
Bài toán phát hiện chữ (Text Detection) và mô hình DB (Phần 2)
Bài đăng này đã không được cập nhật trong 3 năm
I. Giới thiệu
Ở trong phần 1 của bài viết Bài toán phát hiện chữ (Text Detection) và mô hình DB (Phần 1) , tôi đã giới thiệu tổng quan các mô hình phát hiện chữ và mô hình phát hiện chữ DB. Trong bài viết hôm nay, tôi sẽ giới thiệu cho các bạn một phiên bản cải tiến của mô hình DB là DB++ được giới thiệu trong bài báo Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion.
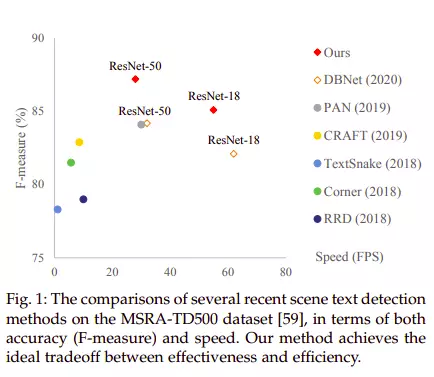
Nhắc lại một chút, bài toán phát hiện chữ nhằm mục đích phát hiện vị trí các đối tượng là chữ trong ảnh đầu vào. Mặc dù bài toán này đã được nghiên cứu rất nhiều trong thời gian vừa qua nhưng vẫn gặp rất nhiều thử thách vì các chữ có kích thước khác nhau, có cả các chữ cong, chữ nghiêng, ....
Như đã đề cập trong bài viết lần trước, các mô hình phát hiện chữ hiệu quả nhất hiện nay là thuộc về các mô hình dựa trên phương pháp phân đoạn (segmentation based method) do các mô hình thuộc phương pháp này có thể dễ dàng xử lý đối với các chữ có sự biến dạng như chữ cong, chữ nghiêng,... Tuy nhiên các phương pháp này gặp vấn đề khi hầu hết các thuật toán hậu xử lý của các phương pháp này nhằm mục đích nhóm các pixel của đối tượng chữ vào với nhau có độ phức tạp lớn và tính toán mất nhiều thời gian. Thuật toán hậu xử lý của các phương pháp này như sau:
- Dùng một bộ trích xuất đặc trưng gọi là segmentation network sinh ra bản đồ xác suất thể hiện xác suất từng pixel đó là chữ là bao nhiêu ? Dùng một ngưỡng cố định để loại bỏ các pixel có xác suất thấp.
- Nhóm các pixel thuộc cùng một đối tượng text vào với nhau bằng các thuật toán như clustering
Và mô hình DB là một bước tiến lớn khi đã đơn giản hóa được quá trình này và đạt tốc độ đáng kể so với các phương pháp trước đó như CRAFT, Corner, TextSnake bằng cách thay vì dùng một ngưỡng cố định thì sinh ra một bản đồ ngưỡng động cho từng pixel ở bản đồ xác suất được tối ưu cùng trong quá trình huấn luyện. Vì vậy giúp mô hình đạt độ chính xác cao hơn so với nhiều phương pháp trước đó.
Để tiếp tục cải thiện chất lượng của mô hình DB, nhóm tác giả tiếp tục ra một kiến trúc mới sử dụng module Adaptive Scale Fusion (ASF) giúp mô hình có thể tổng hợp đặc trưng ở nhiều scale khác nhau. Bây giờ chúng ta cùng đi vào chi tiết mô hình này nhé.
II. Tư tưởng thiết kế mô hình.
Bài báo đề cập đến 3 ưu điểm giúp mô hình DB vượt trội so với các kiến trúc khác như sau:
- Sử dụng mô đun DB được đề xuất trong bài báo trước giúp linh hoạt và tối ưu cùng lúc với mô hình.
- Mô đun DB được lọai bỏ trong quá trình suy luận do đó không phát sinh thêm thời gian xử lý.
- Khả năng biểu diễn mạnh mẽ nhờ khả năng tổng hợp đặc trưng ở nhiều mức scale dưới sự hỗ trợ của mô đun ASF.
2.1. Tổng quan.
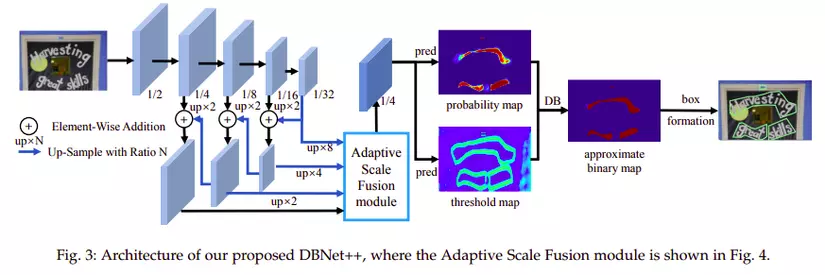
Kiến trúc mô hình DB++ được mô tả trên ảnh 4. Ảnh đầu vào đầu tiên được cho qua một mô đun trích xuất đặc trưng phân cấp. Sau đó các bản đồ đặc trưng được up-sample về kích thước các bản đồ đặc trưng của lớp ngay trước đó rồi thực hiện tổng hợp đặc trưng của hai lớp này cùng với nhau và đưa qua mô đun Adaptive Scale Fusion (ASF) để tăng cường, sinh ra bản đồ đặc trưng . Bản đồ đặc trưng sau đó dùng để sinh ra bản đồ xác suất trên từng pixel và bản đồ ngưỡng . Cuối cùng bản đồ nhị phân sinh ra được tính toán dựa trên và .
2.2. Chi tiết thiết kế.
2.2.1 Spatial Attention
 Spatial Attention
Spatial Attention
Tư tưởng thiết kế Spatial Attention khá tương tự với thiết kế kiến trúc Squeeze and excitation mà tôi đã trình bày ở bài viết Những mô hình trợ thủ đắc lực trong các mô hình Deep learning [Phần 1] . Kiến trúc bao gồm hai nhánh. Nhánh đầu tiên gồm các lớp Spatial Average Pooling, Conv-Relu, Conv-Sigmoid. Lớp đầu tiên là Spatial Average Pooling giúp tổng hợp giá trị trung bình đặc trưng trên từng vị trí ở nhiều scale khác nhau. Lớp này khiến cho mô đun Spatial Attention không những học được tính quan trọng của các giá trị ở vị trí khác nhau mà còn trên nhiều scale khác nhau. Sau đó output đi qua lớp Conv-Relu, Conv-Sigmoid. Nhánh này thực hiện nhiệm vụ giúp tăng cường đặc trưng cho biểu diễn input đầu vào bằng cách cộng kết quả vào bản đồ đặc trưng ban đầu. Kết quả sau khi được cộng vào tiếp tục được cho qua lớp tích chập kết hợp với hàm kích hoạt sigmoid. Cá nhân tôi nghĩ việc dùng sigmoid ở đây khiến cho chức năng của spatial attention khác so với các cơ chế attetion thông thường dùng hàm softmax có ý nghĩa tăng cường đặc trưng hơn do không bắt buộc triệu tiêu giá trị nào ( vì tổng các phần tử sigmoid có thể không bằng 1 nhưng ở hàm softmax thì bắt buộc)
2.2.2. Adaptive Scale Fusion
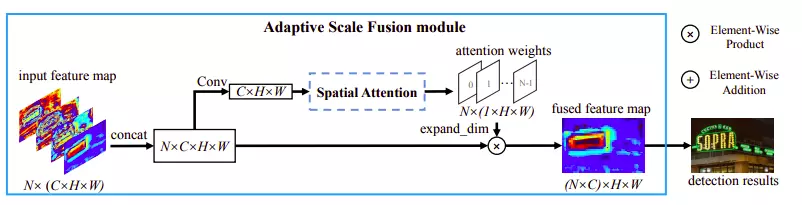 Adaptive Scale Fusion
Adaptive Scale Fusion
Thiết kế kiến trúc Adaptive Scale Fusion dựa trên một lý thuyết về mối liên hệ giữa hai khái niệm là context và scale. Context giúp mô hình tiếp nhận được vùng có kích thước lớn hơn trong khi ở mỗi scale giúp mô hình có những biểu diễn đa dạng khác nhau ở các vùng tiếp nhận khác nhau và kích thước khác nhau nên đa dạng hơn. Tổng hợp đặc trưng ở nhiều scale giúp tăng cường khả năng biểu diễn của mô hình. Thực ra ý tưởng này không hế mới đã được đề cập ở bài báo Multi-Scale Feature Fusion FCN hay ở trong kiến trúc U-Net khi dựa trên một quan sát rằng:
- Các lớp đầu tiên trong mô đun trích xuất đặc trưng thường biễu diễn được các chi tiết nhỏ trong vùng tiếp nhận tuy nhiên vùng tiếp nhận thường không lớn nên không quan sát được các chi tiết tổng quan hơn
- Các lớp sâu thì có xu hướng học được thông tin global context do vùng tiếp nhận (receptive field) lớn hơn. Tuy nhiên lại bỏ qua các chi tiết nhỏ.
Nhưng ở kiến trúc DB++ được đề xuất trong bài báo này có điểm đặc biệt. Thay vì cộng tổng tất cả các bản đồ đặc trưng ở các scale vào với nhau. thì DB++ thực hiện ghép nối và cho đi qua mô đun ASF kết hợp với cơ chế attention để có thể tổng hợp một cách linh hoạt đặc trưng ở nhiều scale khác nhau
Theo như kiến trúc đề xuất trong bài báo, chúng ta có tổng cộng 4 bản đồ đặc trưng ở các scale tương ứng là . Bốn bản đồ đặc trưng này được upscale về cùng kích thước và ghép nối vào với nhau gọi là trong đó . Bản đồ đặc trưng thu được cho qua lớp tích chập đưa về kích thước để thực hiện tính Spatial Attention ra trọng số chú ý có kích thước . Kết quả này sau đó nhân với bản đồ đặc trưng ban đầu để ra kết quả cuối cùng.
2.2.3. Adaptive threshold
Mô đun này kế thừa ý tưởng từ kiến trúc DB mà tôi để trình bày trong bài viết trước khi thay thế mô đun Standard Binarization bằng mô đun Differentiable Binarization có thể cùng tối ưu trong quá trình huấn luyện. Các bạn có thể xem bài viết Bài toán phát hiện chữ (Text Detection) và mô hình DB (Phần 1) để biết thêm chi tiết.
III. Tổng kết
Nhờ vào việc thêm hai mô đun là Spatial Attention và Adaptive Scale Fusion để giúp mô hình DB++ tăng cường sức mạng của segmentation network và cho ra các kết quả tốt hơn, hạn chế được việc bỏ qua các đối tượng nhỏ. Cảm ơn các bạn đã theo dõi bài viết của mình. Xin hẹn gặp lại các bạn trong các bài tiếp theo.
Tài liệu tham khảo.
All rights reserved
