
[B5'] 3D Photography using Context-aware Layered Depth Inpainting - Tạo ảnh 3D từ ảnh tĩnh
Bài đăng này đã không được cập nhật trong 5 năm
1. Introduce
Chắc hẳn các bạn đã nghe đến hoặc sử dụng công nghệ ảnh "3D" của Facebook. Với 1 bức ảnh 2D thông thường, Facebook 3D Photos có thể tạo ra 1 bức ảnh chuyển động nhỏ, tạo cảm giác như ảnh đang chuyển động hoặc video ngắn. Công nghệ của Facebook 3D Photos tạo sự đột phá nhờ vào khả năng tạo lớp của Layered Depth Image (LDI). Màu sắc (RGB) và chiều sâu (D) của 1 bức ảnh. Tuy nhiên phương pháp này hiện nay vẫn tồn tại 1 điểm yếu lớn. Layers được tạo ra tương đối cứng nhắc, khiến cho background của bức ảnh không thực sự tốt. Và paper 3D Photography using Context-aware Layered Depth Inpainting được đưa ra 1 số phương pháp khá thú vị để giải quyết

2. Một số khái niệm
Trước khi đi sâu vào paper, mình sẽ bàn về một số thuật ngữ được tác giả sử dụng
2.1. Ảnh RGB-D
Một bức ảnh thông thường sẽ có 3 kênh màu Red, Green và Blue với các giá trị trong khoảng (0,255).
Ảnh RGB-D là ảnh RGB kết hợp với độ sâu trường ảnh (depth map), thường được ứng dụng trong lĩnh vực đồ họa. Depth map của ảnh có thể đo được nhờ cảm biến độ sâu (IR Depth Sensor), chính vì vậy ảnh RGB-D có thể thu được bởi các thiết bị chuyên dụng ZCam như Kinect, Orbbec, VicoVR ...

2.2. Layered Depth image
Phương pháp được sử dụng là Layered depth image (LDI) được nghiên cứu bởi Jonathan Shade et al. Các bạn có thể tìm thấy paper gốc tại đây. Paper được xuất bản năm 1998 và là nền tảng cho rất nhiều ứng dụng đồ họa sau này. LDI được phát triển khi Sprites Depth lúc đó không đáp ứng được với các ảnh có nhiều vùng khuất hay có nhiều điểm thị sai (parrallax).
Với LDI, mỗi điểm ảnh của depth map sẽ chứa đa điểm, chính vì vậy ngay cả khi Field of View di chuyển, vẫn có thể nhìn thấy các layer bị che khuất tại vị trí ban đầu. Một điểm cộng nữa là LDI không sử dụng bộ nhớ đệm z-buffer, giúp cho việc render ra ảnh nhanh và hiệu quả hơn.
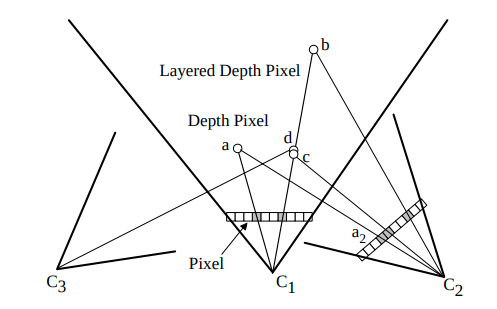
Phương pháp này cũng đã được Facebook 3D Photos ứng dụng trong quá trình tạo ra video từ ảnh 2D Hay hiểu 1 cách đơn giản, có thể render các bức ảnh với nhiều độ depth khác nhau trong đồ họa
Ví dụ về Sprites Depth tách depth map thành layer

a) Trích xuất sprite
b) Segmentation các vùng (6 vùng)
c) Ghép các vùng segment dựa trên độ sâu của ảnh

d) Ảnh hiển thị theo các lớp
e) Lớp cuối cùng còn lại

f) Tái tạo lại background
g) Novel view không có lớp residual
h) Novel view với lớp residual
2.3. Input và pre-process
Như đã nói ở trên, ảnh đầu vào của mạng sẽ là ảnh dạng RGB-D. Tuy nhiên không phải lúc nào bạn cũng sẵn có 1 em Kinect để thu được bức ảnh như mong muốn  , chính vì vậy trong Paper tác giả có đưa ra 1 giải pháp là tạo độ sâu trường ảnh bức ảnh với MegaDepth, MiDas ...
, chính vì vậy trong Paper tác giả có đưa ra 1 giải pháp là tạo độ sâu trường ảnh bức ảnh với MegaDepth, MiDas ...

Về cơ bản Megadepth là 1 pretrained model được sử dụng với mục đích dự đoán depth map của một bức ảnh. Các bạn có thể thử demo tại đường link dưới đây để hình dung rõ hơn
http://megadepthdemo.pythonanywhere.com/


Còn đây là kết quả ảnh một chiếc xe hơi được generate depth map sử dụng MiDas
3. Pipeline
Pipeline của phương pháp này đã được tác giả minh họa khá dễ hiểu và cụ thể. Với ảnh input dạng RGB-D sau khi được sau khi được áp dụng LDI để tách thành các layer, chúng ta sẽ thu được ảnh với các filter-depth khác nhau. Mỗi LDI pixel, ngoài các điểm ảnh còn có trường giá trị depth.
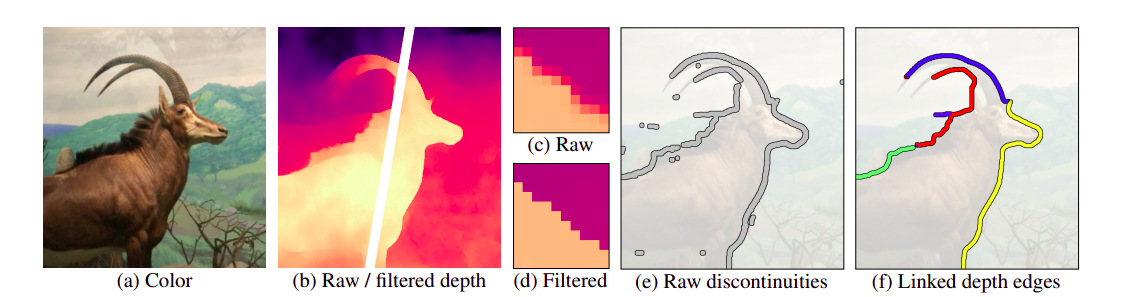
Các bước tiền xử lý ảnh:
- Normalize ảnh
- Sử dụng LDI với ảnh depth map đã predict ở trên
- Làm sắc nét các đường viền với bilateral median filter
- Vẽ viền gốc
- Phân đường viền tương ứng với depth map

- Tạo layered depth image
- Cắt/ tách rời các layer tương ứng (nền / chủ thể)
- Tạo nền với vùng context và vùng synthesis
- Tái tạo ảnh
Có một vấn đề không nhỏ, đó là depth map đôi khi không khớp 100% với vùng ảnh và màu ảnh. Chính vì vậy, tác giả đã đề xuất sử dụng riêng 3 model để giải quyết 3 vấn đề riêng: khôi phục viền, khôi phục màu và khôi phục độ sâu bị che khuất.
Bước tái tạo ảnh nền được chia thành 3 giai đoạn:
- Tái tạo đường viền
- Tái tạo màu sắc
- Tái tạo chiều sâu
Phần Edge được tái tạo sẽ được concatenate với vùng context để thành input cho các model sau
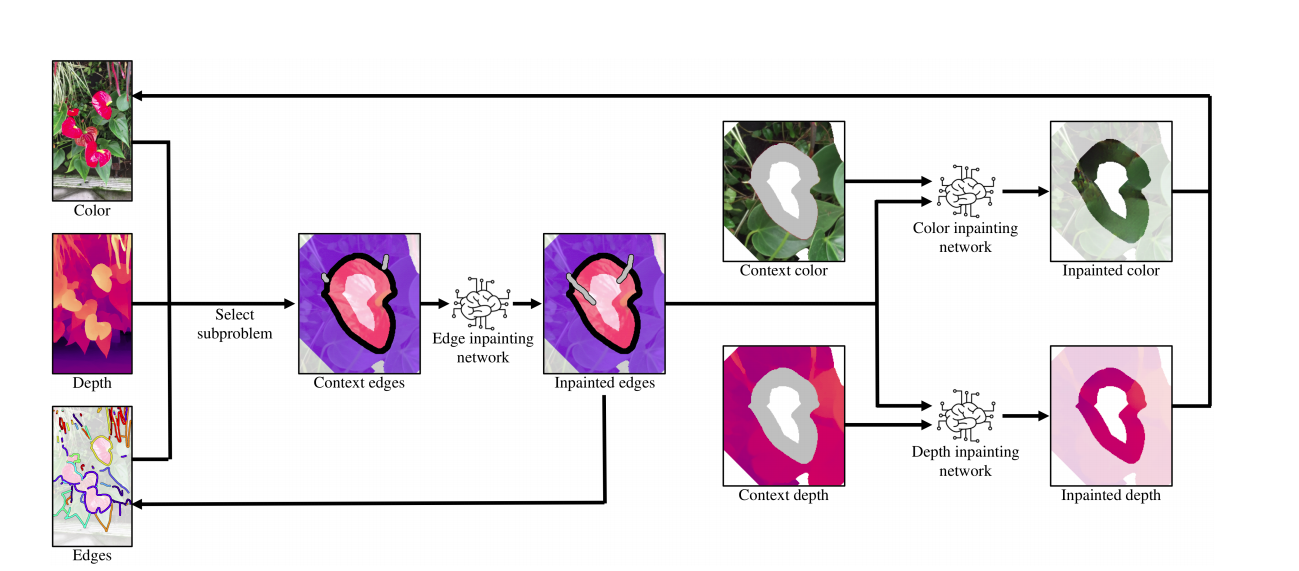
Với 3 yếu tố đường viền, màu sắc và độ sâu trường ảnh. Ứng với mỗi giai đoạn sẽ có các model tương ứng. Kiến trúc mạng:
#Khoi phuc Vien
class Inpaint_Edge_Net(BaseNetwork):
def __init__(self, residual_blocks=8, init_weights=True):
super(Inpaint_Edge_Net, self).__init__()
in_channels = 7
out_channels = 1
self.encoder = []
# 0
self.encoder_0 = nn.Sequential(
nn.ReflectionPad2d(3),
spectral_norm(nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=7, padding=0), True),
nn.InstanceNorm2d(64, track_running_stats=False),
nn.ReLU(True))
# 1
self.encoder_1 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=2, padding=1), True),
nn.InstanceNorm2d(128, track_running_stats=False),
nn.ReLU(True))
# 2
self.encoder_2 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=4, stride=2, padding=1), True),
nn.InstanceNorm2d(256, track_running_stats=False),
nn.ReLU(True))
# 3
blocks = []
for _ in range(residual_blocks):
block = ResnetBlock(256, 2)
blocks.append(block)
self.middle = nn.Sequential(*blocks)
# + 3
self.decoder_0 = nn.Sequential(
spectral_norm(nn.ConvTranspose2d(in_channels=256+256, out_channels=128, kernel_size=4, stride=2, padding=1), True),
nn.InstanceNorm2d(128, track_running_stats=False),
nn.ReLU(True))
# + 2
self.decoder_1 = nn.Sequential(
spectral_norm(nn.ConvTranspose2d(in_channels=128+128, out_channels=64, kernel_size=4, stride=2, padding=1), True),
nn.InstanceNorm2d(64, track_running_stats=False),
nn.ReLU(True))
# + 1
self.decoder_2 = nn.Sequential(
nn.ReflectionPad2d(3),
nn.Conv2d(in_channels=64+64, out_channels=out_channels, kernel_size=7, padding=0),
)
Với tái tạo độ sâu và màu sắc của ảnh sử dụng kiến trúc U-net kiểu Partial Convolution. Partial Convolution là kiến trúc mạng được sử dụng trong việc tái tạo/ khôi phục lại vùng hình đã bị xóa. Mình sẽ nói kỹ hơn trong một bài khác sau này.
Các bạn có thể tham khảo paper + code tại đây.
class PartialConv(nn.Module):
#Partial Convolution
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True):
super().__init__()
self.input_conv = nn.Conv2d(in_channels, out_channels, kernel_size,
stride, padding, dilation, groups, bias)
self.mask_conv = nn.Conv2d(in_channels, out_channels, kernel_size,
stride, padding, dilation, groups, False)
self.input_conv.apply(weights_init('gaussian'))
self.slide_winsize = in_channels * kernel_size * kernel_size
torch.nn.init.constant_(self.mask_conv.weight, 1.0)
for param in self.mask_conv.parameters():
param.requires_grad = False
def forward(self, input, mask):
# http://masc.cs.gmu.edu/wiki/partialconv
# C(X) = W^T * X + b, C(0) = b, D(M) = 1 * M + 0 = sum(M)
# W^T* (M .* X) / sum(M) + b = [C(M .* X) – C(0)] / D(M) + C(0)
output = self.input_conv(input * mask)
if self.input_conv.bias is not None:
output_bias = self.input_conv.bias.view(1, -1, 1, 1).expand_as(
output)
else:
output_bias = torch.zeros_like(output)
with torch.no_grad():
output_mask = self.mask_conv(mask)
no_update_holes = output_mask == 0
mask_sum = output_mask.masked_fill_(no_update_holes, 1.0)
output_pre = ((output - output_bias) * self.slide_winsize) / mask_sum + output_bias
output = output_pre.masked_fill_(no_update_holes, 0.0)
new_mask = torch.ones_like(output)
new_mask = new_mask.masked_fill_(no_update_holes, 0.0)
return output, new_mask
class PCBActiv(nn.Module):
def __init__(self, in_ch, out_ch, bn=True, sample='none-3', activ='relu',
conv_bias=False):
super().__init__()
if sample == 'down-5':
self.conv = PartialConv(in_ch, out_ch, 5, 2, 2, bias=conv_bias)
elif sample == 'down-7':
self.conv = PartialConv(in_ch, out_ch, 7, 2, 3, bias=conv_bias)
elif sample == 'down-3':
self.conv = PartialConv(in_ch, out_ch, 3, 2, 1, bias=conv_bias)
else:
self.conv = PartialConv(in_ch, out_ch, 3, 1, 1, bias=conv_bias)
if bn:
self.bn = nn.BatchNorm2d(out_ch)
if activ == 'relu':
self.activation = nn.ReLU()
elif activ == 'leaky':
self.activation = nn.LeakyReLU(negative_slope=0.2)
def forward(self, input, input_mask):
h, h_mask = self.conv(input, input_mask)
if hasattr(self, 'bn'):
h = self.bn(h)
if hasattr(self, 'activation'):
h = self.activation(h)
return h, h_mask
#Khoi phuc do sau
class Inpaint_Depth_Net(nn.Module):
def __init__(self, layer_size=7, upsampling_mode='nearest'):
super().__init__()
in_channels = 4
out_channels = 1
self.freeze_enc_bn = False
self.upsampling_mode = upsampling_mode
self.layer_size = layer_size
self.enc_1 = PCBActiv(in_channels, 64, bn=False, sample='down-7', conv_bias=True)
self.enc_2 = PCBActiv(64, 128, sample='down-5', conv_bias=True)
self.enc_3 = PCBActiv(128, 256, sample='down-5')
self.enc_4 = PCBActiv(256, 512, sample='down-3')
for i in range(4, self.layer_size):
#encoder
name = 'enc_{:d}'.format(i + 1)
setattr(self, name, PCBActiv(512, 512, sample='down-3'))
for i in range(4, self.layer_size):
name = 'dec_{:d}'.format(i + 1)
setattr(self, name, PCBActiv(512 + 512, 512, activ='leaky'))
#decoder
self.dec_4 = PCBActiv(512 + 256, 256, activ='leaky')
self.dec_3 = PCBActiv(256 + 128, 128, activ='leaky')
self.dec_2 = PCBActiv(128 + 64, 64, activ='leaky')
self.dec_1 = PCBActiv(64 + in_channels, out_channels,
bn=False, activ=None, conv_bias=True)
#khoi phuc mau
class Inpaint_Color_Net(nn.Module):
def __init__(self, layer_size=7, upsampling_mode='nearest', add_hole_mask=False, add_two_layer=False, add_border=False):
super().__init__()
self.freeze_enc_bn = False
self.upsampling_mode = upsampling_mode
self.layer_size = layer_size
in_channels = 6
self.enc_1 = PCBActiv(in_channels, 64, bn=False, sample='down-7')
self.enc_2 = PCBActiv(64, 128, sample='down-5')
self.enc_3 = PCBActiv(128, 256, sample='down-5')
self.enc_4 = PCBActiv(256, 512, sample='down-3')
self.enc_5 = PCBActiv(512, 512, sample='down-3')
self.enc_6 = PCBActiv(512, 512, sample='down-3')
self.enc_7 = PCBActiv(512, 512, sample='down-3')
self.dec_7 = PCBActiv(512+512, 512, activ='leaky')
self.dec_6 = PCBActiv(512+512, 512, activ='leaky')
self.dec_5A = PCBActiv(512 + 512, 512, activ='leaky')
self.dec_4A = PCBActiv(512 + 256, 256, activ='leaky')
self.dec_3A = PCBActiv(256 + 128, 128, activ='leaky')
self.dec_2A = PCBActiv(128 + 64, 64, activ='leaky')
self.dec_1A = PCBActiv(64 + in_channels, 3, bn=False, activ=None, conv_bias=True)

Để tăng tính hiệu quả, tác giả đã sử dụng inpainting nhiều lần để dạt được bức ảnh hoàn thiện nhất.
Các trường hợp fail


Các bức ảnh có độc phức tạp lớn hay có vật thể trong suốt, gương có thể gây ảnh hưởng đến kết quả. Thực nghiệm cũng cho thấy với các chi tiết nhỏ, hoặc màu gần trùng background cũng có thể làm sai lệch depth map và quá trình inpainting.
Kết quả thu được



4. Kết luận
Đây là một paper khá hay ho phải không nào. Các bạn hoàn toàn có thể dùng link colab này của tác giả nghịch ngợm thử, tạo 3D photography với DL từ chính bức ảnh của mình 
Bài viết của mình đến đây là kết thúc, cảm ơn các bạn đã quan tâm theo dõi
Nguồn
https://arxiv.org/abs/2004.04727
All rights reserved
