
Những lưu ý bạn cần biết để viết prompt và sử dụng Azure OpenAI hiệu quả
Bài đăng này đã không được cập nhật trong 2 năm
Lời mở đầu
Hiện nay các hệ thống RAG ngày càng phổ biến và khá nhiều trong số đó sử dụng Azure OpenAI nhưng liệu bạn đã thực sự nắm được sử dụng như thế nào cho hiệu quả ? Sau 1 vài dự án về RAG, mình đã đúc kết được một số kinh nghiệm trong việc sử dụng Azure OpenAI và cách viết prompt sao cho tối ưu nhất.
Nội dung
1. Cân nhắc khi chọn version cho Azure OpenAI API
Đầu tiên, khi chọn Azure openai api version các bạn cần biết bạn sẽ sử dụng những dịch vụ nào của azure vì mỗi version sẽ được tích hợp số lượng dịch vụ khác nhau.
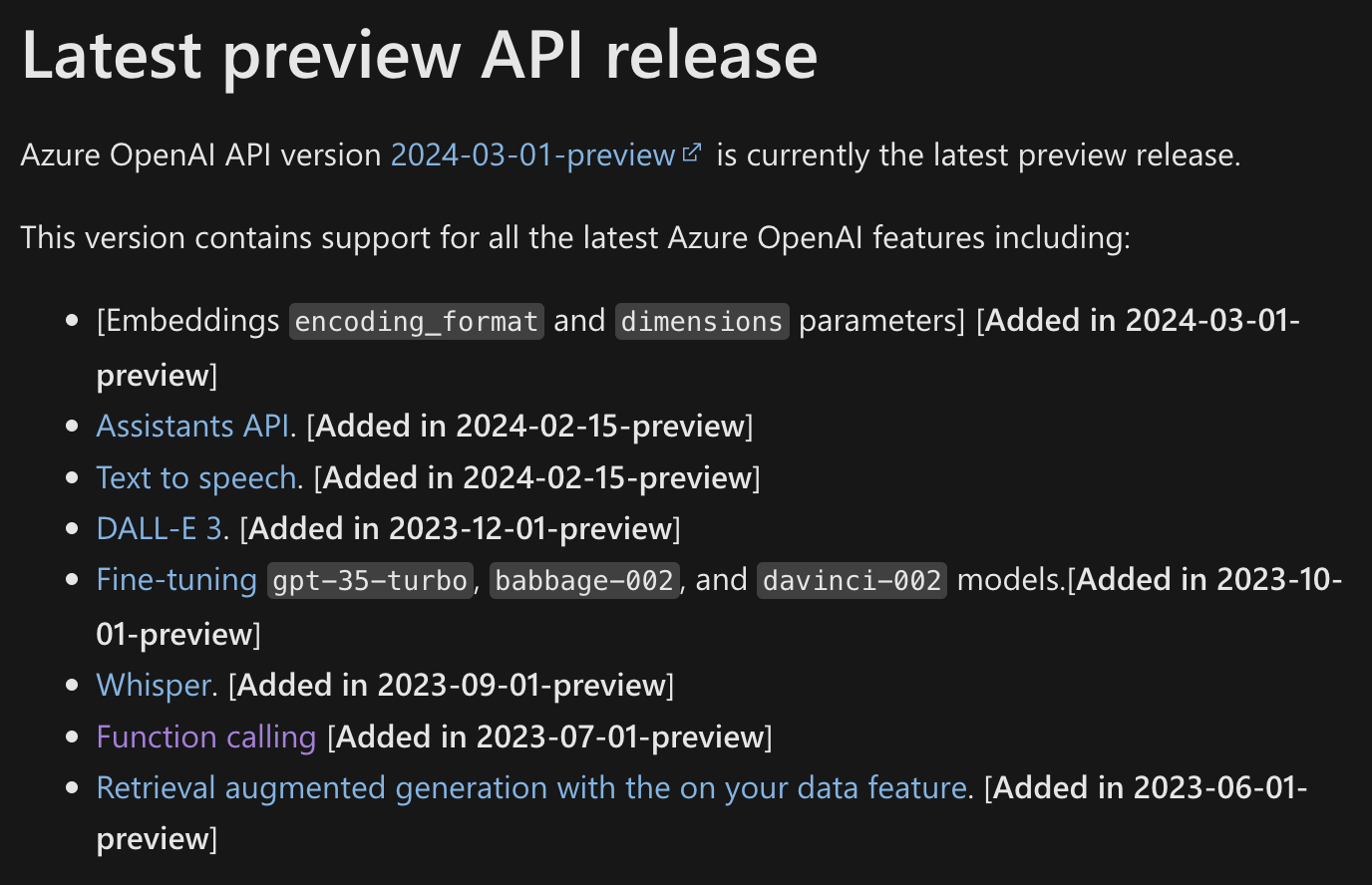
Tiếp theo là nên cân nhắc tránh các version có chữ preview vì sau 1 thời gian những version này sẽ bị disable dẫn đến việc phải thay đổi version và kéo theo là code bị thay đổi.
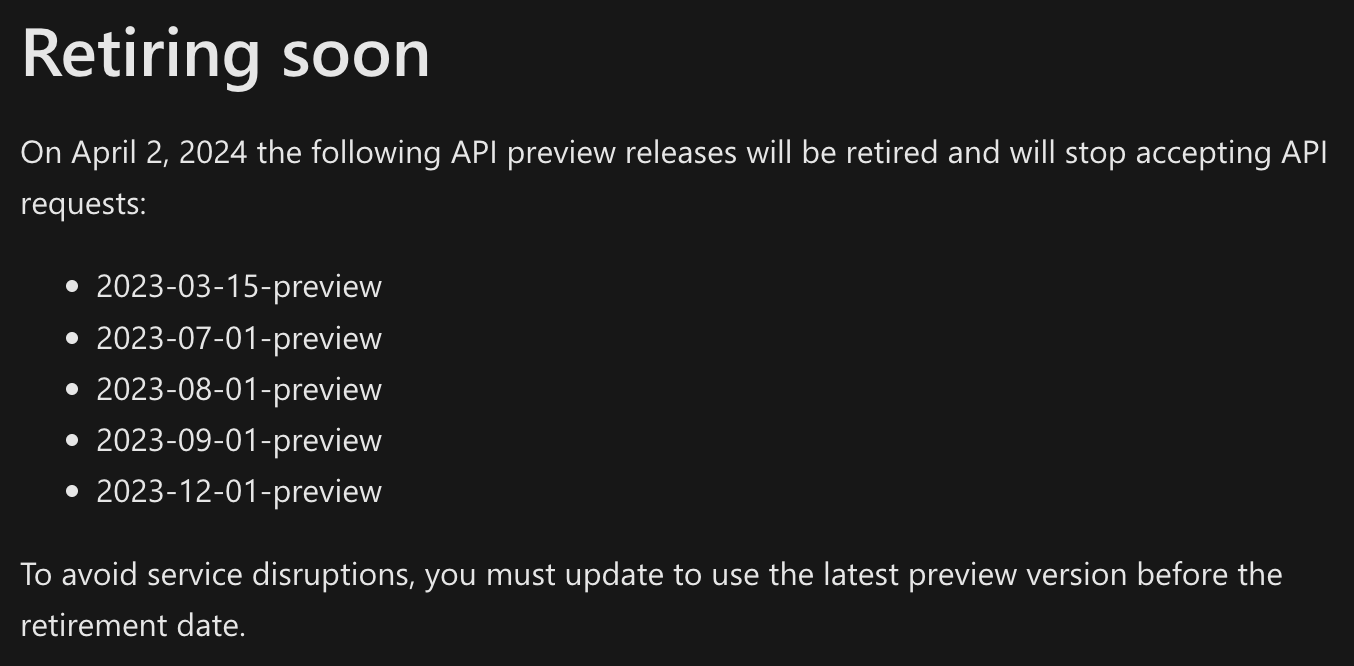
Việc thay đổi version có thể dẫn đến việc phải test lại toàn bộ prompts do mỗi prompt chỉ thực hoạt động tốt với 1 version. Có thể các phiên bản có preview sẽ được update các công nghệ mới nhưng rủi ro đi kèm cũng khá cao. Vì vậy bạn nên cân nhắc các công nghệ mới đó có thực sự cần thiết hay có thể sử dụng ở bên khác được không.
2. Requests per minute, Tokens per request và Tokens per minute
Tùy theo gói azure openai của bạn sẽ có giới hạn số lượng tokens và requests bạn có thể gửi đi mỗi phút; số lượng tokens có thể gửi đi trong 1 request.
Nếu bạn chỉ test rời rạc thì việc giới hạn này sẽ không quá ảnh hưởng nhưng trong các dự án RAG thì số lượng request gửi đi là rất lớn và liên tục. Vì vậy cần có cơ chế để quán lý các giới hạn này nhằm tránh hệ thống bị gián đoạn ảnh hưởng đến hiệu năng.
Cách đơn giản nhất để quản lý việc này là tính số lượng tokens được gửi đi ngay trước khi gọi lên api. Sau đây là 1 đoạn code ví dụ về cách tính:
import tiktoken
text = 'test số lượng token'
encoding = tiktoken.get_encoding('cl100k_base')
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
num_tokens = len(encoding.encode(text))
Ngoài số lượng tokens input thì số lượng tokens của output cũng bị giới hạn. Và bạn có thể điều chỉnh thông số này nhằm giúp gpt đưa ra câu trả lời ngắn gọn hơn, nhanh hơn và đảm bảo độ chính xác hơn vì có khả năng gpt sẽ sinh ra nhiều hơn những gì bạn cần.
response = client.chat.completions.create(
model="gpt-35-turbo",
max_tokens=1024,
messages=[
{"role": "system", "content": "You are an assistant"},
{"role": "user", "content": "Who were the founders of Microsoft?"}
]
)
3. Đảm bảo tính ổn định bằng các thông số đầu vào khi call gpt
Ở phần trên tôi đã hướng dẫn cách thiết lập max tokens khi call gpt, bên cạnh những thông số ở ví dụ trên, azure openai còn hỗ trợ các thông số giúp tối ưu respone của gpt. Trong phần này chúng ta sẽ tập trung vào 3 thông số giúp ổn định output của gpt qua nhiều lần call là temperature, top_p và sheet.
Việc ổn định output là vô cùng cần thiết để bạn có thể đánh giá độ chính xác của cả hệ thống. Bạn đương nhiên sẽ không muốn việc sau cả tiếng tối ưu prompt để có được câu trả lời ưng ý, vẫn là prompt đó nhưng khi bạn thử lại thì lại nhận được câu trả lời khác.
temperature: giá trị nhận vào là float hoặc null, nếu bạn không truyền vào thì giá trị mặc định sẽ là 1. Các giá trị cao hơn như 0,8 sẽ làm cho output ngẫu nhiên hơn (có thể hiểu là sáng tạo hơn và bất ổn định hơn), trong khi các giá trị thấp hơn như 0,2 sẽ làm cho output tập trung và ổn định hơn.top_p: giá trị nhận vào là float hoặc null, nếu bạn không truyền vào thì giá trị mặc định sẽ là 1. Một giải pháp thay thế cho temperature, được gọi là lấy mẫu hạt nhân, trong đó mô hình xem xét kết quả của vô số các kết quả có thể sinh ra theo xác suất top_p. Vì vậy, 0,1 có nghĩa là chỉ 10% kết quả cao nhất mới được xem xét.top_pvàtemperatuređược khuyên là nên sử dụng khi call gpt, nhưng chỉ nên sử dụng 1 trong 2.seed: giá trị nhận vào là int hoặc null. Nếu được chỉ định, hệ thống sẽ nỗ lực hết sức để tổng hợp kết quả 1 cách cố định, sao cho các yêu cầu lặp lại có cùng giá trị seed thì output sẽ trả về cùng một kết quả.
Sau đây là 1 ví dụ về cách sử dụng các thông số trên trong code:
result = self.chat_model.chat.completions.create(
model="gpt-35-turbo",
seed=1, # bạn có thể để là bất kì số nguyên nào
temperature=0.0, # có thể thay thế giá trị này bằng top_p
max_tokens=1024,
messages=[
{"role": "system", "content": "You are an assistant"},
{"role": "user", "content": "Who were the founders of Microsoft?"}
]
)
4. Nên yêu cầu đầu ra của GPT là dạng JSON
Nếu chúng ta không ràng buộc gì về định dạng đầu ra thì gpt sẽ mặc định trả về 1 đoạn text. Lời khuyên được đưa ra là không nên để mặc định như vậy vì sẽ rất khó để đảm bảo được nội dung nhận về có được như mong muốn hay không. Gpt thường có xu hướng giải thích cho những điều mình trả lời, nghe qua thì có vẻ là tốt nhưng không phải vậy.
Ví dụ: Bạn đưa vào 1 phép tính '1 + 1 = ?' và kết quả mong muốn nhận được là 2 nhưng câu trả lời có thể sẽ là 'đáp án là 2 vì ....'. Như vậy bạn sẽ rất khó lọc ra đáp án từ đoạn text trên.
Giải pháp đưa ra là nên yêu cầu gpt trả về theo định dạng json. Một ví dụ đơn giản:
output_format = json.dumps({'answer': 'your answer', 'explanation': 'explain your answer'})
prompt = f"""
...
Output must be in json format like this: {output_format}
...
"""
Việc đưa output thành json giúp bạn phân tách câu trả lời thành các phần riêng biệt, giúp dễ dàng trích xuất đáp án mong muốn. Tuy nhiên đôi khi gpt vẫn sẽ trả về sai json format vì có thêm các text thừa ngoài phần dict mong muốn. Vì vậy bạn cần thiết kế thêm 1 hàm parse_json để đảm bảo output nhận lại sẽ luôn đúng. Ý tưởng cho hàm này có thể là dùng package re để bắt tất cả những kí tự nằm trong {} ở đầu ra của gpt.
5. Viết prompt theo từng ý rõ ràng, cụ thể
Khi mới bắt đầu viết prompt chúng ta thường có xu hướng viết prompt thành 1 đoạn văn dài để mô tả công việc cần thực hiện. Sau quá trình thử nghiệm thì tôi nhận ra việc viết prompt dễ khiến gpt miss mất những thông tin cần thiết. Cách viết tối ưu là nên tách bạch các nhiệm vụ, yêu cầu, mô tả hoặc ví dụ thành từng phần riêng biệt. Sau đây là 1 cấu trúc mẫu cho prompt:
system_prompt = """
1. Introduction
...
2. Required rules
...
"""
QA_prompt = """
3. Input
...
4. Input description
...
5. Output format
...
"""
Bên trong từng mục cũng nên tách thành các gạch đầu dòng cho từng ý thay vì cả 1 đoạn văn.
Ngoài ra, khi viết prompt bạn nên viết đúng chính tả, ngữ pháp bằng tiếng Anh và tránh dùng những từ ngữ đa nghĩa dễ khiến gpt hiểu sai yêu cầu. Nên cố gắng truyền tải yêu cầu của bạn theo cách đơn giản và dễ hiểu nhất có thể. Prompt càng phức tạp, càng yêu cầu tính suy luận cao thì độ ổn định của câu trả lời càng giảm. Bạn nên cân nhắc điều này.
Tổng kết
Bằng cách áp dụng những lưu ý quan trọng mà chúng ta đã thảo luận trong bài viết này, bạn có thể tận dụng sức mạnh của Azure OpenAI một cách hiệu quả và đạt được kết quả tốt nhất trong công việc của mình.
Hãy nhớ rằng việc viết prompt chính xác và sử dụng các tham số điều khiển có thể ảnh hưởng đáng kể đến kết quả mà bạn nhận được. Thường xuyên thử nghiệm và điều chỉnh prompt của bạn để tối ưu hóa quá trình tương tác với Azure OpenAI.
Hy vọng rằng bài viết này đã giúp bạn có cái nhìn tổng quan và những lưu ý cần thiết để viết prompt và sử dụng Azure OpenAI một cách hiệu quả. Nếu bạn có bất kì ý kiến hay thắc mắc gì thì đừng ngần ngại để lại comment nhé ^^.
All rights reserved
