
LLM agent: Tổng quan về LLM agent
Bài đăng này đã không được cập nhật trong 2 năm
Mở đầu:
Trong bối cảnh trí tuệ nhân tạo phát triển nhanh chóng, LLM agents (các tác nhân mô hình ngôn ngữ lớn) đang trở thành một bước tiến quan trọng, mang lại những lợi ích vượt trội so với các mô hình ngôn ngữ lớn (LLM) thông thường. Mặc dù LLM thông thường đã cho thấy khả năng xử lý ngôn ngữ tự nhiên ấn tượng và cung cấp câu trả lời dựa trên dữ liệu đào tạo, chúng vẫn còn hạn chế trong việc thực hiện các tác vụ phức tạp và yêu cầu quản lý quy trình đa bước. LLM agents, ngược lại, không chỉ hiểu và xử lý ngôn ngữ mà còn có khả năng lên kế hoạch, ra quyết định, và thực hiện các hành động cụ thể dựa trên ngữ cảnh và mục tiêu đề ra. Điều này cho phép LLM agents hoạt động một cách linh hoạt và hiệu quả hơn trong các tình huống thực tế, giúp tối ưu hóa quy trình làm việc, nâng cao trải nghiệm người dùng và mở ra nhiều ứng dụng mới trong các lĩnh vực như kinh doanh, chăm sóc khách hàng và quản lý thông tin. Trong bài viết này, chúng ta sẽ đi vào tổng quan về LLM agents, cũng như một số loại AI agents và cách chúng hoạt động nhé.

1. LLM (Large Language Model)
Tuy nhiên, trước khi đi vào khái niệm của LLM agent, thì chúng ta sẽ tìm hiểu xơ qua về LLM (Large Language Models) là gì nhé.
Định nghĩa:
Large Language Models là các mô hình ngôn ngữ với số lượng tham số rất lớn, thường được đào tạo trên hàng tỷ từ, từ hàng triệu tài liệu. Những mô hình này có khả năng hiểu và tạo ra văn bản bằng cách sử dụng các cấu trúc ngôn ngữ phức tạp mà chúng học được từ dữ liệu đào tạo.
1. Các ví dụ nổi bật:
- Mô hình GPT-4 của nhà OpenAI
- Gemini một mô hình đến từ nhà Google.
- Llama tới từ nhà Meta
Cách các mô hình LLM được tạo ra:
Kiến trúc Transformer:
Kiến trúc Transformer, được giới thiệu lần đầu bởi Vaswani et al. trong bài báo "Attention is All You Need" (2017), là nền tảng của hầu hết các LLM. Kiến trúc này sử dụng cơ chế tự chú ý (self-attention) để xác định mối quan hệ giữa các từ trong một câu mà không phụ thuộc vào khoảng cách giữa chúng. Điều này giúp mô hình có thể xử lý các ngữ cảnh phức tạp và tạo ra các câu văn mạch lạc.
Quá trình đào tạo:
LLM được đào tạo bằng cách sử dụng một lượng lớn dữ liệu văn bản từ nhiều nguồn khác nhau. Quá trình này bao gồm hai giai đoạn chính:
- Pre-training: Mô hình được đào tạo trên một tập dữ liệu rất lớn để học cách dự đoán từ tiếp theo trong một chuỗi từ. Giai đoạn này giúp mô hình học các cấu trúc ngôn ngữ và ngữ nghĩa cơ bản. Các bạn có thể đọc bài viết Generative-Pretraining của GPT model để hiểu rõ hơn.
- Fine-tuning: Sau khi pre-training mô hình khả năng hỏi và trả lời của mô hình vẫn rất tệ, mô hình cần được tinh chỉnh (fine-tuning) trên các tập dữ liệu có thể là dạng instructions, điều này giúp mô hình có khả năng hỏi và trả lời các câu hỏi mà người dùng đưa vào.
Khả năng của LLM:
Nhờ vào việc huấn luyện các mô hình LLM với dữ liệu siêu khổng lồ như vậy, nên chúng có một số khả năng cực kỳ đáng kinh ngạc:
- Khả năng hiểu ngữ cảnh: Có khả năng hiểu được ngữ cảnh cực kỳ rộng, như một đoạn văn dài, hoặc thậm chí là một bài báo.
- Có thể thực hiện nhiều nhiệm vụ: Thông thường các mô hình trước đây chỉ thực hiện được một công việc cụ thể như translation, Summary...v...v. Tuy nhiên đối với LLM, nó có thể thực hiện được nhiều công việc khác nhau.
- Khả năng in contex learning: Là khả năng hiểu ngữ cảnh cực kỳ mạnh mẽ của LLM. Có thể thực hiện bất kỳ nhiệm vụ nào chưa được thấy qua chỉ cần đưa cho chúng một vài chỉ dẫn.
LLM agent
LM Agent được coi như là một hệ thống AI tự động, sử dụng các mô hình LLM như một bộ não trung tâm, để thực hiện các tác vụ phức tạp thông qua việc hiểu và xử lý ngôn ngữ tự nhiên. Các LLM agents không chỉ giới hạn ở việc tạo văn bản dựa hay trả lời trên input của người dùng như LLM thông thường, mà còn có khả năng tương tác với các hệ thống khác (Tool Use), lập kế hoạch (Planning), học hỏi từ kinh nghiệm và đưa ra các hành động cụ thể dựa trên ngữ cảnh và mục tiêu được đặt ra.
Một LLM agent hoạt động thông qua một quy trình có cấu trúc từ khi người dùng nhập thông tin đầu vào cho đến khi nhiệm vụ được hoàn thành. Đầu tiên, người dùng nhập một yêu cầu hoặc câu hỏi vào hệ thống. LLM agent sau đó sẽ phân tích và hiểu ngữ cảnh của yêu cầu này, sử dụng khả năng reasoning của LLM để giải mã ý định của người dùng. Tiếp theo, LLM agent xây dựng một kế hoạch hành động, chia nhiệm vụ lớn thành các bước nhỏ hơn, có thể quản lý được.
Trong quá trình thực hiện, LLM agent có khả năng tương tác với các hệ thống khác( Ví dụ: Web search, Call API...v...v) hoặc thu thập thêm dữ liệu cần thiết để hoàn thành nhiệm vụ. Nó thực hiện từng bước theo kế hoạch đã định. Cuối cùng, sau khi hoàn thành tất cả các bước, LLM agent tổng hợp kết quả và cung cấp câu trả lời hoặc thực hiện hành động cụ thể mà người dùng yêu cầu, đảm bảo rằng nhiệm vụ được hoàn thành một cách chính xác và hiệu quả.
Qua quá trình này, LLM agent không chỉ đơn thuần là một công cụ trả lời câu hỏi mà còn là một trợ lý thông minh có khả năng giải quyết các vấn đề phức tạp và thực hiện nhiều tác vụ đa dạng.
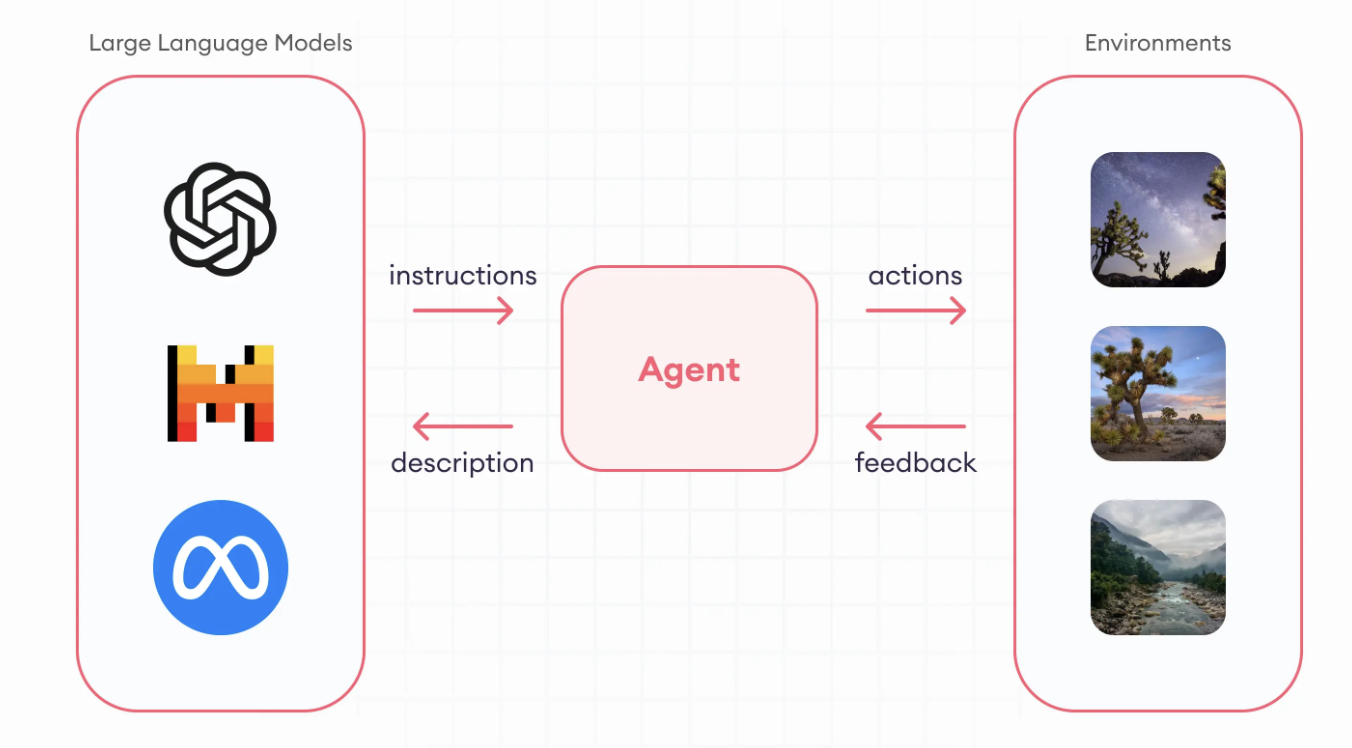
Sự Khác Biệt Giữa LLM Cơ Bản và LLM Agents
1. LLM Cơ Bản với Hệ Thống RAG (Retrieval Augmented Generation):
- Khả Năng: Một hệ thống LLM cơ bản sử dụng RAG có thể dễ dàng tìm kiếm và lấy thông tin cần thiết từ các cơ sở dữ liệu pháp lý để trả lời các câu hỏi cụ thể. Lấy một câu hỏi ví dụ như: "Các kết quả pháp lý tiềm năng của một loại vi phạm hợp đồng cụ thể ở Việt Nam là gì?", hệ thống có thể truy cập và cung cấp thông tin liên quan đến các hậu quả pháp lý của việc vi phạm hợp đồng tại Việt Nam.
- Hạn Chế: Hệ thống này chỉ tập trung vào việc lấy thông tin và có thể thiếu khả năng kết nối các luật pháp với các tình huống kinh doanh thực tế hoặc phân tích sâu các quyết định của tòa án.
2. LLM-based agent:
- Khả năng: Giả sử, chúng ta có một câu hỏi rất phức tạp như sau ở đây: "Dựa trên các luật bảo vệ dữ liệu mới, những thách thức pháp lý phổ biến mà các công ty phải đối mặt là gì, và các tòa án đã giải quyết những vấn đề này như thế nào?". LLM agents có thể vượt trội hơn. Các LLM agents không chỉ lấy thông tin mà còn có thể hiểu các quy định mới, phân tích cách các quy định này ảnh hưởng đến các công ty khác nhau, và nghiên cứu các quyết định của tòa án liên quan.
- Phương Pháp: LLM agents thực hiện các nhiệm vụ này thông qua việc chia nhỏ câu hỏi thành các nhiệm vụ con:
- Truy Cập Dữ Liệu Pháp Lý: Truy cập các cơ sở dữ liệu pháp lý để lấy thông tin mới nhất về các luật và quy định.
- Thiết Lập Bối Cảnh Lịch Sử: Thiết lập một cơ sở lịch sử về cách các vấn đề tương tự đã được xử lý trước đây.
- Tóm Tắt Tài Liệu Pháp Lý: Tóm tắt các tài liệu pháp lý và dự đoán các xu hướng tương lai dựa trên các mẫu đã quan sát được.
- Yêu cầu: Tuy nhiên, để hoàn thành các nhiệm vụ này, LLM agents cần có một kế hoạch cấu trúc, một bộ nhớ đáng tin cậy để theo dõi tiến độ và truy cập vào các bộ tools cần thiết. Những yếu tố này tạo nên xương sống của quy trình làm việc của LLM agents.
Các thành phần của một LLM agent
Thật ra thì để xây dựng một LLM agent, chúng ta chỉ đợn giản là sử dụng LLM và tương tác với các hệ thống khác (Agent tools) như: Web search, code interpreter, API.v. Hoặc chúng ta cũng có thể chỉ cần sử dụng các phương pháp planning để lên kế hoạch giải quyết câu hỏi đầu vào của người dùng (Agent planning). Như vậy cũng đã được coi như là một agent theo khái niệm định nghĩa về agent rồi.  )
)
Nhưng thông thường, một hệ thống LLM agent hoàn chỉnh sẽ bao gồm tất cả các thành phần như: Lên planning chia nhỏ nhiệm vụ lớn thành nhiệm vụ nhỏ, sau đó đưa ra quyết định sử dụng tools nào để giải quyết các công việc hay sử dụng thêm memory để giúp agent có thể lưu trữ history tương tác với người dùng trước đó.
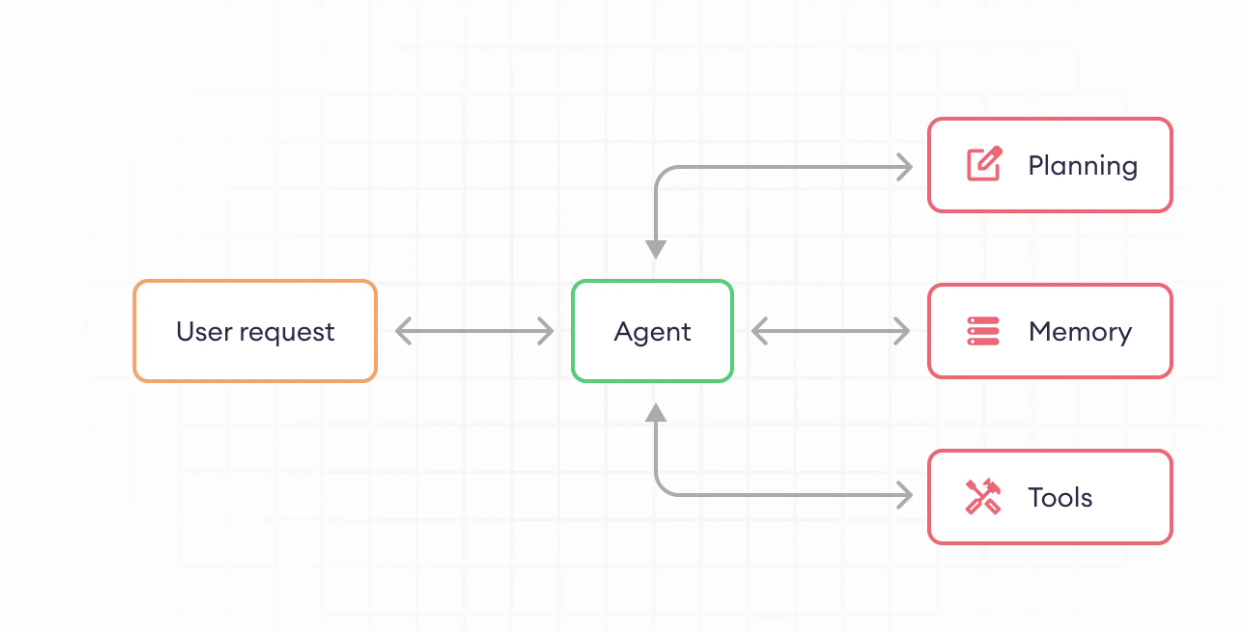
1. Agent/brain
Cốt lõi của một LLM agent là một mô hình ngôn ngữ có khả năng xử lý và hiểu ngôn ngữ dựa trên một lượng dữ liệu khổng lồ mà nó đã được huấn luyện trước đó.
Khi sử dụng một LLM agent, bước đầu tiên là đưa ra một prompt cụ thể. Prompt này rất quan trọng vì nó sẽ hướng dẫn agent cách phản hồi, Tools nào cần sử dụng và các mục tiêu mà nó cần đạt được trong suốt quá trình tương tác. Giống như việc bạn đưa ra chỉ dẫn cho một người lái xe trước khi bắt đầu chuyến đi.
Thêm vào đó, bạn có thể tùy chỉnh agent với một persona cụ thể. Điều này có nghĩa là bạn thiết lập agent với những đặc điểm và chuyên môn riêng, giúp nó phù hợp hơn với các nhiệm vụ hoặc tình huống cụ thể. Đây là cách điều chỉnh agent để nó thực hiện các nhiệm vụ theo cách phù hợp nhất với yêu cầu của tình huống.
Về cơ bản, cốt lõi của một LLM agent là sự kết hợp giữa khả năng xử lý ngôn ngữ tiên tiến (LLM) và các tính năng tùy chỉnh, giúp nó xử lý và thích ứng hiệu quả với nhiều nhiệm vụ và tương tác khác nhau.
2. Planning:
Thông qua việc lập kế hoạch (planning), các LLM agents có thể suy luận, phân chia các nhiệm vụ phức tạp thành những phần nhỏ hơn, dễ quản lý hơn, và phát triển các kế hoạch cụ thể cho từng phần. Khi các nhiệm vụ tiến triển, các agents cũng có thể phản ánh và điều chỉnh kế hoạch của mình, đảm bảo rằng chúng luôn phù hợp với các tình huống thực tế. Khả năng thích ứng này là chìa khóa để hoàn thành nhiệm vụ thành công. Việc lập kế hoạch thường bao gồm hai loại: Planning without feedback và planning with feedback.
Planning without feedback: Phương pháp lập kế hoạch này thường tận dụng khả năng của chính các mô hình LLM để chia các task lớn thành các subtask nhỏ hơn. Các phương pháp phổ biến cho việc phân tách task như: Chain of Thought (CoT), Tree of Thought (ToT).
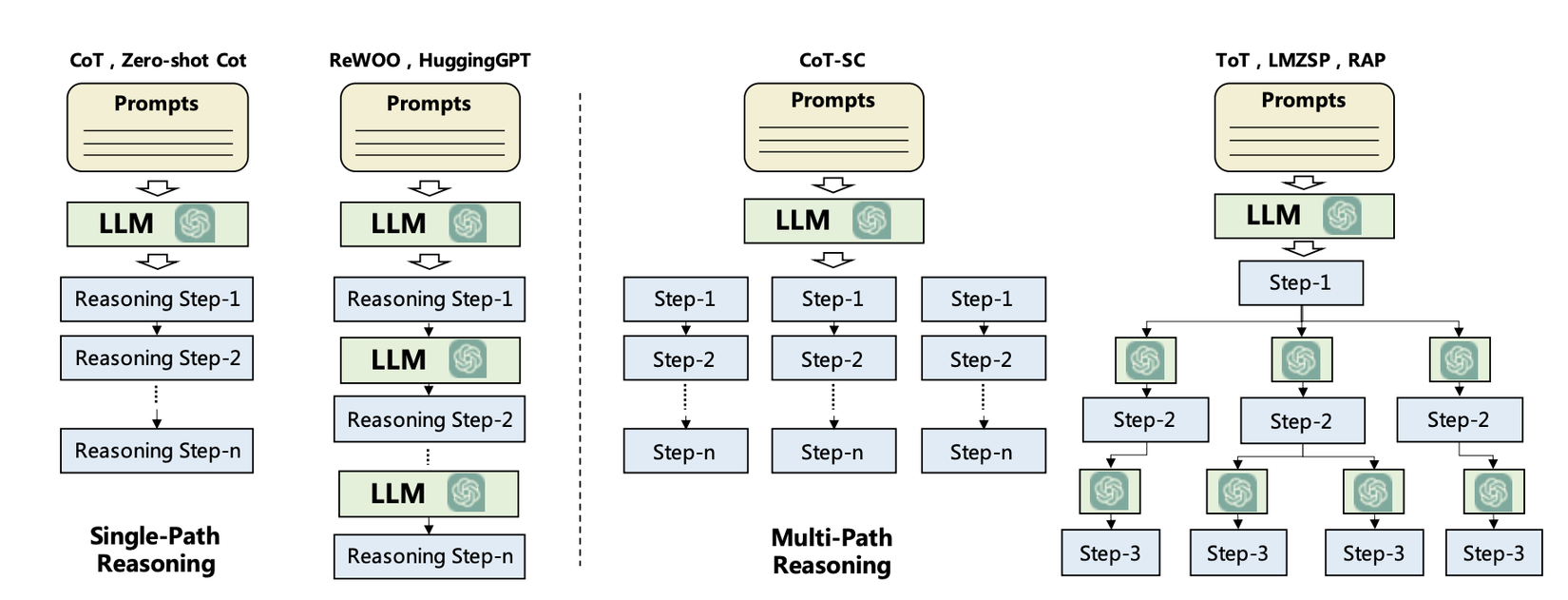
1. Chain of Thought (CoT): Là một phương pháp prompting giúp mô hình reasoning và break yêu cầu đầu vào thành thành nhiều steps. Việc này giúp mô hình có thể lên kế hoạch và giải quyết từng công việc nhỏ một cách tuần tự, và cuối cùng là thoành thành công việc tổng thể. Bằng cách chia nhỏ các nhiệm vụ phức tạp, CoT giúp mô hình tiếp cận và giải quyết vấn đề một cách có hệ thống và hiệu quả hơn.
2. Tree of Thought (ToT): Đây là một phương pháp dạng Multi-Path reasoning. Phương pháp này hoạt động bằng cách mô hình hóa quá trình reasoning dưới dạng một cấu trúc cây. Đầu tiên, vấn đề cần giải quyết được xác định rõ ràng. Sau đó, bắt đầu từ trạng thái suy nghĩ ban đầu, ToT được phát triển bằng cách tạo ra các nhánh mới đại diện cho các hành động hoặc quyết định có thể được thực hiện. Tại mỗi node của cây, các nhánh tiềm năng được đánh giá dựa trên các tiêu chí nhất định để chọn ra nhánh tốt nhất. Quá trình này được lặp lại cho đến khi đạt được trạng thái giải quyết vấn đề hoặc đưa ra quyết định cuối cùng. Bằng cách này, ToT giúp tổ chức suy nghĩ một cách có cấu trúc, đánh giá các khả năng khác nhau một cách hệ thống và tăng khả năng đạt được giải pháp tối ưu.
Planning with feedback: Một điểm yếu của việc lập planning mà không có bất kỳ sự feedback nào, sẽ khiến cho mô hình không có khả năng refine lại những quyết định của mình. Để khắc phục điều này, chúng ta sẽ tận dụng cơ chế feedback lặp đi lặp lại và refine kế hoạch thực hiện dựa trên các action và observations trong quá khứ. Mục tiêu là sửa chữa và cải thiện những lỗi sai trong quá khứ, điều này giúp nâng cao được chất lượng kết quả cuối cùng. Hai kỹ thuật phổ biến cho điều này là ReAct và Reflexion.
3. Memory:
Memory của LLM agent giúp chúng xử lý các nhiệm vụ phức tạp của LLM bằng cách lưu trữ những gì đã làm trước đó. Có hai loại memory chính:
Short memory: Đây giống như cuốn sổ ghi chú của agent, nơi nó nhanh chóng ghi lại các chi tiết quan trọng trong suốt cuộc trò chuyện. Nó theo dõi cuộc thảo luận đang diễn ra, giúp mô hình phản hồi phù hợp với ngữ cảnh hiện tại. Tuy nhiên, bộ nhớ này chỉ là tạm thời và sẽ được xóa sau khi nhiệm vụ hiện tại hoàn thành.
Long-term memory: Hãy nghĩ về điều này như cuốn nhật ký của con agent, nó lưu trữ những hiểu biết và thông tin từ các tương tác trong quá khứ trong suốt nhiều tuần hoặc thậm chí nhiều tháng. Đây không chỉ là việc giữ dữ liệu, mà là hiểu các mẫu, học hỏi từ các nhiệm vụ trước đó và nhớ lại thông tin này để đưa ra các quyết định tốt hơn trong các tương tác tương lai.
Về cơ bản thì chúng ta có thể sử dụng chỉ Short hoặc chỉ Long-term memory. Hoặc thậm chí kết hợp hai loại memory này lại với nhau, nếu như kết hợp chúng lại với nhau mô hình có thể theo kịp các cuộc trò chuyện hiện tại và khai thác cả vào các tương tác trong lịch sử. Điều này có nghĩa là nó có thể cung cấp các phản hồi phù hợp hơn và nhớ các sở thích của người dùng theo thời gian, hay làm cho mỗi cuộc trò chuyện trở nên gắn kết và phù hợp hơn. Về bản chất, agents đang xây dựng một sự hiểu biết giúp nó phục vụ tốt hơn trong mỗi tương tác với người dùng.
4. Tool use:
Việc sử dụng các tools giúp cho con LLM agent có thể tương tác được với môi trường bên ngoài. Ví dụ như: Sử dụng web search API, knowledge bases hoặc các external models như trên huggingface.
Các LLM agents sẽ sử dụng tập hợp các tools được thiết lập trước đó. Chúng nó sẽ thực hiện xác định xem tool nào sẽ được sử dụng để hoàn thành công việc được yêu cầu từ phía Users.
Multi-LLM agent
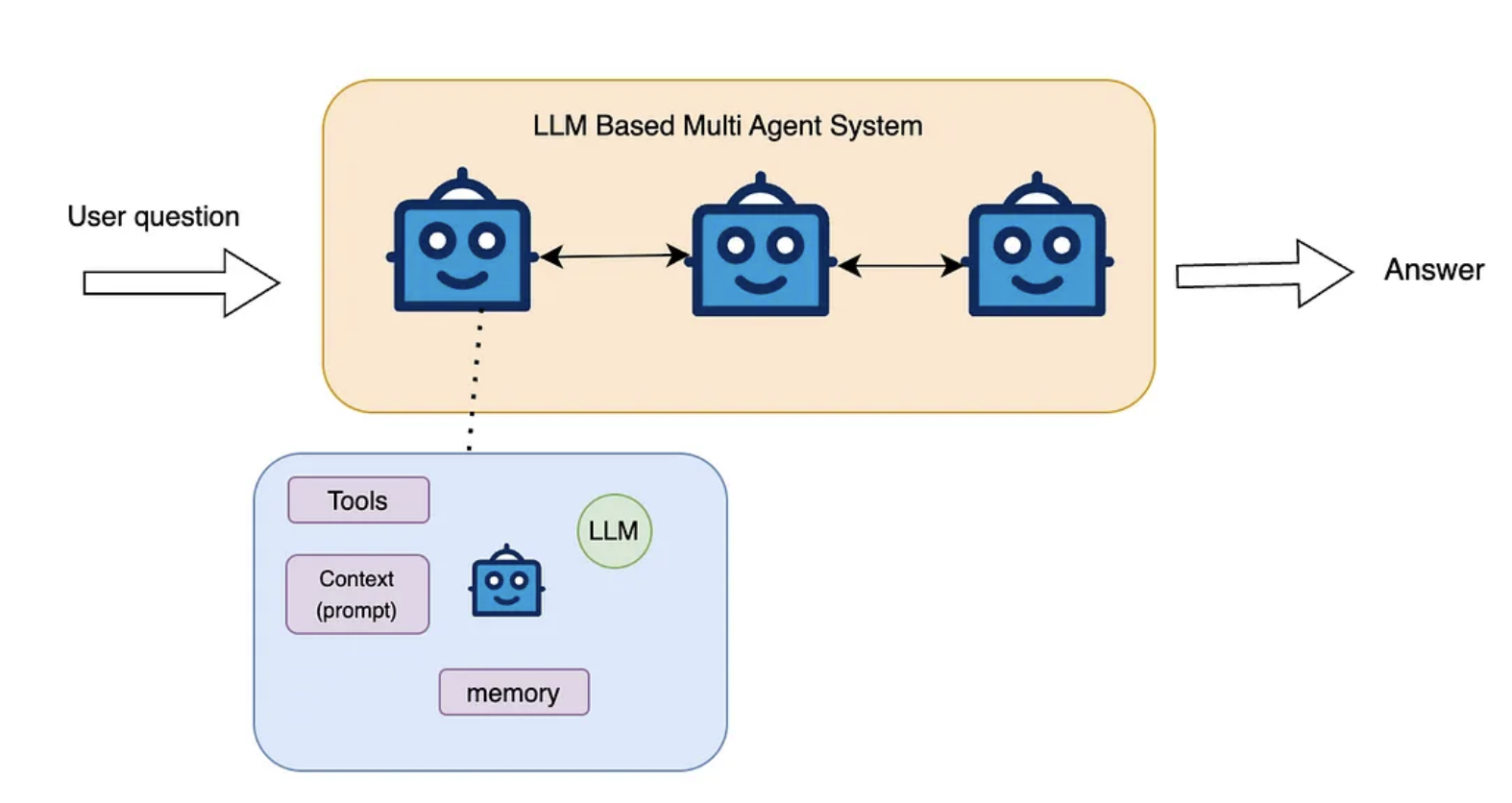
Nếu một người không làm được thì chúng ta sẽ lập một team để làm việc, và nó được gọi là teamwork. Và LLM agent cũng vậy. Trong đó, mỗi LLM agent sẽ đảm nhiệm một nhiệm vụ và chúng sẽ kết hợp lại với nhau tạo thành Multi LLM agents để giải quyết công việc và đạt được mục tiêu cuối cùng.
1. Sequential Multi-agent system:
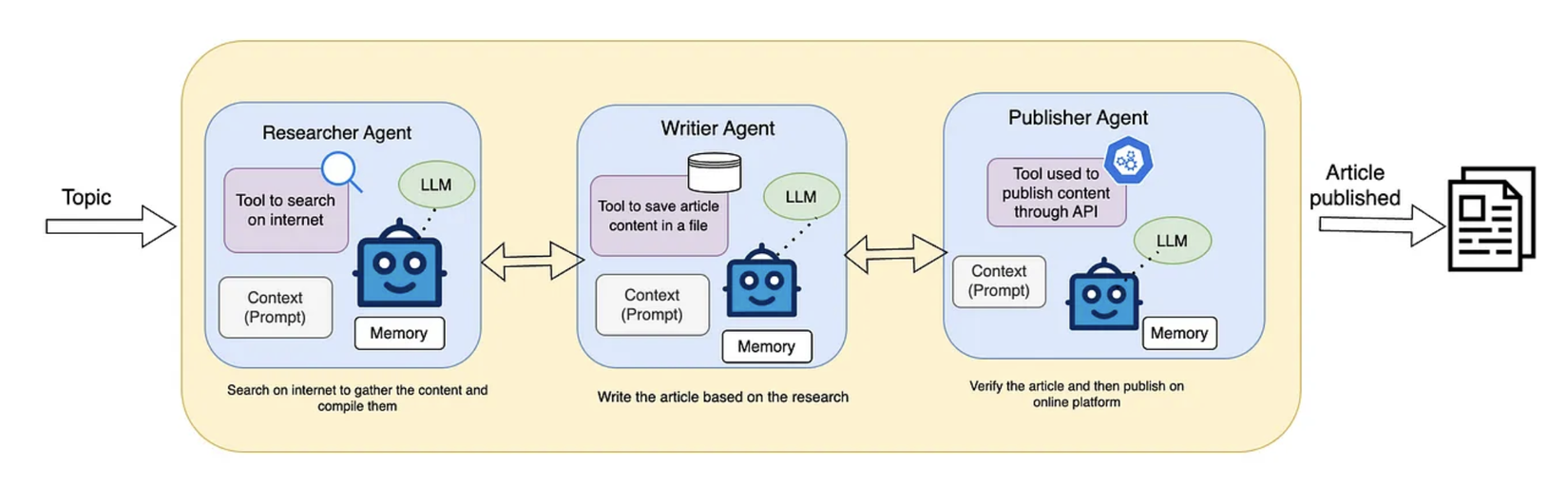
Ở đây, giả sử chúng ta có một hệ thống LLM agent có nhiệm vụ và nhận đầu vào là một topic và đầu ra sẽ là một bài báo về topic đó. Và chúng ta sẽ có 3 agent để thực hiện nhiệm vụ này là Researcher Agent, Writier Agent và Publisher Agent.
- Đầu tiên, sẽ thực hiện thu thập các thông tin, dữ liệu về topic đó. Chúng ta sẽ sử dụng Researcher Agent để để truy cập vào các tools như web search, từ đó agent này sẽ thu thập tất cả các nội dung, dữ liệu về topic trên internet và tổng hợp chúng lại.
- Bước tiếp theo, chúng ta sẽ tử dụng Writier Agent để thực hiện viết nội dung cho topic đó, dựa vào những gì đã thu thập được trên internet.
- Bước cuối cùng là kiểm tra xem bài viết có phù hợp để đăng không, vd. kiểm tra đạo văn, ngữ pháp, v.v. rồi đăng nó. Chúng ta có Publisher Agent sẽ phụ trách nhiệm vụ này và sau khi hoàn thành bài báo sẽ được xuất bản.
Như có thể thấy, mỗi LLM agent sẽ có một nhiệm vụ riêng biệt. Nhưng LLM agent này sẽ được lên plainning và prompting chi tiết về những nhiệm vụ cần phải làm, những tools nào sẽ được sử dụng để hoàn thành nhiệm vụ một cách chính xác nhất.
Vậy thì các agent này có tương tác và feedback không nhỉ? Tất nhiên là có rồi. Giả dụ, trong trường hợp Writier Agent đánh giá dữ liệu thu thập được từ Researcher Agent là không đủ chất lượng hoặc không đủ dài so với yêu cầu đề ra để viết thành một bài thì Agent này ngay lập tức sẽ feedback lại cho Researcher Agent tiếp tục research. Hay Khi Publisher Agent thấy nội dung của bài báo đang có dấu hiệu đạo văn hoặc sai ngữ pháp quá nhiều, nó sẽ feedback lại và yêu cầu Writier Agent phải refine lại nội dung của bài báo.
2. Hierarchical Multi-agent system:
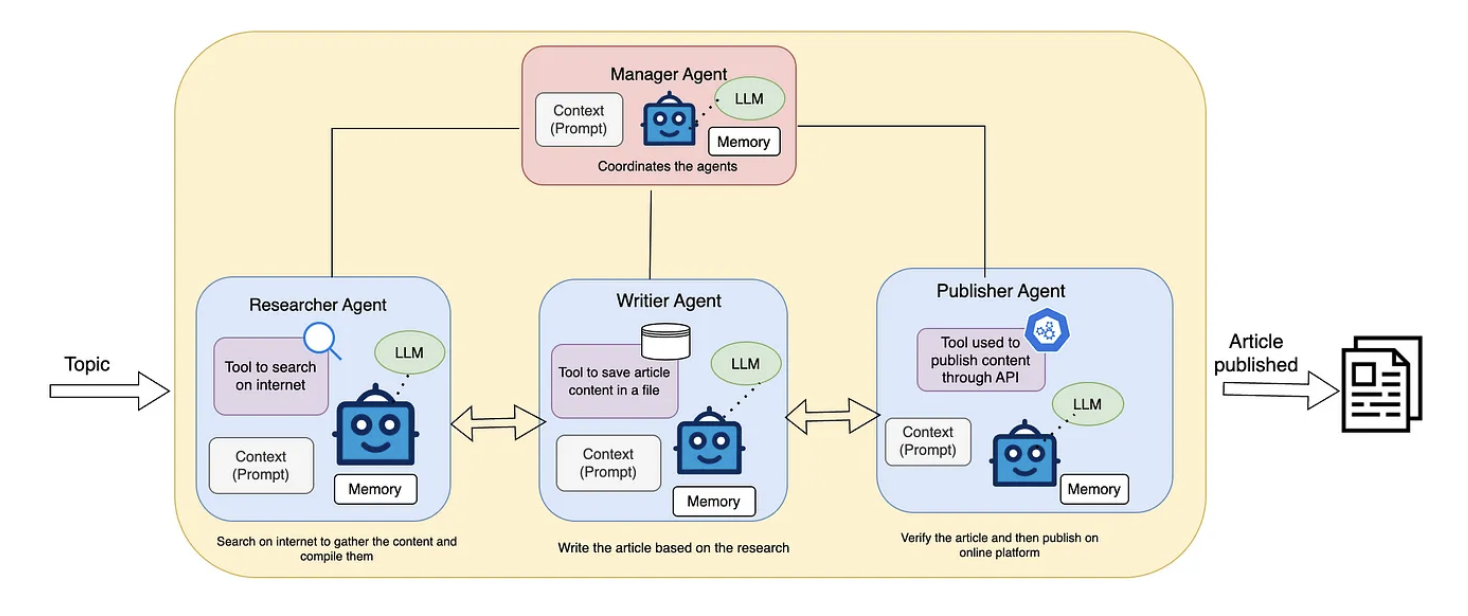 Nếu như đối với Sequential Multi-agent chúng ta xử lý các nhiệm vụ theo quá trình tuần tự các agent sẽ tự giao tiếp với nhau và sửa lỗi, điều này giống như việc trong một team làm việc mà không có người leader vậy. Ngược lại, đối với Hierarchical Multi-agent nó sẽ tạo ra một con manager agent, con agent này sẽ đảm nhiệm nhiệm vụ của một người leader, nó sẽ phụ trách việc điều phối công việc, giao task cho các agent cấp thấp hơn và đánh giá kết quả.v.v.
Nếu như đối với Sequential Multi-agent chúng ta xử lý các nhiệm vụ theo quá trình tuần tự các agent sẽ tự giao tiếp với nhau và sửa lỗi, điều này giống như việc trong một team làm việc mà không có người leader vậy. Ngược lại, đối với Hierarchical Multi-agent nó sẽ tạo ra một con manager agent, con agent này sẽ đảm nhiệm nhiệm vụ của một người leader, nó sẽ phụ trách việc điều phối công việc, giao task cho các agent cấp thấp hơn và đánh giá kết quả.v.v.
3. Human in the loop in the multi-agent system:
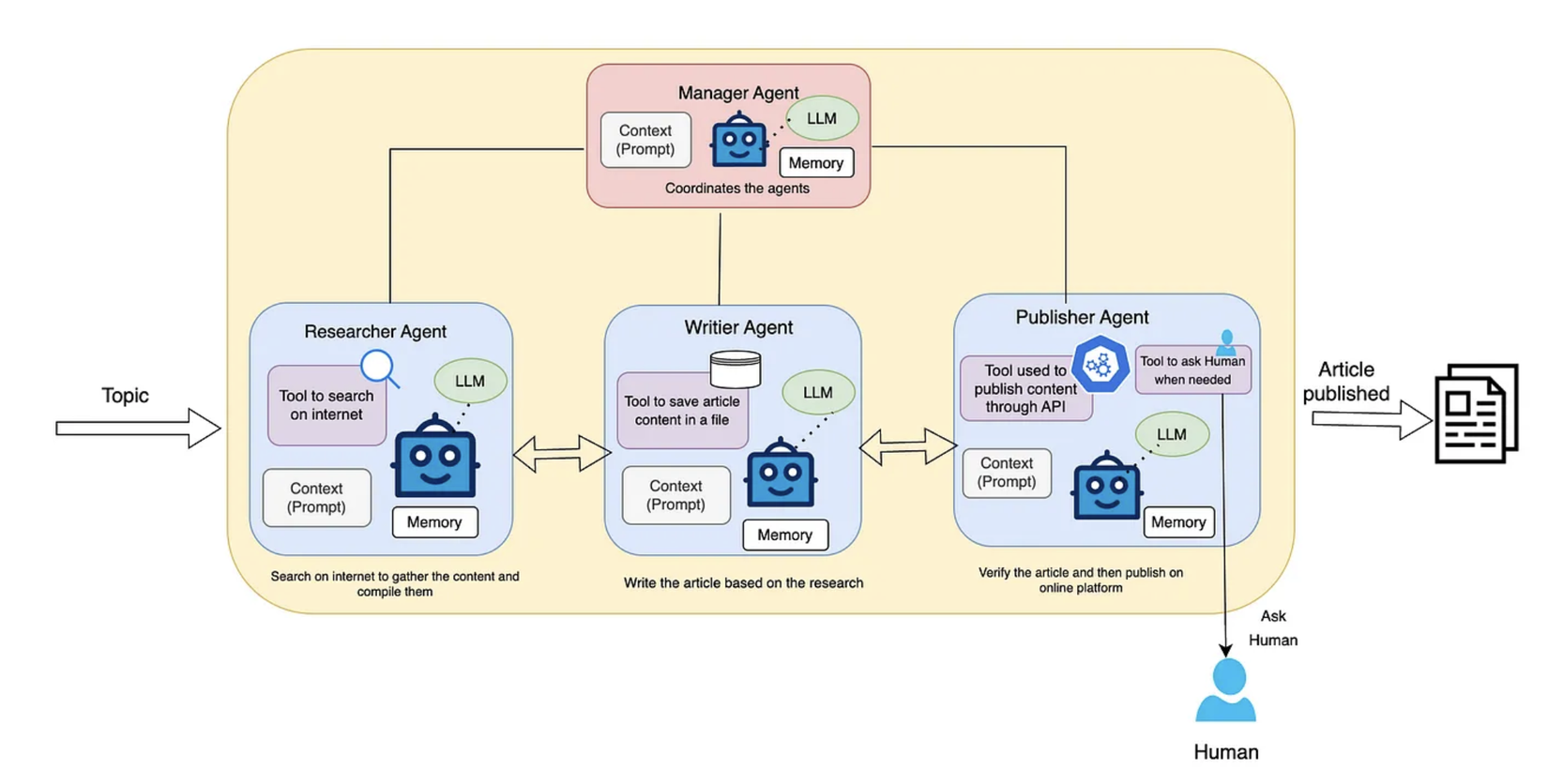
Đôi lúc, các LLM-agent cũng cần đến sự can thiệp và trợ giúp của con người nhằm đưa ra quyết định chính xác hơn. Ví dụ như trong hình phía trên, khi Publisher Agent không chắc chắn về quyết định của mình nó sẽ đưa ra yêu cầu cần sự can thiệp của con người nhằm đánh giá xem chất lượng xem bài báo có nên đăng hay không.
Sự phát triển của LLM Agents
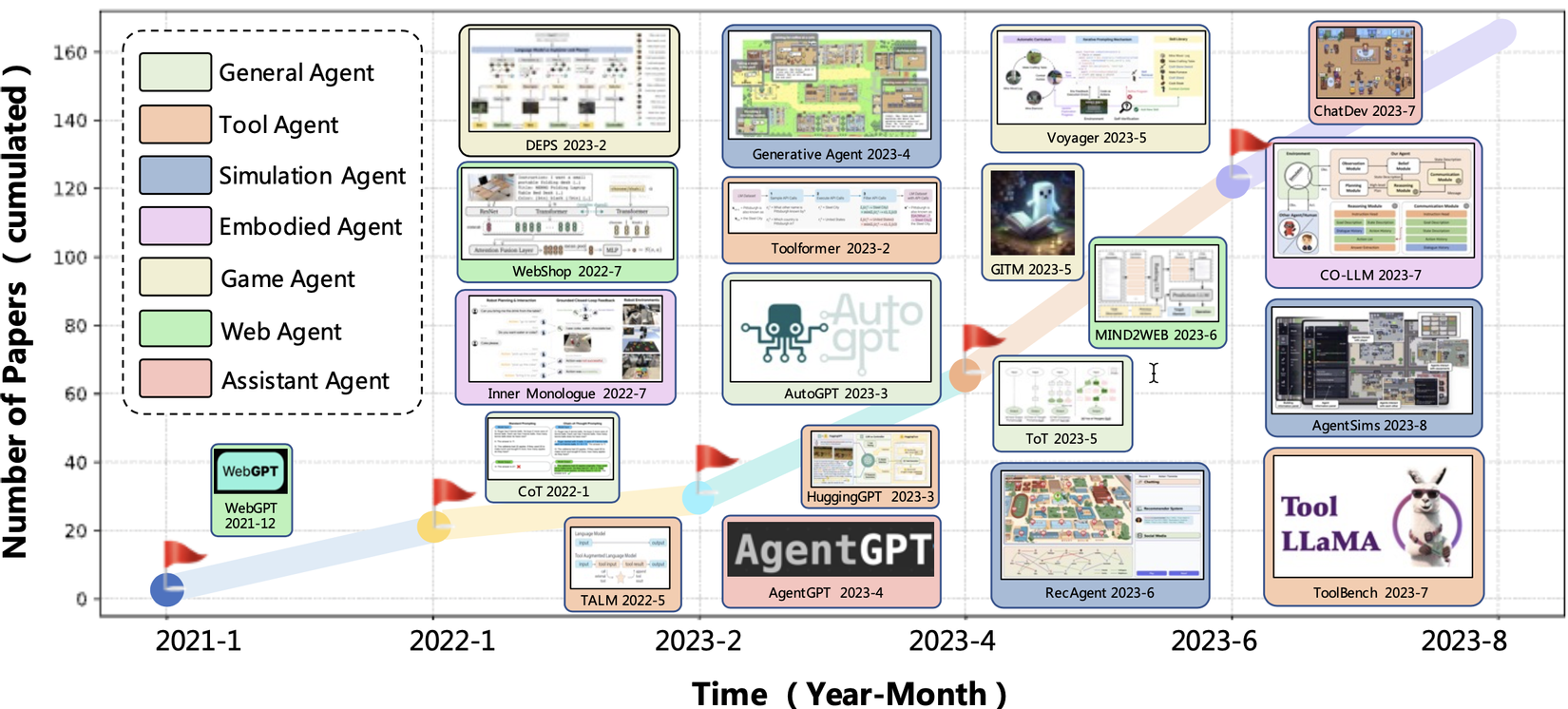
Các LLM agents đã trải qua một sự phát triển nhanh chóng, được minh họa bằng sự gia tăng đáng kể số lượng các bài báo liên quan đến chủ đề này theo thời gian. Từ cuối năm 2021 với sự ra đời của WebGPT, số lượng nghiên cứu đã tăng lên đều đặn, đạt đến đỉnh điểm vào giữa năm 2023.
Các LLM agents được phân loại theo nhiều loại hình khác nhau, bao gồm General Agent, Tool Agent, Simulation Agent, Embodied Agent, Game Agent, Web Agent, và Assistant Agent. Mỗi loại hình này đại diện cho các ứng dụng và khả năng khác nhau của LLM agents trong việc giải quyết các tác vụ và vấn đề cụ thể.
Một số cột mốc quan trọng trong hành trình này bao gồm:
- WebGPT (2021-12): Đánh dấu bước đầu tiên trong việc phát triển các LLM agents.
- CoT (2022-1): Đưa ra các phương pháp mới trong việc lập kế hoạch
- AutoGPT (2023-3): Một trong những bước đột phá quan trọng, đưa các LLM agents lên một tầm cao mới với khả năng tự động hóa nhiều tác vụ phức tạp.
- AgentGPT (2023-4): Một đại diện khác của Tool Agent, mở ra nhiều khả năng ứng dụng thực tiễn.
- Generative Agent (2023-4) và Voyager (2023-5): Đại diện cho các Simulation Agent và Game Agent, cho thấy sự đa dạng trong ứng dụng của LLM agents.
- ToolBench (2023-7): Một trong những phát triển mới nhất, đại diện cho các Tool Agent.
Sự phát triển này cho thấy sự tiến bộ nhanh chóng trong lĩnh vực LLM agents, với các ứng dụng ngày càng đa dạng và phong phú, hứa hẹn nhiều tiềm năng trong tương lai.
Kết luận
Như có thể thấy, sức mạnh của các Large Language Model (LLM) không chỉ dừng lại ở khả năng suy luận ngôn ngữ của chúng. Khi chúng ta biết tận dụng tối đa những khả năng mạnh mẽ này, sẽ tạo ra những hệ thống AI tự động tương tác với con người ngày càng hoàn hảo hơn. Các LLM agent không chỉ cải thiện hiệu suất và độ chính xác trong nhiều lĩnh vực khác nhau, mà còn mang lại những trải nghiệm tương tác tự nhiên và liền mạch hơn cho người dùng.
Reference:
1. AI Pioneer Shows The Power of AI AGENTS - "The Future Is Agentic"
3. Understanding LLM-Based Agents and their Multi-Agent Architecture
All rights reserved
