
Ảnh của bạn đã đẹp nay sẽ còn đẹp hơn với CodeFormer
Bài đăng này đã không được cập nhật trong 2 năm
Lời mở đầu
Lâu lắm rồi mới quay lại viết bài 🥲. Thôi vào đề luôn đi.
Việc chụp một bức ảnh đẹp thường bị ảnh hưởng bởi rất nhiều yếu tố: thiết bị di động, khung cảnh, góc chụp, khoảng cách, thời điểm. Nếu trong một ngày mà bạn không may mắn thì chất lượng ảnh của bạn sẽ rất ba chấm: mờ, giật, nhiễu, v.v...
Hồi phục một bức ảnh mang ý nghĩa là gia tăng chất lượng cũng như độ chân thực của ảnh. Điều này có thể thực hiện bởi AI, bằng cách trích xuất đặc trưng quan trọng của ảnh chất lượng thấp, sau đó ánh xạ, gia tăng, tự sinh mật độ điểm ảnh, ... Ta có thể thu được ảnh chất lượng cao, nhưng điều này rất khó bởi việc ánh xạ chất lượng ảnh (thấp-cao) không chắc chắn và sự thiếu sót các chi tiết đặc trưng trong ảnh.
Trong những năm gần đâ, có rất nhiều nghiên cứu được xuất bản như hồi phục ảnh thông qua hình học, mô hình sinh, tham khảo ảnh chất lượng cao khác. Các nghiên cứu này có thể quan sát kết cấu (texture) và chi tiết của ảnh khi cải thiện nhưng vẫn chưa đảm bảo được chất lượng đầu ra.
Có vẻ như mô hình sinh đang là giải pháp tốt nhất để phục hồi ảnh, nhưng bạn cũng biết rồi đấy mô hình "tốt" sẽ phụ thuộc vào "latent space". Nếu chưa biết "latent space" là gì thì có thể tham khảo bài viết này: https://viblo.asia/p/tim-hieu-ve-latent-space-LzD5dvaOZjY. Ảnh được tạo bởi mô hình sinh có thể có chất lượng rất cao, nhưng tính chân thực lại khó mà đánh giá được, cái này phụ thuộc vào độ chính xác của "latent space".
- Chất lượng ảnh (quality): độ sắc nét của ảnh
- Độ chân thực (fidelity): giả sử bạn tự sướng bằng cách chụp mặt, vậy bạn phải cân nhắc xem ảnh có giống/khác bản thân hay không.
Hôm nay tôi sẽ giới thiệu cho các bạn một nghiên cứu về phục hồi/nâng cao chất lượng/độ chân thực của ảnh: Towards Robust Blind Face Restoration with Codebook Lookup Transformer (https://arxiv.org/abs/2206.11253)
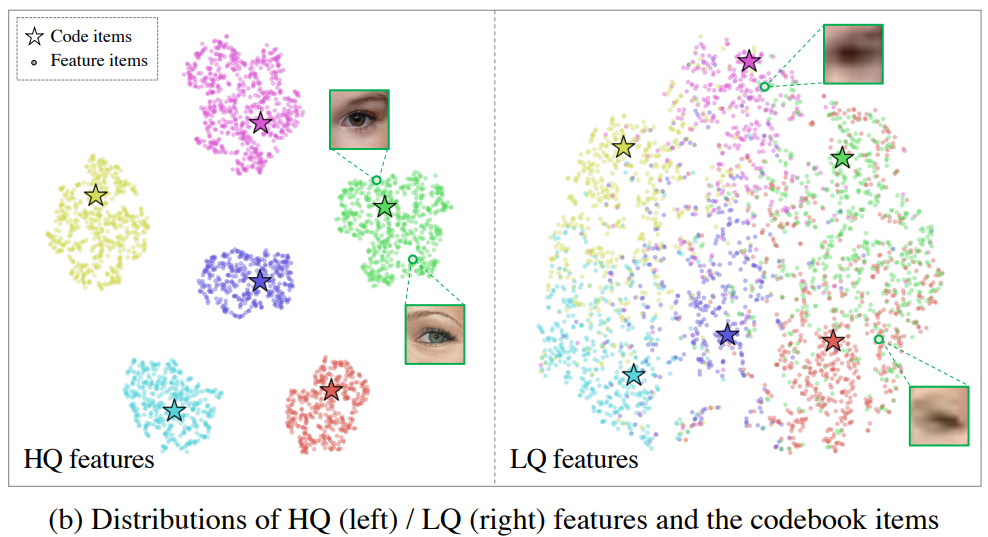
Qua hình trên, ta thấy được sự phân bố đặc trưng của của ảnh chất lượng thấp/cao khá rõ ràng, trực quan hóa bởi thuật toán t-SNE (https://en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding)
Nghĩ đơn giản thì việc phục hồi ảnh là "phân tách các đặc trưng trong ảnh chất lượng thấp theo từng nhóm riêng (các bộ phận trên khuôn mặt trong hình)" 🐧  .
.
Okay, chúng ta đến phần tiếp theo nào.
Giới thiệu
Nếu bạn không thấy hứng thú với lý thuyết thì bỏ qua, chỉ cần ngó qua phần này là được. Tác giả đã xây dựng 1 pipeline hoàn chỉnh rồi và nó dựa trên repo này: https://github.com/XPixelGroup/BasicSR
Mình có chạy qua notebook trên github repo và dịch lại bằng tiếng việt ở link bên dưới: https://colab.research.google.com/drive/1pA9xK87gE2qj0rtkfuagFuunhpkdGsv4?hl=vi
Link colab gốc: https://colab.research.google.com/drive/1m52PNveE4PBhYrecj34cnpEeiHcC5LTb?usp=sharing
Lý thuyết
Đầu tiên, làm một phép so sánh giữa các mô hình sinh trong nghiên cứu phục hồi ảnh phát

Với cùng một ảnh chất lượng thấp, khi đi qua các mô hình sinh (d-e) như: PULSE (https://arxiv.org/abs/2003.03808) và GFP-GAN (https://arxiv.org/abs/2101.04061) đều có sự bấp bênh trong chất lượng cũng như tính chân thực của ảnh. Còn với CodeFormer (g), ảnh sinh ra trông có vẻ rất nét và khá giống ảnh gốc (i) - ngoại trừ thiếu nếp nhăn, chi tiết của kính mắt, tính chân thực của da mặt  .
.
Tại sao ảnh các mô hình sinh này khác nhau đến vậy, âu cũng là do cách tiếp cận khác nhau, PULSE và GFP-GAN dùng continuous prior còn CodeFormer thì dùng discrete prior. Bạn có thể tìm hiểu qua bài viết này: https://synthesis.ai/2023/03/21/generative-ai-ii-discrete-latent-spaces/

CodeFormer cũng thêm mô hình Transformer để nâng cao chất lượng và độ chân thực của ảnh.
Chi tiết về CodeFormer sẽ được đề cập dưới đây
CodeFormer Framework
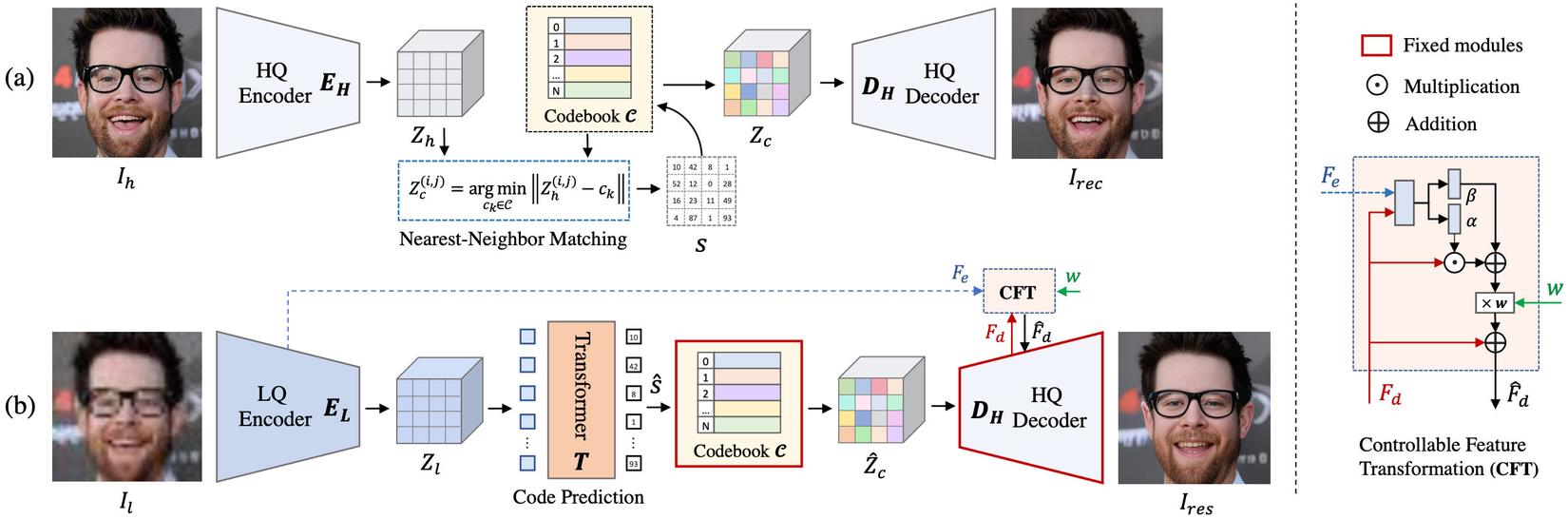
Pipeline của Codeformer có thể chia thành 3 phần: Codebook learning, Codebook Lookup Transformer Learning, Controllable Feature Transformation.
Codebook learning (a)
-
Ảnh chất lượng cao được mã hóa thành một không gian nén các đặc trưng của ảnh bởi encoder .
-
Theo đó, được đưa vào mô hình VQVAE (Vector Quantized Variational AutoEncoder - https://arxiv.org/abs/1711.00937), còn được gọi là self-reconstruction learning, đầu ra là codebook sẽ thay thế từng pixel trong bằng các pixel gần nhất bằng thuật toán Nearest-Neighbor Matching (https://www.statisticshowto.com/nearest-neighbor-matching/), quá trình này lặp đi lặp lại nhằm thu được đặc trưng được lượng tử hóa (quantize) và chuỗi token tương ứng
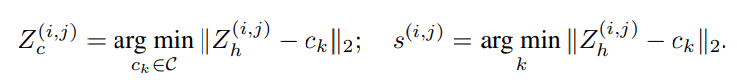
- Cuối cùng, sẽ được giải mã lại thành ảnh có chất lượng cao bởi decoder .
Tất nhiên không thể thiếu được bước huấn luyện mô hình VQVAE, các hàm mất mát (loss) được sử dụng là: L1 loss (https://amitshekhar.me/blog/l1-and-l2-loss-functions), VGG19 perceptual loss (https://saturncloud.io/glossary/perceptual-loss-function/), adversarial loss (https://neptune.ai/blog/gan-loss-functions).
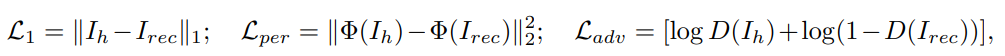
Tác giả cũng thêm một hàm loss nữa để giảm thiểu khoảng cách giữa đặc trưng được quantize và đặc trưng mã hóa của ảnh :
![]()
- : stop-gradient operator (https://www.researchgate.net/figure/Effect-of-stop-gradient-operators-The-top-and-bottom-rows-show-images-from-two-different_fig3_361922006)
- : điều chỉnh tốc độ cập nhật trọng số
Tóm lại, hàm mất mát tổng quát khối codebook sẽ là tổng của tất cả các hàm mất mát kể trên:
![]()
Mục tiêu chính của bước này là lưu trữ các phần hiển thị trên khuôn mặt có chất lượng cao.
Codebook Lookup Transformer Learning
-
Ảnh chất lượng cao được mã hóa thành một không gian nén các đặc trưng của ảnh bởi encoder . Encoder được finetune từ encoder .
-
đi qua mô hình Transformer (https://pbcquoc.github.io/transformer/), chứa 9 khối self-attention. Công thức tính các khối -th self-attention là:
![]()
- Q, K, V là gì thì mời bạn bấm vào link phía trên
-
Đầu ra của mô hình Transformer sẽ được đưa qua codebook đã huấn luyện ở bước 1. Tất nhiên đầu ra sẽ khác với bước 1 do đặc trưng của ảnh chất lượng thấp sẽ khác với ảnh chất lượng cao (xem lại hình ở lời mở đầu).
-
Cuối cùng đưa vào decoder để giải mã về ảnh chất lượng cao. Decoder giữ nguyên từ bước 1,
Huấn luyện: với việc giữ nguyên codebook và decoder từ bước 1, bước 2 thêm module Transformer và finetune encoder thì hàm mất mát sẽ có sự thay đổi:
- Cross-entropy loss : giám sát sự khác nhau giữa và . Trong đó là chuỗi token bước 1 và là chuỗi token bước 2.

- L2 loss : giám sát sự khác nhau giữa và , đẩy các đặc trưng của càng gần càng tốt. Tương tự là đầu ra của codebook ở bước 1.
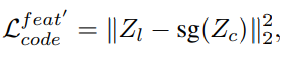
=> Hàm mất mát của Transformer ở bước 2 là:
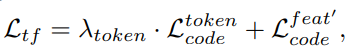
Mục tiêu chính của bước này là phục hồi khuôn mặt của ảnh chất lượng thấp thành ảnh chất lượng cao. Module chính để thực hiện điều này là Transformer, dự đoán chuỗi token - tượng trưng cho khuôn mặt trong không gian của codebook. Qua việc cập nhật trọng số theo từng lần lan truyền ngược (backpropagation). chất lượng của ảnh sẽ dần dần được cải thiện.
Controllable Feature Transformation
Tuy nói bước 2 là bước hồi phục ảnh, nhưng tác giả còn thêm module Controllable Feature Transformation (CFT) để điều chỉnh giữa chất lượng và độ chân thực của ảnh theo nhu cầu.
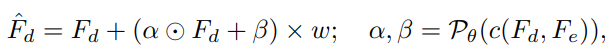
- : các đặc trưng của ảnh chất lượng thấp, đầu ra của encoder .
- : các đặc trưng của ảnh chất lượng cao, đầu ra của decoder .
- : nằm trong khoảng : tham số trực tiếp điều chỉnh giữa chất lượng và độ chân thực của ảnh. nhỏ - chất lượng cao, ngược lại lớn - độ chân thực cao.
- : 2 đặc trưng và nối nhau (concat).
- : tập hợp các phép tích chập để dự đoán và .
- và : các tham số để điều chỉnh một chút dựa trên .
Huấn luyện: hàm mất mát tổng quát của module CFT là tổng các hàm mất mát của cả bước 1 và bước 2 (ngoại trừ việc - đầu ra của decoder bước 2 thay thế - đầu ra của decoder bước 1).
Lời kết
Thực ra còn vài phần nữa: cấu trúc của codebook, thử nghiệm với bộ dữ liệu nào, so sánh giữa các nghiên cứu hồi phục ảnh, ... Nhưng thôi mệt rồi, mình stop 🙇.
Bài viết dựa trên việc mình đọc và mày mò cá nhân paper này nên nếu có gì sai sót thì mong các bạn bỏ qua cho.
Chân thành cám ơn tác giả của paper. Bạn nào ghé qua đọc thấy ổn thì tiếc gì cho mình 1 like. Thank you very much !!!
Tham khảo
Tất cả link mình trích dẫn bên trên
All rights reserved
