
Hướng đi nào cho những người làm AI trong kỉ nguyên của các Super Large Models?
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
Có lẽ thời gian chỉ trong vòng vài tháng trở lại đây, thế giới công nghệ đã bị khuynh đảo bởi các mô hình AI như ChatGPT, GPT-4, DALLE-2, Midjourney... Các mô hình AI đã thực sự tạo được cho người dùng những cảm xúc wow và có thể thấy rằng đâu đâu cũng nói về nó. Có phải kỉ nguyên mới của AI có phải đã bắt đầu rồi không? Bản thân mình nghĩ là CÓ. NÓ THỰC SỰ ĐÃ BÁT ĐẦU. Và chúng ta, những người đang làm công việc liên quan đến lĩnh vực này chắc hẳn sẽ có rất nhiều những trăn trở và băn khoăn. Các bạn ạ, thực lòng mà nói thời gian qua bản thân mình cũng trăn trở rất nhiều về hướng đi sắp tới của AI. Mọi thứ diễn ra quá nhanh đến mức mà nếu chúng ta không nghiêm túc nhìn nhận lại vấn đề thì có lẽ chính chúng ta sẽ bị bỏ lại phía sau. Các mô hình AI đã tiến hoá một cách vượt bậc và gần như vượt cả con người trong một số tác vụ. Thời điểm này là một bước ngoặt của lịch sử công nghệ, và vậy thì một câu hỏi đặt ra là Chúng ta - những người đang làm trong lĩnh vực AI cả về Academic và Industry - sẽ phải đối diện với nó như thế nào?. Bài viết này là một số quan điểm mà mình tổng hợp được từ các nguồn đáng tin cậy trên internet xen lẫn một vài quan điểm cá nhân của mình. Nó có thể chưa hoàn thiện nhưng mong rằng sẽ đem lại cho các bạn một số góc nhìn đa chiều hơn. Chúng ta cùng nhau bắt đầu nhé
Từ perceptron đến các Super Large Models
Perceptron nhỏ bé
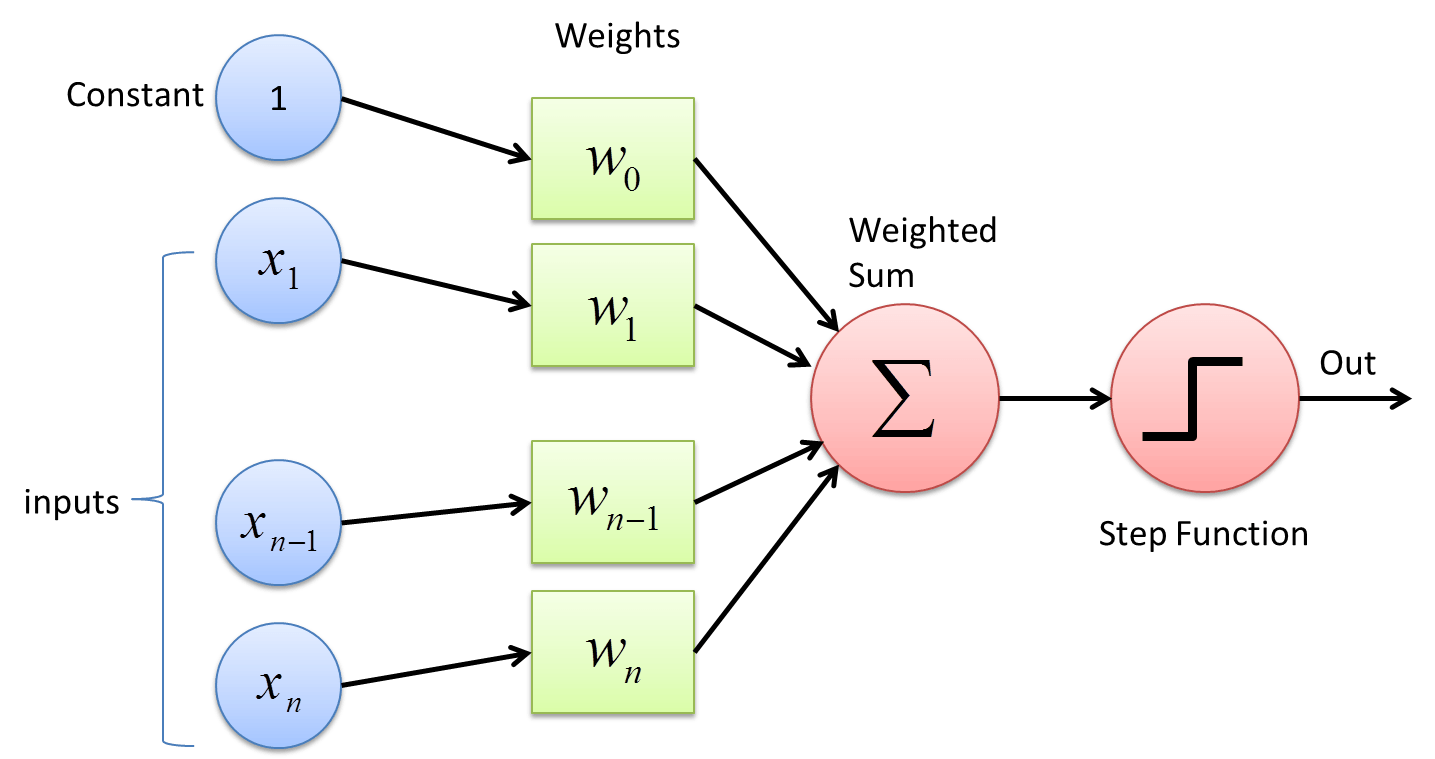
Có lẽ cần một chút thời gian để nói sâu hơn về lịch sử của mạng nơ ron. Ban đầu từ những năm 50 60 của thế kỉ trước. Perceptron được phát minh năm 1943 và được implement lần đầu tiên vào năm 1958 trên máy tính IBM 704. Lúc mới ra đời nó chỉ gồm một lớp và được thiết kết cho bài toán phân loại hình ảnh nhị phân. Khi mới ra đời, perceptron đã mang đến cho cộng đồng AI non trẻ thời đó một niềm tin rằng nó sẽ là phôi thai của một bộ não điện tử có thể thực hiện các tác vụ nghe, nhìn, đọc, viết và suy nghĩ được thậm chí là có thể tự tạo ra chính nó. Tất nhiên sau đó người ta nhanh chóng nhận những hạn chế của công nghệ và lý thuyết thuật toán thời đó chưa cho phép thực hiện những điều này.
Backpropagation và MLP
 Lịch sử của mạng nơ ron đã bị chậm lại vài chục năm cho đến khi các lý thuyết về backpropagation (lan truyền ngược) ra đời cho phép chúng ta có thể huấn luyện được các mạng nơ ron với nhiều lớp hơn (multi layer perceptron) và nhận diện được với nhiều loại class hơn. Đó là vào khoảng những năm 1985 của thế kỉ trước. Thế nhưng lịch sử của mạng nơ ron lại chững lại khoảng 30 năm sau đó dù các nghiên cứu lý thuyết về nó vẫn phát triển nhưng hầu hết chưa có ứng dụng thực tế nào phổ biến cho đến khoảng những năm 2012. Một lý do của giai đoạn ngủ đông này đó chính là các mạng nơ ron vẫn đòi hỏi một lượng dữ liệu và tài nguyên tính toán lớn mà các cấu hình máy tính thời đời chưa đủ để đáp ứng được điều đó.
Lịch sử của mạng nơ ron đã bị chậm lại vài chục năm cho đến khi các lý thuyết về backpropagation (lan truyền ngược) ra đời cho phép chúng ta có thể huấn luyện được các mạng nơ ron với nhiều lớp hơn (multi layer perceptron) và nhận diện được với nhiều loại class hơn. Đó là vào khoảng những năm 1985 của thế kỉ trước. Thế nhưng lịch sử của mạng nơ ron lại chững lại khoảng 30 năm sau đó dù các nghiên cứu lý thuyết về nó vẫn phát triển nhưng hầu hết chưa có ứng dụng thực tế nào phổ biến cho đến khoảng những năm 2012. Một lý do của giai đoạn ngủ đông này đó chính là các mạng nơ ron vẫn đòi hỏi một lượng dữ liệu và tài nguyên tính toán lớn mà các cấu hình máy tính thời đời chưa đủ để đáp ứng được điều đó.
CNN và các GPUs
 Mãi cho đến những năm 2013, khi AlexNet ra đời đánh dấu một bước ngoặt mới của mạng nơ ron tích chập đi kèm với nó là cách thực hiện huấn luyện dựa trên các GPU. Từ đây người ta có thể huấn luyện các mạng nơ ron với tốc độ nhanh hơn trước kia cả hàng trăm, hàng nghìn lần bằng cách sử dụng các chiến lược training trên nhiều GPUs (các bạn có thể tham khảo một bài viết trước đó của mình tại đây). Khỏi cần nói nhiều thì chúng ta cũng đã thấy được các ứng dụng to lớn của CNN trong các bài toán đặc biệt là computer vision trong đó có một yếu tố then chốt cho sự thành công này đó chính là sức mạnh của phần cứng GPUs
Mãi cho đến những năm 2013, khi AlexNet ra đời đánh dấu một bước ngoặt mới của mạng nơ ron tích chập đi kèm với nó là cách thực hiện huấn luyện dựa trên các GPU. Từ đây người ta có thể huấn luyện các mạng nơ ron với tốc độ nhanh hơn trước kia cả hàng trăm, hàng nghìn lần bằng cách sử dụng các chiến lược training trên nhiều GPUs (các bạn có thể tham khảo một bài viết trước đó của mình tại đây). Khỏi cần nói nhiều thì chúng ta cũng đã thấy được các ứng dụng to lớn của CNN trong các bài toán đặc biệt là computer vision trong đó có một yếu tố then chốt cho sự thành công này đó chính là sức mạnh của phần cứng GPUs
Transformer và Self-supervised Learning
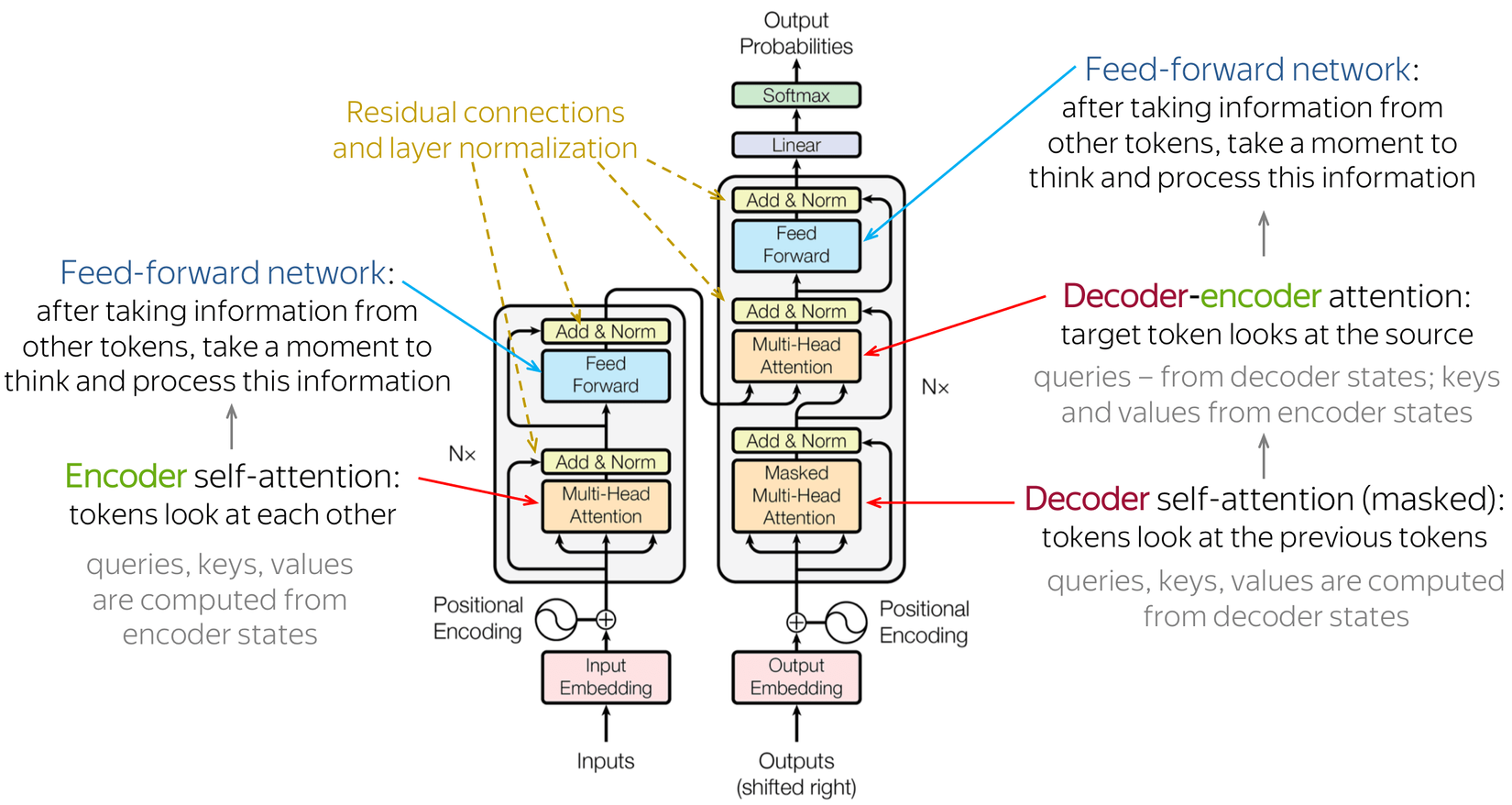
Có thể thấy các kiến trúc nổi tiếng hiện nay của các Large Models đều có nguồn gốc từ Transformer. Chính các ưu điểm của cơ chế Attention trong Transformer giúp nó có thể hiểu được mức độ liên quan của các thành phần trong input với nhau như thế nào. Và một ưu điểm vượt trội nữa của Transformer so với các mô hình seq2seq trước đó dựa trên kiến trúc của RNN không làm được đó chính là Transformer có thể tính toán song song cực tốt mà không bị phụ thuộc vào độ dài của câu như RNN. Việc này giúp cho Transformer dễ dàng scale up hơn với lượng dữ liệu lớn và đặc biệt là với các hệ thống nhiều GPUs. Đây là những điểm mạnh nổi trội nhất giúp nó đánh bại RNN đặc biệt trong các tác vụ học biểu diễn cho thông tin như text, hình ảnh, âm thanh...
Nói đến học biểu diễn thì không thể không nhắc đến các thành tựu của kĩ thuật self-supervised learning. Điều này đã loại bỏ hoàn toàn việc phụ thuộc vào lượng dữ liệu có nhãn từ con người. Các bạn có thể tưởng tượng rằng bản thân mô hình có thể học được rất nhiều các đặc trưng hữu ích mà hoàn toàn không bị can thiệp hay chi phối bởi các nhãn của con người. Chính điều này khiến cho việc các mô hình super large model có thể học ra được các tri thức rất phức tạp mà có lẽ chính con người tạo ra nó cũng không thể biết được thực chất trong mô hình tiềm ẩn những tri thức gì. Đó chính là thành công của self supervised. Khi mà lượng dữ liệu khổng lồ ngoài kia, qua vài chục năm phát triển của internet đã tích luỹ được hằng hà sa số những thông tin quý báu thì việc áp dụng self supervised với các mô hình siêu siêu lớn sẽ học ra được các thông tin siêu phức tạp.
Mô hình ngày càng to
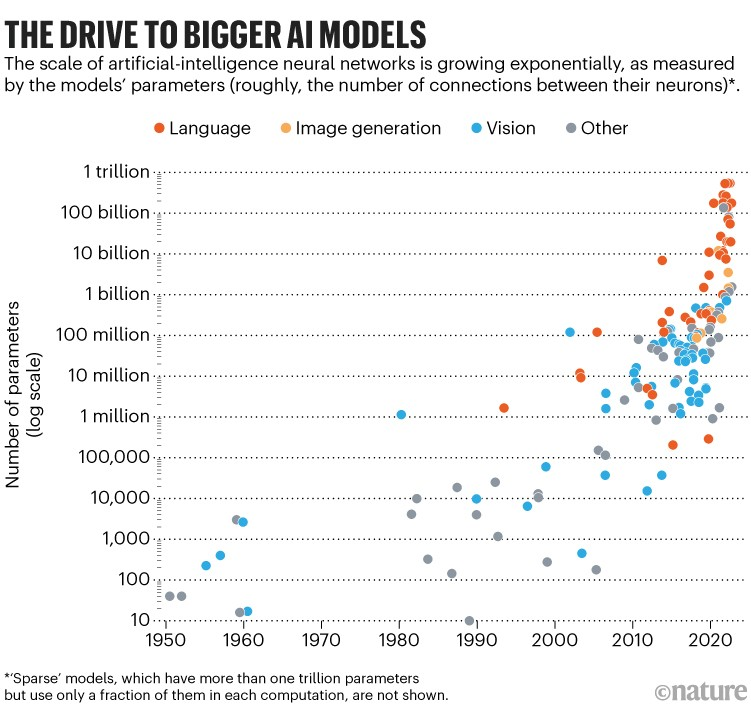
Kể từ khi Transformer ra đời với những ưu điểm kể trên của nó đã giúp cho kích thước của các mô hình ngày càng phình ra. Mô hình to có một ưu điểm rất hay mà các mô hình nhỏ không làm được đó chính là khả năng biểu diễn và hiểu ngữ cảnh tốt tới mức kinh ngạc. Điều này khiến cho ngay cả những người tạo ra nó cũng không thể biết và hiểu được chính xác nó làm gì. Để huấn luyện và vận hành ra những mô hình như thế này đòi hỏi không chỉ lượng dữ liệu khổng lồ mà còn là cả một dàn năng lực tính toán thuộc vào hàng khủng top đầu thế giới. OpenAI đã scale up hệ thống Kubernetes của họ lên đến 7500 nodes làm nền tảng cho các mô hình ngôn ngữ lớn của họ. Chính việc mô hình càng ngày càng to như thế này đã làm cho AI đang trở thành vũ khí mới của các BigTech. Cũng giống như ngày xưa Hoa Kì đã độc bá thế giới với bom nguyên tử thì ngày nay AI cũng đang dần vẽ lại bản đồ công nghệ, khi mà các BigTech sẽ là những người làm chủ cuộc chơi trong các mô hình lớn.
Vậy một câu hỏi đặt ra cho chính chúng ta - những người làm công nghệ đó là PHẢI LÀM GÌ BÂY GIỜ???. Cùng mình thảo luận kĩ hơn trong những phần sau nhé.
Những người làm bên Academic
Chấp nhận sự thật

Có thể thấy một sự chậm chân rõ rệt của các bên làm chuyên về học thuật trong trận chiến này. Như chúng ta đã biết rằng gần như các kiến trúc của LLM hiện nay đều có nguồn gốc từ mô hình Transformer mà cha đẻ của nó chính là Google. Nhưng thật cay đắng cho Google khi mà ú oà anh bạn OpenAI đã đi trước một bước trong việc tạo ra các mô hình ngôn ngữ lớn có thể áp dụng được trên thực tế trên chính nền tảng là các nghiên cứu do họ sáng tạo ra. Trong cuộc đua của AI ngày nay, chỉ cần bạn chậm chân một ngày thôi nhiều khi đã trở thành người tối cổ mất rồi.
Thực sự để có thể thực hiện được một nghiên cứu ra gì và này nọ trong thời điểm này là một điều vô cùng khó khăn bởi các điểm sau:
- RẤT DỄ BỊ SO SÁNH VỚI MÔ HÌNH LỚN: Dân tình đã quá choáng ngợp với các ứng dụng của các mô hình lớn. Bạn có tạo ra một cái gì đó mới mẻ nhưng cũng thật khó có thể vượt qua được các mô hình đã được huấn luyện với chi phí tính bằng cả triệu đô. Thậm chí có một câu joke trên Twitter với các nhà nghiên cứu rằng các ông đừng nghiên cứu gì nữa, hãy tập trung làm cho mô hình lớn hơn đi.
- KHÔNG PHẢI CỨ MUỐN LỚN LÀ ĐƯỢC: Nếu không tính các nhà nghiên cứu có chân trong các BigTech (con số này khá hiếm) thì gần như các người nghiên cứu AI ở trong các viên nghiên cứu, các trường đại học rất khó có cửa để huấn luyện ra được các mô hình lớn. Vấn đề lớn nhất thì ai cũng biết rồi TIỀN là yếu đố không thể thiếu trong cuộc đua này. Thế nên cũng không phải cứ muốn lớn là lớn được đâu
- DÙ CÓ TIỀN CŨNG CHẲNG CÓ NGƯỜI: Kể cả khi bạn lo xong câu chuyện về phần cứng thì cũng không chắc bạn có thể làm ra được các thứ gì đó lớn lao trong thời điểm này bởi lẽ các mô hình lớn để huấn luyện nó không phải chuyện dễ dàng. Mình sẽ có một bài viết riêng về vấn đề huấn luyện các mô hình ngôn ngữ lớn nhưng các bạn chỉ cần biết rằng chúng ta sẽ cần có rất nhiều các chuyên gia có hiểu biết không chỉ về học thuật mà còn về engineer để control được hệ thống đó. Vậy nên dù có tiền thì các lab cũng khó có lợi thế về con người bởi lẽ thường nhân sự trong các lab là không ổn định. Các sinh viên, học viên, nghiên cứu sinh nhiều khi chỉ làm việc trong một thời gian ngắn. Đó là chưa kể ông nào giỏi giỏi chút thì lại đầu quân cho các BigTech hết rồi.
Có lẽ rằng các bạn sẽ thấy hơi tiêu cực một chút nhưng chấp nhận sự thật rằng sẽ cực cực khó để có những nghiên cứu để đời cũng là một sự lựa chọn. Nó có vẻ phù hợp với những ai đang có một vị trí ổn định và cảm thấy hài lòng khi làm những điều nho nhỏ trong con đường học thuật của mình.
Đi những lối đi riêng

Nếu như chúng ta tập trung nghiên cứu vào các mảng như NLP hay Generative AI hiện nay thì có thể các task liên quan đến chúng đều được giải quyết rất tốt bởi các mô hình lớn. Và chắc chắn một điều rằng dù bạn có cố gắng như thế nào cũng khó lòng đạt được những thành tựu lớn lao trong lĩnh vực này. Ngay cả các BigTech như Google cũng đang đau đầu giải quyết vấn đề này cơ mà. Thế nhưng sẽ có những mảng riêng mà các BigTech chưa thể động tới hoặc là không đáng để họ phải động tới. Đó là những mảng có kiến thức và nghiệp vụ chuyên biệt như y tế, tài chính, bán lẻ, ngân hàng ... Giải quyết những nghiên cứu thuộc các lĩnh vực hẹp như vậy luôn có đất sống cho chúng ta hơn là đối chọi với các ông lớn ngoài kia.
Đứng trên vai người khổng lồ
Nếu như việc huấn luyện lại từ đầu các mô hình là quá khó về mặt kinh tế cũng như con người thì việc tận dụng lại các mô hình được public sẵn cho các hướng đi của mình là một hướng nghiên cứu không tồi. Gần đây các nghiên cứu về mô hình ngôn ngữ có thể đạt được khoảng 90% hiệu năng của ChatGPT nhưng với kích thước nhỏ hơn cũng là một chủ đề nghiên cứu rất hay. Nó giúp mang lại nhiều giá trị hơn cho cộng đồng nghiên cứu khi mà các mã nguồn và cách thức training được thử nghiệm và public.

Khắc phục những điểm yếu của mô hình lớn
Mô hình càng lớn thì vận hành các phức tạp và khó khăn, vậy nên khắc phục được các điểm yếu của các loại mô hình này như thời gian huấn luyện, thời gian training hoặc kích thước mô hình, hoặc các loại accelerator chuyên biệt là một hướng nghiên cứu rất tiềm năng. Ngày nay người ta quan tâm hơn đến các vấn đề môi sinh, môi trường khi huấn luyện các mô hình AI và các vấn đề triển khai các mô hình với phần cứng hạn chế. Đây là một hướng nghiên cứu rất tiềm năng và hứa hẹn nhiều đột phá trong tương lai cả về lý thuyết, phần cứng cũng như phần mềm.
Chuyển sang hướng nghiên cứu ứng dụng hoặc startup
Đối với mình thì mình luôn quan điểm rằng, AI hay bất cứ công nghệ nào khác thì mục đích cuối cùng của nó cũng phải phục vụ cho người dùng cuối, có thể là đại đa số người dùng hoặc một nhóm người dùng chuyên biệt nhưng chắc chắn nó phải có một ứng dụng nào đó. Tất nhiên không phải nghiên cứu nào cũng sẽ ra được ứng dụng ngay mà nó có thể làm tiền đề cho nhiều nghiên cứu khác. Tuy nhiên nếu như bạn là một nhà nghiên cứu có đầu óc nhạy bén một chút thì tại sao không thử biến các nghiên cứu của mình theo hướng ứng dụng và tạo ra các sản phẩm hơn nhỉ.

Những người làm bên Industry
Ứng dụng thật nhanh

Có thể thấy sau khi ChatGPT ra đời thì số lượng startup mọc lên như nấm sau mưa báo hiệu kỉ nguyên của việc ứng dụng AI đang tới rất gần. Nếu bạn làm bên industry thì chắn chắn bạn cũng không nên bỏ lỡ cơ hội này. Tìm hiểu về nó, cách thức của nó hoạt động như thế nào cũng như tìm hiểu về các công cụ, framework giúp cho chúng ta tận dụng tốt các mô hình lớn sẽ là một trong những nền tảng tốt cho việc phát triển ứng dụng. Bản thân mình cũng không thể ngờ rằng các phí sử dụng cho các mô hình ngôn ngữ lớn như ChatGPT lại rẻ như bùn vậy. Không hiểu rõ họ sẽ lấy lợi nhuận từ đâu khi bán sản phẩm với những mức giá như thế tuy nhiên nó sẽ dẫn đến một tương lai mới cho ngành phần mềm, khi mà việc tích hợp các yếu tố AI là không còn khó khăn như trước nữa.
Tập trung vào specific domain hoặc private data

Có rất nhiều công ty hoặc các nghiệp vụ không thể áp dụng trực tiếp các mô hình ngôn ngữ lớn trong logic sản phẩm của họ bởi các lý do về bảo mật nên một hướng đi mới mà chúng ta nên tìm hiểu đó là cách thức sử dụng các mô hình ngôn ngữ lớn cho các dữ liệu private. Ngoài ra đối với các domain hẹp, đòi hỏi phải các các domain knowledge chuyên biệt thì cũng rất cần có những phương pháp ứng dụng các mô hình lớn vào trong các dự án như thế.
Ngay cả khi chúng ta không áp dụng các mô hình lớn thì các specific domain vẫn luôn là một miếng bánh mà các ông lớn rất khó có đủ tay để giải quyết, thế nên trang bị các kiến thức trong các lĩnh vực này chưa bao giờ là thừa.
Bổ sung kiến trúc về hệ thống cho AI
Như các bạn thấy đó, để huấn luyện ra các mô hình lớn như vậy thì ngoài nguồn lực về phần cứng ra thì còn đòi hỏi năng lực về con người. Họ không chỉ hiểu về cách thức các mô hình hoạt động mà còn hiểu rất rõ về các kĩ năng engineer khi huấn luyện các mô hình này. Việc triển khai các hệ thống với mô hình. ngôn ngữ lớn là một trong những vấn đề đòi hỏi rất nhiều kĩ năng engineer và infrastructure, đặc biệt là các kiến thức chuyên biệt cho các nền tảng cloud provider riêng. Tương lai không xa, việc custom và huấn luyện các mô hình AI trên các hệ thống phức tạp là điều rất khó tránh khỏi. Điều này đòi hỏi mỗi sự chuẩn bị kĩ lưỡng. Không thể đợi nước đến chân mới nhảy được đúng không các bạn.

Kết luận
Tương lai của AI chắc chắn sẽ có nhiều thay đổi lên các hoạt động của chúng ta, đi kèm với những khó khăn là hàng loạt các cơ hội mới đến với chúng ta. Là một người làm về AI, bạn hãy chuẩn bị cho mình những hướng đi tốt nhất làm hành trang trên con đường đầy chông gai những cũng hết sức thú vị phía trước nhé. Bài viết cũng khá dài rồi. hẹn gặp lại các bạn trong những bài viết tiếp theo.
All rights reserved
