
Các kỹ thuật tuning mô hình Large Language Model (LLM)
Bài đăng này đã không được cập nhật trong 2 năm
Sự nổi dậy của chat GPT và các mô hình ngôn ngữ lớn (Large Languae Model - LLM) đã thu hút được sự quan tâm lớn của công chúng. Chỉ trong 5 năm, các mô hình ngôn ngữ lớn - Transformer đã biến đổi gần như hoàn toàn lĩnh vực xử lý ngôn ngữ tự nhiên. Ngoài ra, chúng đang bắt đầu lấn sân các lĩnh vực như thị giác máy tính và sinh học tính toán. Mình cũng mới bắt đầu tìm hiểu LLM, nên mình sẽ cố gắng note lại những gì mình tìm hiểu được, nếu có gì sai sót mong mọi người comment để mình biết.
1. Large Language Models (LLMs)
Sự phát triển của Large language Model có thể được chia làm 4 bước ngoặt chính: Statistical languauge model (SLM): sử dụng phương pháp học thống kê (statistical learning) để xây dựng mô hình ngôn ngữ. Ví dụ điển hình là dử dụng Hidden Markov Model (HMM) trong các lĩnh vực như statistical machine translation (SMT) và Automatic Speech Recognition (ASR).
Neural network languauge model (NLM): Mô hình ngôn ngữ được xây dựng dựa trên mạng nơ-ron, như là RNN, LSTM, GRU,...
Pre-training language model (PLM):: Hầu hết chúng đều dựa trên kiến trúc transformer. Những mô hình này được pre-trained trên những tập corpus lớn, sau đó sẽ được fine-tune trên những downstream tasks. Ví dụ: BERT, BART, T5...
Large language model (LLM): Dựa trên nền tảng của PLM, số lượng tham số mô hình tăng lên, nó đã cho thấy những khả năng đáng kinh ngạc trong việc xử lý những task phức tạp mà PLM không làm được. Những mô hình kiểu này thường sử dụng cả kỹ thuật pretrained lẫn fintuning.
2. Fine-Tuning LLMs
Như chúng ta đã biết thì việc Fine-tuning mô hình là việc adapt mô hình có nhiều tác vụ về mô hình có một số tác vụ nhất định một cách chính xác và hiệu quả (ví dụ: fine-tuning model BERT cho bài toán phân loại văn bản..). Khi gặp một số task NLP cụ thể như: sentiment analysis hay question-answering cho một lĩnh vực nào đó thì chúng ta cũng cần fine-tune pretrained model cho một số task và domain cụ thể.
Việc fine-tuning có nhiều lợi ích. Đầu tiên, nó tận dụng được những kiến thức mà mô hình pre-training đã được học rồi, điều này sẽ tiết kiệm được rất nhiều thời gian cũng như là tài nguyên tính toán so với việc training frome scratch. Thứ hai, việc fine-tuning cho phép mô hình hoạt động tốt hơn trên một số task cụ thể.
2.1 Instruction Finetuning LLMs
Instruction Finetuning là gì?
Instruction fine-tuning là một kỹ thuật để adapt LLMs thực hiện một số task cụ thể dựa trên những lời dẫn cụ thể (explicit instruction ). Trong khi các cách fine-tuning thông thường thì chỉ huấn luyện dựa trên một tập dataset cụ thể cho task nào đó thì instruction fine-tuning thực hiện sâu hơn bằng cách sử dụng high-level instruction để hướng dẫn cho model thực hiện một số task cụ thể.

Sự khác biệt giữa fine-tuning thông thường và instruction fine-tuning
Yêu cầu về dữ liệu: fine-tuning thông thường dựa trên một lượng đáng kể dữ liệu có nhãn cho một task cụ thể nào đó, trong khi instruction fine-tuning dựa trên lời dẫn cụ thể(explicit instruction) để hướng dẫn mô hình adapt hơn với một lượng dữ liệu có hạn.
Khả năng điều khiển và độ chính xác: Instruction fine-tuning cho phép chỉ định outputs mong muốn, tập chung hơn vào behavior nào đó và quản lý tốt hơn đầu ra của mô hình trong khi fine-tuning thông thường ta khó có thể đạt được mức độ quản lý đầu ra như vậy.
Học từ lời dẫn: Instruction fine-tuning yêu cầu có lời dẫn trong khí fine-tuning thông thường thì không cần.
Catastrophic forgetting
Catastrophic forgetting xảy ra khi mô hình quên đi mất những thông tin đã được học trước đó để học những thông tin mới, hiện tượng này thường xảy ra khi fine-tuning mô hình ngôn ngữ cho bài toán single-task. Fine-tuning có thể cải thiện một cách đáng kể performance của một task cụ thể nào đó nhưng lại làm giảm đi hiệu năng của nó ở những task khác.
Catastrophic forgetting là một hiện tượng thường gặp trong machine learning và deep learning.
Ví dụ: Bài toán đánh giá sắc thái của một câu bình luận. Ta fine-tune mô hình ngôn ngữ để đưa ra kết quả là sắc thái của bình luận thay vì đưa ra một câu. Mặc dù hoạt động tốt với task đánh giá sắc thái bình luận tuy nhiên nó lại không có khả năng trả lời một câu hỏi đơn giản (ví dụ ở hình 2).
| Before fine-tuning | After fine-tuning |
|---|---|
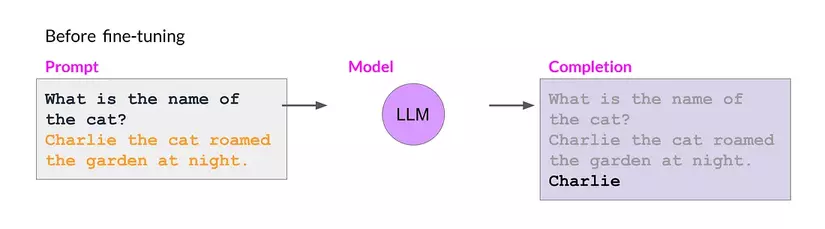 |
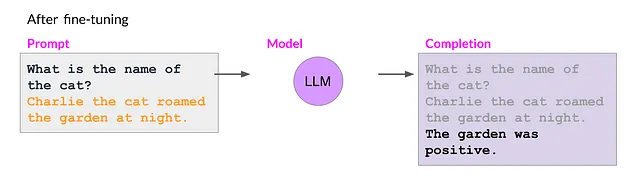 |
- Fine-tune mô hình ngôn ngữ cho multi-task thay vì single-task.
- Parameter Efficient Fine-tuning (PEFT). Mình sẽ trình bày cụ thể hơn ở phần 2.2.
2.2 Parameter Efficient Finetuning (PEFT)
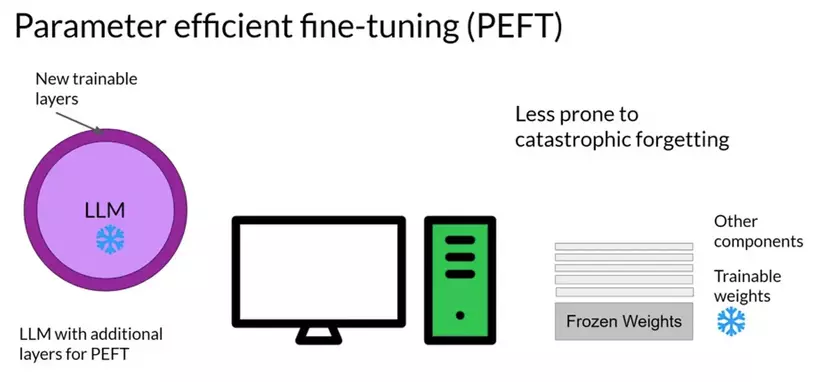
Những phương pháp fine-tune truyền thống trước PEFT
Để hiểu ý nghĩa của việc sử dụng PEFT, đầu tiên chúng ta cần hiểu kỹ những phương pháp fine-tuning truyền thống trước đó. Fine-tuning là việc thay đổi hệ số của một pre-trained mô hình. Ví dụ như fine-tune BERT - một mô hình đã được train với tập dữ liệu rất lớn cho một tập dữ liệu cụ thể nào đó bằng một tập dataset cụ thể. Điều này giúp cho việc mô hình có những knowledge rộng, giúp cho việc học dễ dàng trên nhiều lĩnh vực khác nhau. Ví dụ, fine-tune một mô hình với văn bản pháp luật có thể cho phép nó giải thích luật một cách chi tiết hay có thể đưa ra một kết luận pháp lý dựa trên nhưng bản án trước đó.
Những vấn đề mà PEFT giải quyết
Catastrophic Forgetting: Catastrophic forgetting là một vấn đề lớn trong fine-tuning. Nó là hiện tượng mô hình được fine-tune dễ bị quên đi những kiến thước đã được học trước đó để học kiến thức mới. Điều này sẽ làm giảm đi tính linh hoạt của mô hình trên nhiều tác vụ khác nhau. PEFT giải quyết bằng cách giữ lại có chọn lựa một phần của mô hình, và đảm bảo rằng những kiến thức nền tảng sẽ không bị mất đi khi học kiến thức mới.
Computational Efficiency: Fine-tune một mô hình có kích thước lớn như LLMs thì tốn khá nhiều tài nguyên tính toán. PEFT giải quyết bằng cách tối ưu một phần tham số mô hình, điều này giúp cho những nhóm nghiên cứu nhỏ hoặc doanh nghiệp không có nhiều tài nguyên tính toán cũng có thể tiếp cận với những mô hình kích thước lớn.
Overfitting: Overfitting là hiện tượng một mô hình quá fit vào một tập dữ liệu huấn luyện, đặc biệt xảy ra khi fine-tune mô hình trên một lượng dữ liệu nhỏ. Tuy nhiên chiến lược selective paramter tuning sẽ làm giảm hiện tượng này.
Scalability: Khi mô hình trở nên lớn hơn và phức tạp hơn, những phương pháp fine-tune truyền thống sẽ càng trở nên nặng nề hơn. PEFT giúp chúng ta có thể scale mô hình một cách dễ dàng mà không cần tăng chi phí tính toán quá nhiều.
Kết luận
Như vậy trong bài viết này mình đã giới thiệu một cách tổng quát LLMs là gì cũng như là 2 cách fine-tuning mô hình LLMs phổ biến hiện nay là instruction fine-tuning và Parameter-Efficient Fine-Tuning (PEFT). Mình cũng đã đề cập tới những vấn đề mà PEFT đã giải quyết được: catastrophic forgetting, computational efficiency, overfitting và scalability. Do bài viết khá dài rồi nên mình cũng không đề cập tới những phương pháp fine-tuning khác nữa nếu có điều kiện mình sẽ giới thiệu những phương pháp fine tuning LLMs phức tạp hơn như Alignment Tuning và cả Reinforcement Learning from Human Feedback (RLHF) nữa.
Tham Khảo
A Survey of Large Language Models: arxiv
PEFT: https://huggingface.co/docs/peft/index
Understanding Large Language Models: zhihu blog
Introducing Parameter-Efficient Fine-Tuning (PEFT) : medium blog
All rights reserved
