


Bài viết được ghim

Độ hot của Langchain
Langchain là một framework vô cùng hot hit trong thời gian gần đây. Nó được sinh ra để tận dụng sức mạnh của các mô hình ngôn ngữ lớn LLM như ChatGPT, LLaMA... để tạo ra các ứng dụng trong thực tế. Dù mới được phát triển cách đây khoảng 6 tháng (10/2022) và vẫn được cập nhật liên tục hàng ngày nhưng trên Github Langchain đã nhận được những tương tác khủng với lượng star lê...

Tất cả bài viết
Giới thiệu MMDetection
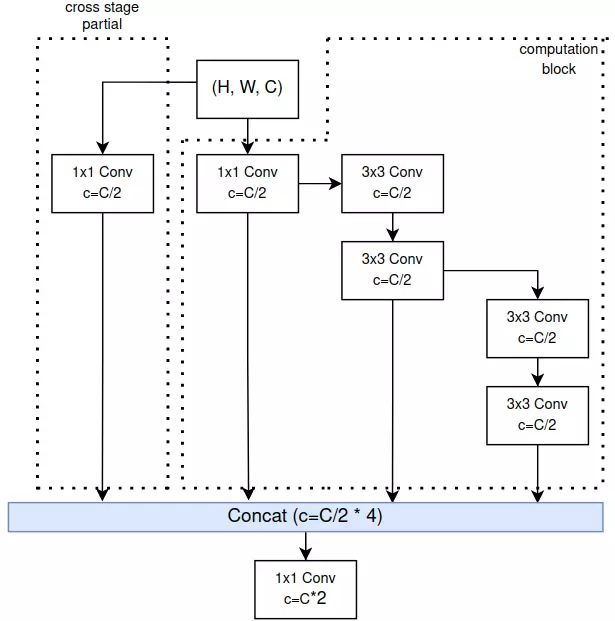
MMDetection là một thư viện chuyên phục vụ cho các bài toán liên quan đến Object Detection, được tạo ra bởi OpenMMLab, cha đẻ của rất nhiều thư viện khác như MMCV, MMSegmentation,...
 Lưu ý, nên xem bài viết này trong lúc mở sẵn github của MMDetection hoặc một IDE có MMDetection để có thể hiểu được tốt nhất
Ưu điểm
Lưu ý, nên xem bài viết này trong lúc mở sẵn github của MMDetection hoặc một IDE có MMDetection để có thể hiểu được tốt nhất
Ưu điểm
- Tính module hóa cực cao, mọi...
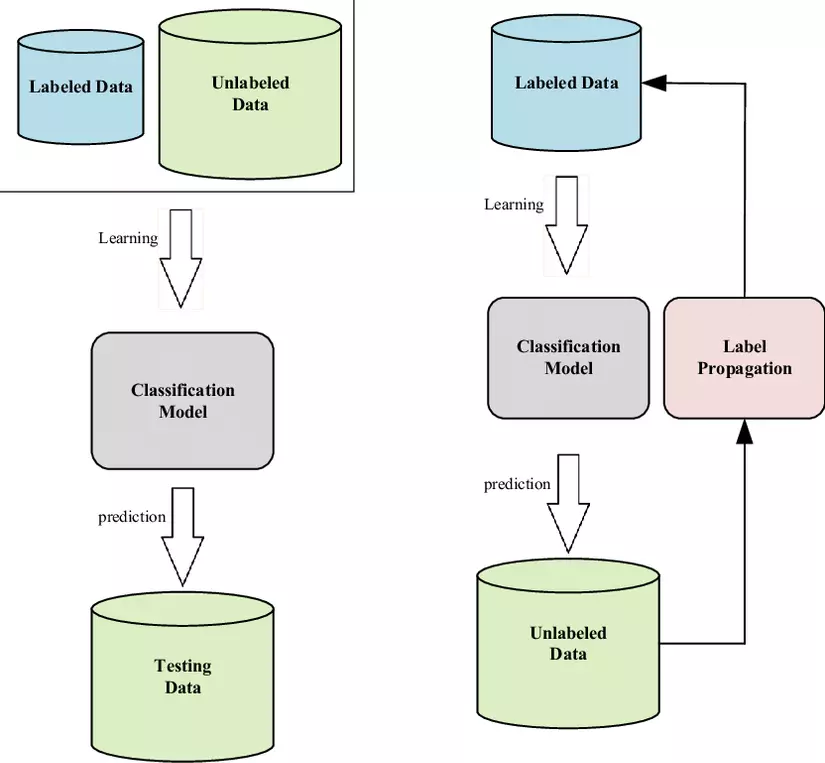
Lời mở đầu Các mô hình Deep Learning thường có xu hướng đối dữ liệu - data hungry. Đối với các nhiệm vụ cụ thể, nếu như được cung cấp một lượng đầy đủ dữ liệu có những thì các thuật toán supervised learning có thể xử lý rất tốt. Để đạt được hiệu năng cao thì mô hình thường đòi hỏi một lượng khá lớn các dữ liệu có nhãn và chi phí để gán nhãn dữ liệu thường là rất đắt đỏ. Ngược lại, các nguồn dữ...
Mở đầu
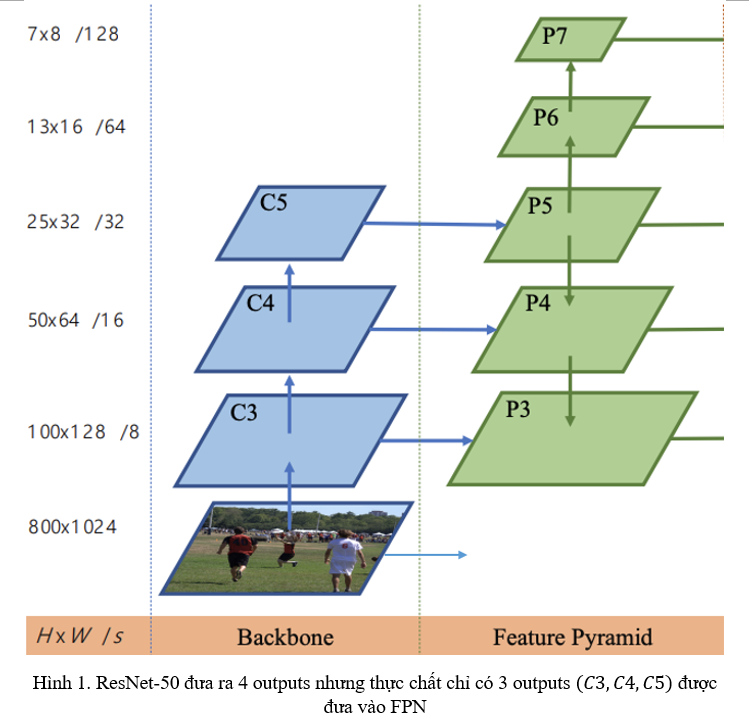
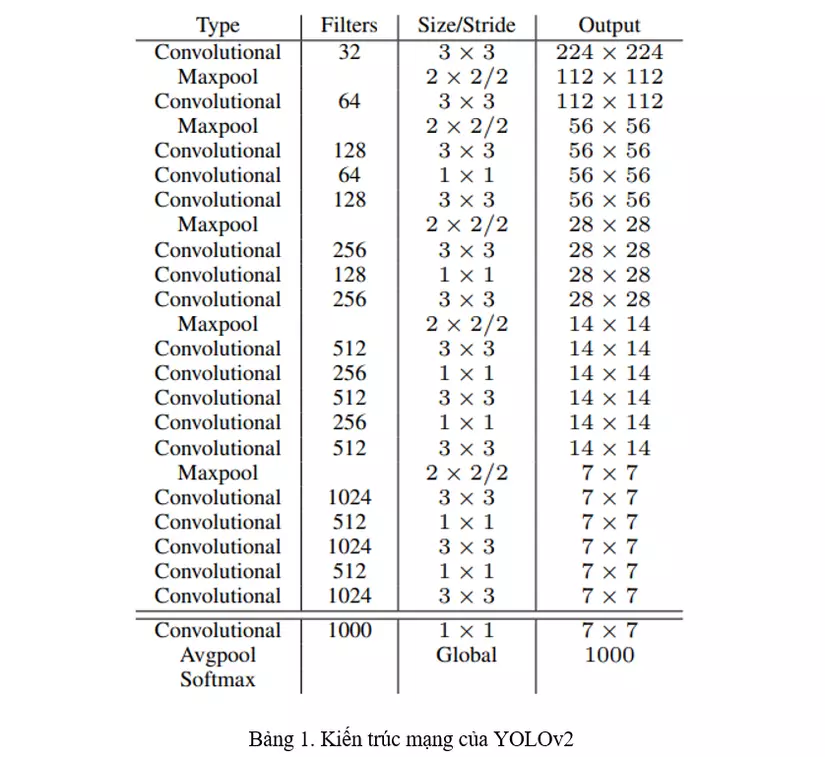
Ở bài viết lần trước, mình đã trình bày về YOLOv1: Lý do tại sao YOLO lại ra đời, đồng thời phân tích ý tưởng chính và hàm Loss của YOLOv1. Tiếp tục với series phân tích YOLO, lần này mình sẽ trình bày về 2 phiên bản khác trong họ nhà YOLO, cụ thể là YOLOv2 và YOLOv3. Mình sẽ tập trung phân tích về kiến trúc mạng, những thay đổi trong quá trình training, cách sử dụng Anchor Box cũng như...
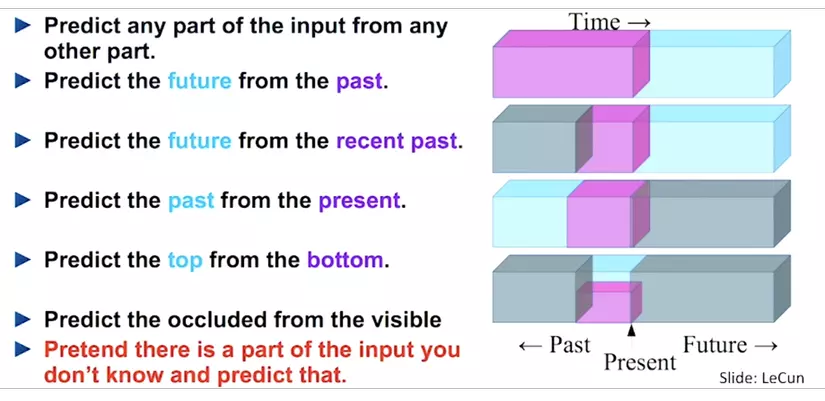
Xin chào các bạn, tiếp nối bài viết trước về Active Learning - một trong những phương pháp hữu hiệu để xử lý đối với trường hợp thiếu dữ liệu có nhãn. Bài viết này mình xin phép được chia sẻ với các bạn một phương pháp khác đó là semi-supervised learning hay còn gọi với cái tên khác là học bán giám sát. Và không còn chần chừ gì nữa chúng ta sẽ bắt đầu ngay thôi. Gét gô.
Semi supervised learnin...
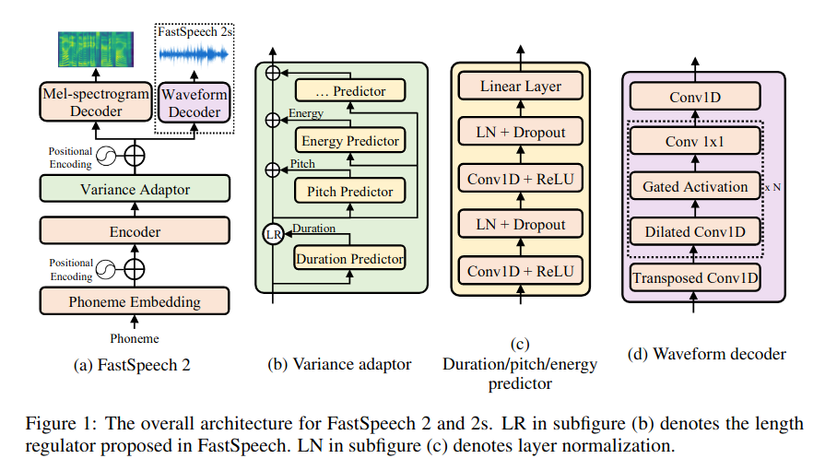
- FastSpeech 2
3.1 Giới thiệu
1 số mô hình non-autoregressive TTS như FastSpeech có khả năng sinh giọng nói nhanh hơn các mô hình autoregressive với độ chính xác tương đương. Việc huấn luyện mô hình FastSpeech phụ thuộc vào autoregressive teacher model để dự đoán thời lượng âm vị và knowledge distillation (chắt lọc tri thức), có thể giải quyết tốt các vấn đề one-to-many (1 văn bản có thể si...

- Tổng quan
- Các mô hình non-autogressive TTS song song trước đó, ví dụ như FastSpeech, có thể sinh mel-spectrogram nhanh hơn rõ rết so với autogressive models như Tacotron, cũng như giảm các lỗi về ngữ âm (lặp, mất từ). Tuy vậy, các nhược điểm trên được xử lý phần lớn nhờ attention map giữa text và speech.
- Các mô hình TTS song song trước thường sử dụng aligners từ bên ngoài như pre-trained...
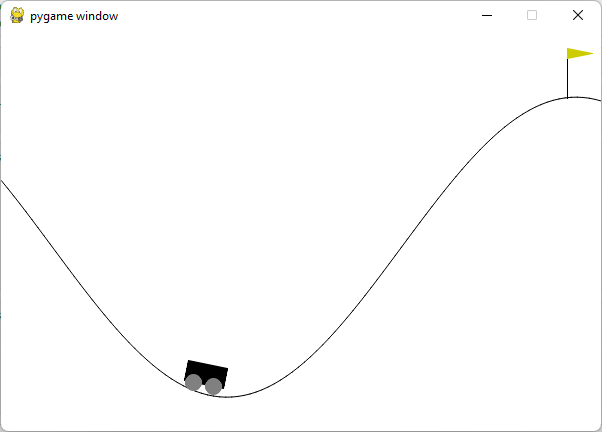
Xin chào các bạn. Tiếp nối series về Reinforcement Learning (RL), hôm nay mình xin giới thiệu một ví dụ đơn giản có thể coi như là "Hello world" của RL.
- Giới thiệu Trong bài trước Đôi điều cơ bản về học tăng cường mình đã giới thiệu một số khái niệm của RL. Trong đó môi trường và các trạng thái, phần thưởng là những yếu tố quan trọng. Để cho có thể học được những chiến lược tối ưu hoặc tìm...

Tiếp tục series Paper Explain đang dang dở về topic Action Recognition, trong bài viết này, mình muốn bàn một chút về data: Data Augmentation.
Chắc mọi người cũng đã biết rồi, bên cạnh một model tốt, thứ ảnh hưởng trực tiếp đến kết quả đầu ra, đó là chất lượng của dữ liệu. Việc xây dựng được một bộ dữ liệu sạch, số lượng lớn, tính tổng quát cao đôi khi improve còn tốt hơn việc sử dụng những mo...
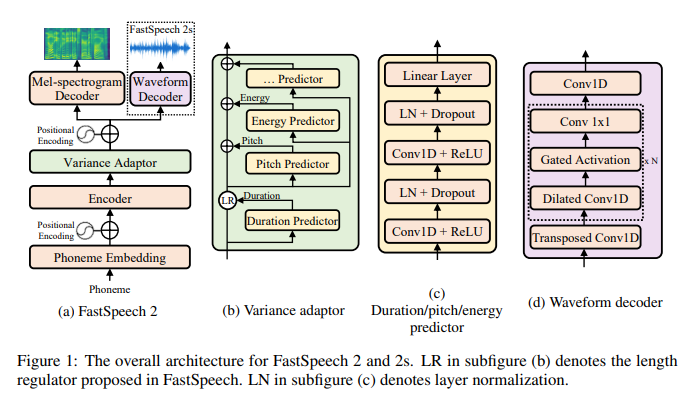
- FastSpeech2 có gì mới? FastSpeech - một non-aggressive model - có khả năng sinh ra giọng nói nhanh vượt trội so với các aggressive model thời bấy giờ với chất lượng gần tương đương nhờ xử lý khá tốt vấn đề one-to-many (1 phoneme ứng với nhiều mel-spectrogram). Dù vậy, nó vẫn có các nhược điểm:
- Việc xây dựng teacher-student pipeline theo phương pháp Knowledge distillation rất phức tạp và tố...
Bài viết hôm nay là về một bài toán cực lỳ phổ biến mà ai làm việc trong ngành này cũng từng không ít lần thử sức, đó là bài toán object detection. Trên Papers with code, bài toán này ghi nhận 2080 papers, 191 dataset, 61 benchmarks cả thẩy, và số lượng thực tế đương nhiên còn nhiều hơn thế. Ngay bây giờ, kể cả khi rất nhiều SOTA đã được trình bày, các vấn đề xoay quanh bài toán này vẫn đang ti...
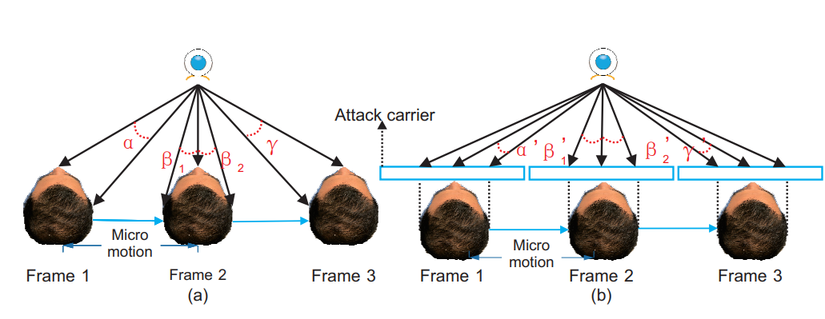
Xin chào, đây là bài viết thứ 2 của mình trong chuỗi series về Face Anti-Spoofing.
Xin chào, ở bài viết trước, mình đã giới thiệu tổng quan các vấn đề trong bài toán Face Anti-Spoofing, bài toán chống giả mạo khuôn mặt. Những chia sẻ ở bài viết trước bao gồm: giới thiệu bài toán, các phương pháp tấn công giả mạo (face attack methods), các phương pháp chống tấn công giả mạo phổ biến (face anti-...

- Giới thiệu
Ắt hẳn các bạn đang đọc đã từng biết đến ít nhất một môn cờ (cờ caro, cờ vua, cờ tướng, cờ vây, ...). Mỗi một môn cờ có những luật chơi, chiến thuật và không gian các nước đi khác nhau, như số nước đi hợp lệ trong cờ vua là nguyên tử (Universe today). Nếu bạn vẫn chưa hình dung ra nó nhiều như thế nào 😑 thì hãy cứ xem rằng nó rất rất lớn đến mức...
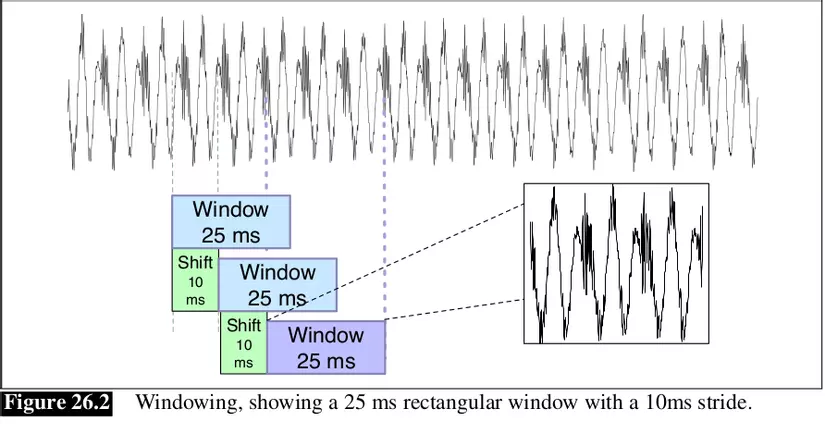
Hiểu được ngôn ngữ nói, hoặc là chuyển được âm thanh thành dạng chữ viết là 1 trong những mục tiêu đầu tiên của xử lý ngôn ngữ máy tính. Thực tế, xử lý tiếng nói đã được tiến hành bởi máy tính nhiều thập kỉ trước. Mục tiêu của automatic speech recognition (công nghệ tự nhận dạng giọng nói) là ánh xạ bất kì waveform nào:
về dạng chữ viết:
Tự động nhận dạng tiếng nói bởi bất kì người nào trong ...

Tiêu đề hơi giật tít một chút, nhưng gần đây, mình cùng team có tham gia một challenge được tổ chức bởi trung tâm nghiên cứu BKAI kết hợp với tập đoàn NAVER, trong 1 tác vụ về "Body Segmentation and Gesture Recognition", may mắn giật nhẹ cái :1stplacemedal: .
Thật ra thì tác vụ này bao gồm 2 phần chính (như chính tên tác vụ): Segmentation và Recognition. Nếu các bạn quan tâm về giải pháp đầy đ...
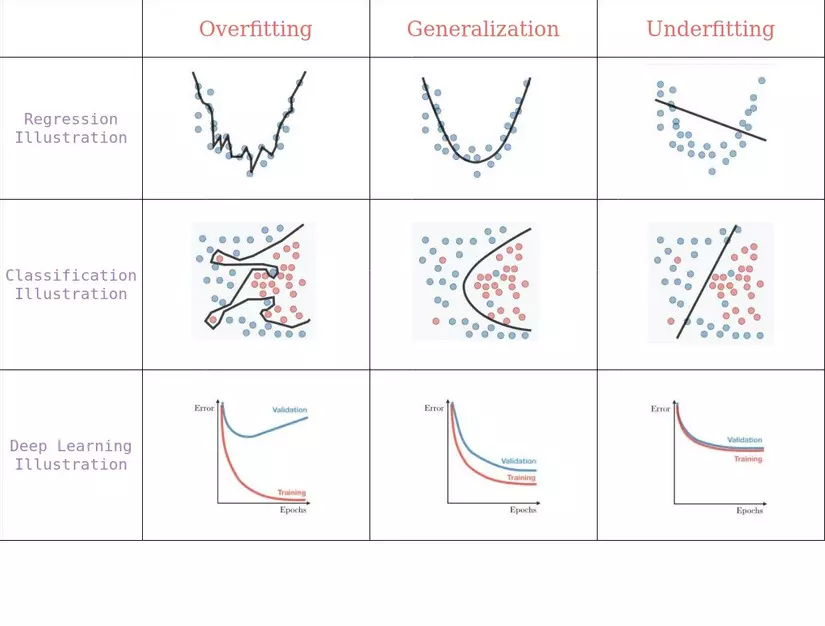
Machine learning (Học máy) là một ứng dụng của trí tuệ nhân tạo (AI) cung cấp cho các hệ thống khả năng tự động học hỏi và cải thiện từ kinh nghiệm mà không cần được lập trình rõ ràng.
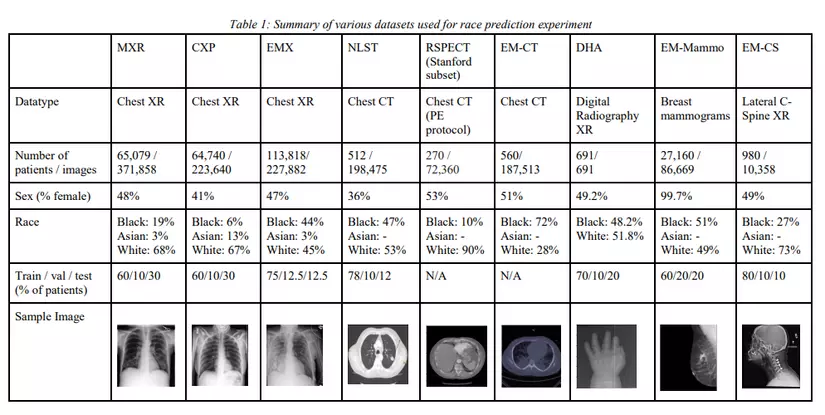
Một trong những phần khó trong Học máy là đánh giá hiệu suất của Mô hình. Vậy làm cách nào để đo lường sự thành công của một mô hình học máy? Làm thế nào chúng ta biết khi nào nên dừng việc đào tạo và đánh giá v...

Introduction Gần đây, nhiều nghiên cứu chỉ ra rằng StyleGAN có thể thực hiện style transfer chất lượng cao chỉ với một lượng dữ liệu hạn chế bằng một chiến lược fine tuning phù hợp. Paper Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer đề xuất một mở rộng của kiến trúc StyleGAN với intrinsic style path và extrinsic style path để mã hóa style của domain gốc và domain cần...
- Autogressive và Non-Autogressive model
- Autogressive model hiểu đơn giản chỉ là 1 feed-forward model mà dự đoán các giá trị tương lai dựa trên các giá trị quá khứ. Các kiến trúc TTS tiêu biểu cho Autogressive model có thể kể đến mô hình Tacotron và Tacotron2 được giới thiệu trong bài viết trước của mình
 Source: <a ...
Source: <a ...
Mở đầu Object Detection là một bài toán phổ biến trong Computer Vision. Mục tiêu của Object Detection là xác định và phân loại các object (vật thể) tồn tại trong ảnh, là một bài toán multi-task, thực hiện Classification và Regression (Localization) đồng thời. Ở những thời kì đầu tiên trong lĩnh vực này, các nghiên cứu tập trung vào việc sử dụng các hand-crafted feature (đặc điểm nhận dạng do co...
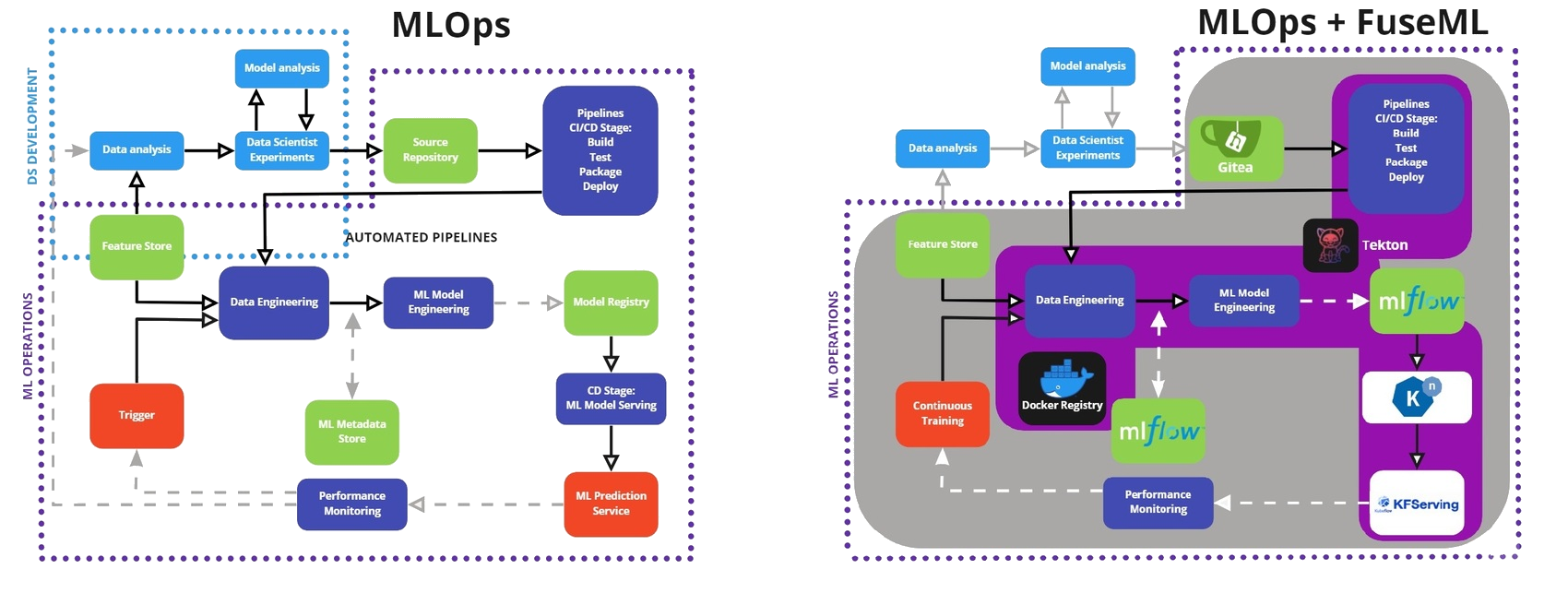
Vậy là chỉ 2, 3 tháng nữa là lại đến một mùa bảo vệ khóa luận/đồ án. Trên tình thần hỗ trợ các anh chị em bịa thêm một chương trong báo cáo của mình, bài viết này giới thiệu về giải pháp được cung cấp bởi SUSE để xây dựng một pipeline linh hoạt và hiệu suất cao nhằm đáp ứng xây dựng cũng như triển khai các mô hình học máy.
Ok nẹt gâu.
Giới thiệu về FuseML Việc xây dựng hệ thống Machine Learni...
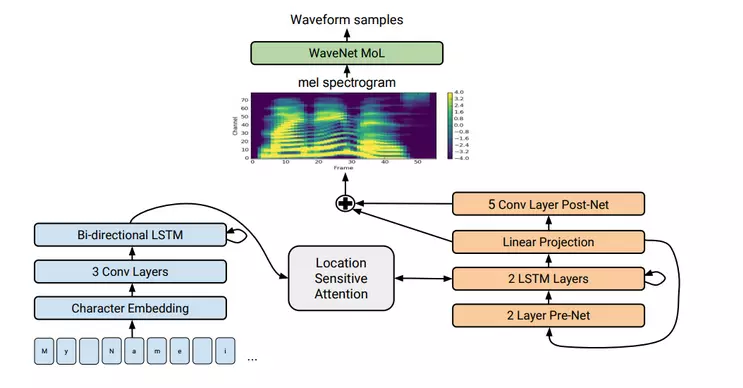
- Tacotron 2
Tacotron 2 là 1 mô hình tổng hợp tiếng nói trực tiếp từ văn bản đầu vào. Nó dựa trên sự kết hợp giữa convolution neural network (CNN) và recurrent neural network (RNN).
Có 2 thành phần chính trong Tacotron 2:
- 1 mạng seq2seq có tên Spectrogram Prediction Network dùng để dự đoán chuỗi mel spectrogram từ 1 chuỗi kí tự đầu vào.
- 1 phiên bản điều chỉnh của WaveNet tạo ra âm ...
