Với mỗi giá trị ta sẽ tính được . Hàm loss cho một batch dữ liệu sẽ được tính như sau.
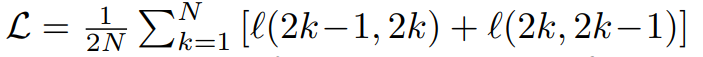
trong đó là hàm loss được định nghĩa phía trên.
Đào tạo mô hình với kích thước batch size lớn
Trong 1 batch dữ liệu có N sample với mỗi sample (index i) họ sẽ ghép với các sample (index j) để tạo ra các cặp mẫu negative, lưu ý là họ sẽ tránh việc nhóm sample (index i) với chính nó hoặc với phiên bản augmentation (tăng cường) của nó. Để tối đa hóa số lượng cặp mẫu negatives thì số lượng các mẫu trong một batch dữ liệu phải lớn. Đối với 1 sample họ sẽ tạo ra 1 phiên bản tăng cường của dữ liệu đó và tính toán số lượng các cặp mẫu negative. Xét 1 batch với N sample họ sẽ tạo ra được 2*(N-1) cặp mẫu negative. Trong bài báo họ chứng minh được với kích thước batch size lớn thì mô hình cũng hướng tới việc tạo kết quả tốt hơn.


Kết quả thử nghiệm
Trong bài báo họ thiết kế khá nhiều thí nghiệm để chứng minh độ hiệu quả của phương pháp, để tổng quát hơn chúng ta có thể xem qua bảng kết quả thí nghiệm sau.
 Kết quả thí nghiệm được thực hiện trên tập imagenet với tỷ lệ label lần lượt là 1% và 10%, chúng ta có thể thấy với việc sử dụng self-supervised representation learning có thể mạng lại kết quả đáng kinh ngạc khi vượt xa mô hình supervised trên một lượng nhỏ dữ liệu được gắn nhãn. Qua đó chứng minh tính hiệu quả của phương pháp khi tận dụng thông tin từ dữ liệu chưa được gắn nhãn.
Kết quả thí nghiệm được thực hiện trên tập imagenet với tỷ lệ label lần lượt là 1% và 10%, chúng ta có thể thấy với việc sử dụng self-supervised representation learning có thể mạng lại kết quả đáng kinh ngạc khi vượt xa mô hình supervised trên một lượng nhỏ dữ liệu được gắn nhãn. Qua đó chứng minh tính hiệu quả của phương pháp khi tận dụng thông tin từ dữ liệu chưa được gắn nhãn.
Kết luận
Bằng việc áp dụng constrastive learning vào bài toán self-supervised và semi-supervised bài báo đã chứng mình được tính hiệu quả khi cải thiện đáng kể performace của các bài toán supervised trên một số tập dữ liệu (đặc biệt là các tập dữ liệu có ít dữ liệu được gắn nhãn). Các đề xuất về việc tạo ra các data augmentation module hay huấn luyện mô hình với batch size lớn trong bài báo cũng đã đem lại kết quả quả tốt cho các thử nghiệm.
Tài liệu tham khảo
A Simple Framework for Contrastive Learning of Visual Representations Exploring SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
All rights reserved
