Crawl data đầy đủ hơn với thư viện selenium
Bài đăng này đã không được cập nhật trong 2 năm
Chào các bạn, chúng mình là unom và huytrao, hai sinh viên ngành khoa học dữ liệu đang nghiên cứu về các kỹ thuật thu thập và xử lý dữ liệu. Trong bài viết này, chúng mình xin chia sẻ về các bước crawl data một cách đầy đủ, giúp các bạn khắc phục vấn đề data bị khuyết sau khi crawl theo cách thông thường. Kiến thức trong bài viết này là do chúng mình tự nghiên cứu và tìm hiểu, nên chúng mình rất mong nhận được góp ý từ các bạn để cải thiện những thiếu sót cũng như các lỗi.
Lí do lại không nên dùng các công cụ thông thường để crawl data
- Dùng các công cụ thông thường sau khi crawl sẽ bị khuyết một số dữ liệu cần thiết của một trang web.
- Một số nội dung liên quan đến những dữ liệu ta cần lấy sẽ không đồng nhất.
- Định dạng không chính xác, dữ liệu trả về có thể không được chính xác đúng với trang web gốc.
Ưu điểm của phương pháp
- Độ chính xác cao khi crawl: Dữ liệu thu thập được thông qua Selenium thường chính xác và đáng tin cậy hơn so với việc chỉ sử dụng HTTP requests hoặc phân tích mã HTML tĩnh.
- Linh hoạt: Selenium có thể được sử dụng để xuất file HTML từ bất kỳ trang web nào, bất kể cấu trúc hoặc mã nguồn của trang web đó.
- Tính tái sử dụng: Selenium có thể được sử dụng để xuất file HTML từ nhiều trang web khác nhau giúp tiết kiệm thời gian và công sức.
- Đa nền tảng: Selenium hỗ trợ nhiều trình duyệt web phổ biến như Chrome, Firefox, Safari và Edge, điều này cho phép bạn thích nghi với các yêu cầu cụ thể của trang web và sử dụng trình duyệt phù hợp để thu thập dữ liệu.
Nhược điểm của phương pháp
- Selenium tốn khá nhiều tài nguyên máy tính và thời gian hơn so với việc sử dụng các phương pháp đơn giản hơn như HTTP requests và phân tích mã HTML tĩnh. Có thể mất vài phút đến vài giờ tùy vào nguồn dữ liệu chúng ta crawl.
- Selenium cũng yêu cầu bạn cài đặt trình duyệt web tương ứng và trình điều khiển (driver) cho trình duyệt đó ví dụ như ChromeDriver,EdgeDriver,.... Những thao tác này khá rối rắm và người sử dụng thường bỏ ra rất nhiều thời gian để có thể sử dụng được thư viện selenium.
- Để sử dụng Selenium, người dùng cần có kiến thức về lập trình và tự động hóa ứngTải trình điều khiển (driver) của trình duyệt tương ứng.
Phương thức thực hiện
Về phương thức thực hiện thao tác crawl data sử dụng thư viện selenium, chúng mình sẽ làm ví dụ thao tác có sử dụng thư viện selenium/request để xuất file html từ một trang web bất kì:
Cách xuất file html từ một trang web bằng thư viện selenium:
1. Thao tác trên Databricks:
B1. Cài đặt thư viện selenium:
- Tạo một cell trong notebook và nhập vào %pip install selenium để cài đặt thư viện selenium vào Databricks.
B2. Tải trình điều khiển (driver) của trình duyệt tương ứng:
- Ở đây ta sẽ tải ChromeDriver bằng cách tạo một cell mới và chạy code sau
![image.png]()
- Sau bước này ChromeDriver sẽ được tự động cài đặt vào Databricks của bạn.

B3. Import các module cần thiết:
- Trên Azure Databricks, bạn cần import các module cần thiết cho Selenium
![image.png]()

B4. Cấu hình trình duyệt và trình điều khiển:
- Cần cấu hình trình duyệt và trình điều khiển để Selenium có thể sử dụng. Sau bước này chúng ta có thể sử dụng thư viện selenium để thực hiện các thao tác tương ứng.
![image.png]()

B5. Sau đó chúng ta chỉ cần 2 dòng code thì đã có thể xuất được file html từ một trang web bất kì:

- Nếu muốn in ra để xem nội dung của file html chúng ta có thể sử dụng lệnh: display(html_content).
2. Thao tác trên máy tính cá nhân:
B1. Install thư viện selenium:
- Vào commant prompt và install thư viện selenium bằng cách nhập vào cmd dòng pip install selenium.
B2. Sau đó tạo một cell trong jupiter notebook và nhập các dòng code sau để xuất file html từ web:
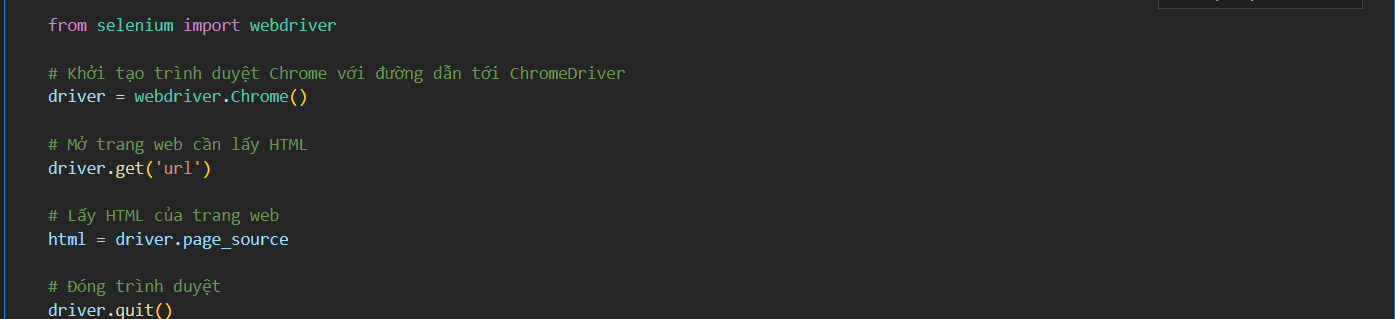
3. Thao tác trên Google Colab:
B1. Tạo 1 cell trong jupiter notebook của Google Colab và cài đặt thư viện selenium.

B2. Cài đặt ChromeDriver trên Google Colab bằng lệnh !pip install chromedriver-autoinstaller.
![]()
B3. Thêm đường dẫn tới thư mục chứa ChromeDriver vào danh sách các đường dẫn tìm kiếm của Python.

B4. Import các thư viện và setting cần thiết để dùng thư viện selenium trên Google Colab.

B5. Thao tác sử dụng selenium để xuất nội dung html.

Cách xuất file html từ một trang web bằng thư viện request:
B1: Import thư viện request:

B2: Thao tác xuất file html:

B3: In ra nội dung của file html:
- Dùng lệnh print(html_content).
So sánh kết quả của hai thư viện selenium và request
- Chúng mình sẽ lấy ví dụ với url là https://www.microsoft.com/vi-vn/, sau đó xuất ra kết quả theo như các bước hướng dẫn ở phần Phương thức thực hiện và sau đó dùng Live Server để so sánh.
Nếu sử dụng thư viện selenium để thao tác thì chúng ta sẽ nhập code sau:
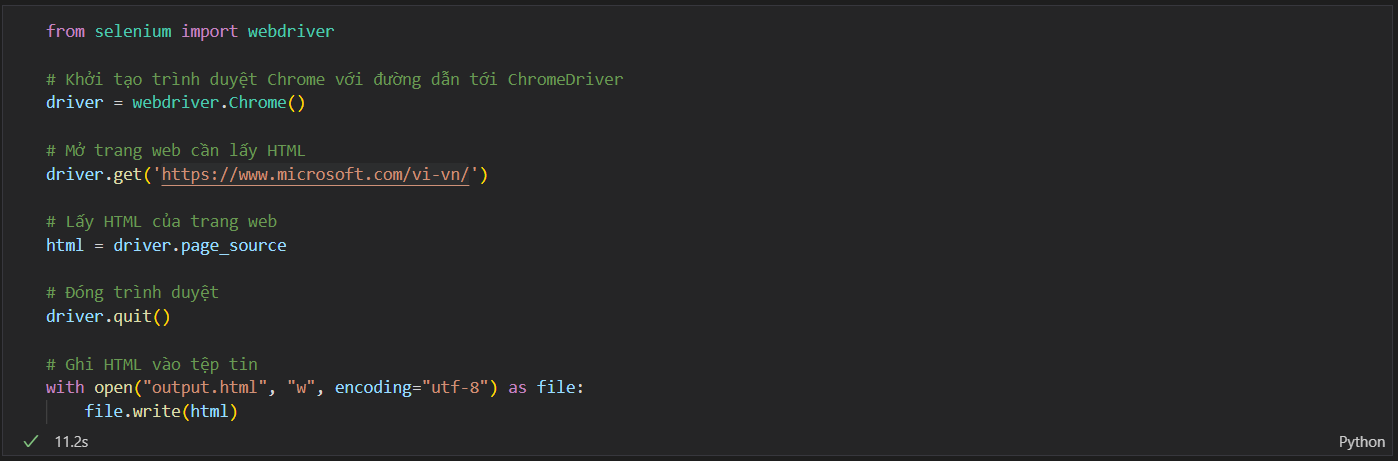
- Execute thành công chúng ta sẽ có một file output.html là file html của trang web trên, sau đó chúng ta sẽ dùng tính năng Live Server (có thể install trong Visual Studio Code,...) để check kết quả.
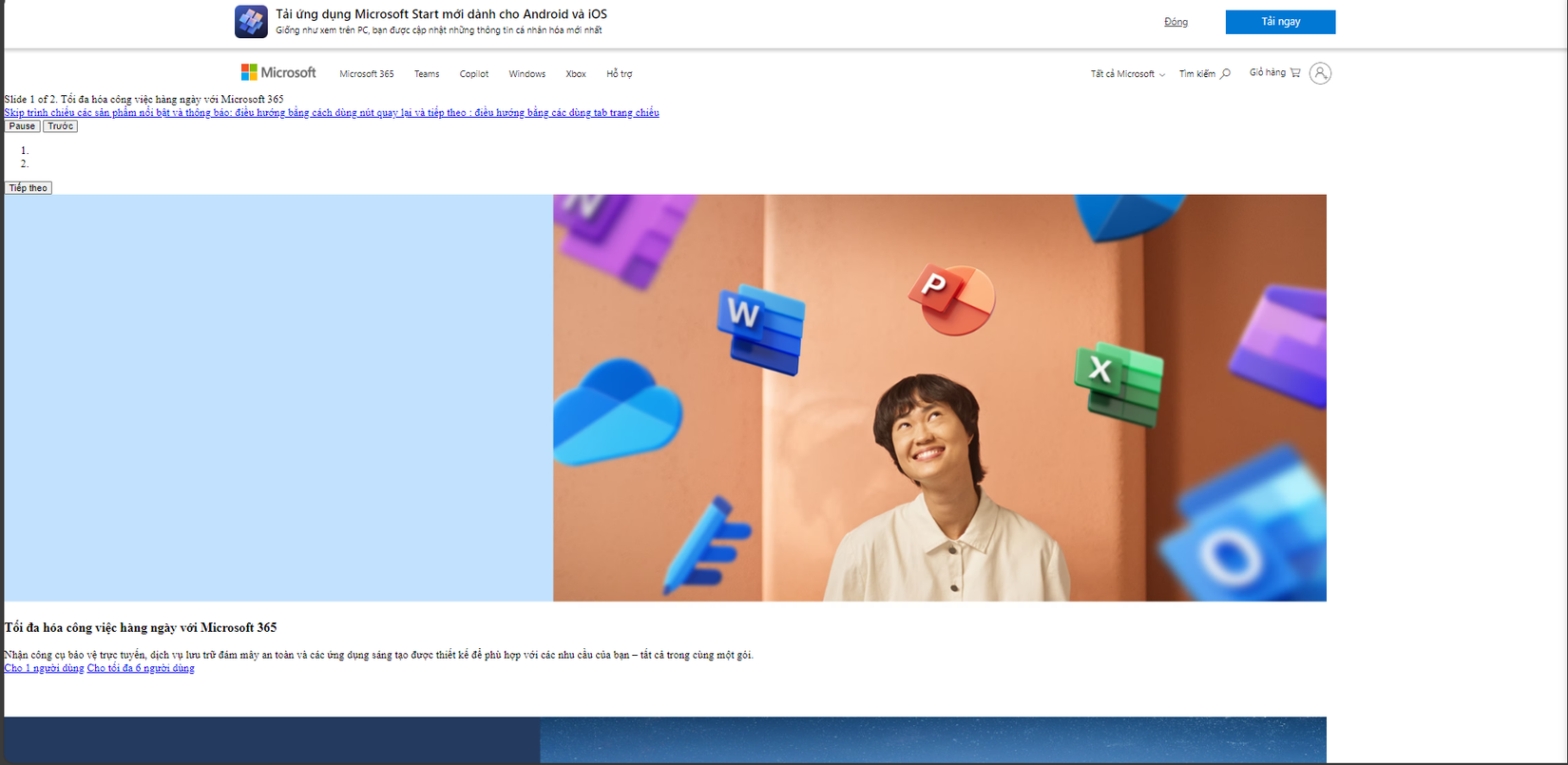
- Cách để chạy Live Server với file output.html chúng ta sẽ click chuột phải và nhấp chọn Open with Live Server hoặc nhấp tổ hợp phím ALT+L+ALT+O, sau bước này chúng ta nhận được kết quả như sau.
![image.png]()
- Về cơ bản chúng ta đã lấy được các thông tin cần thiết trong url.
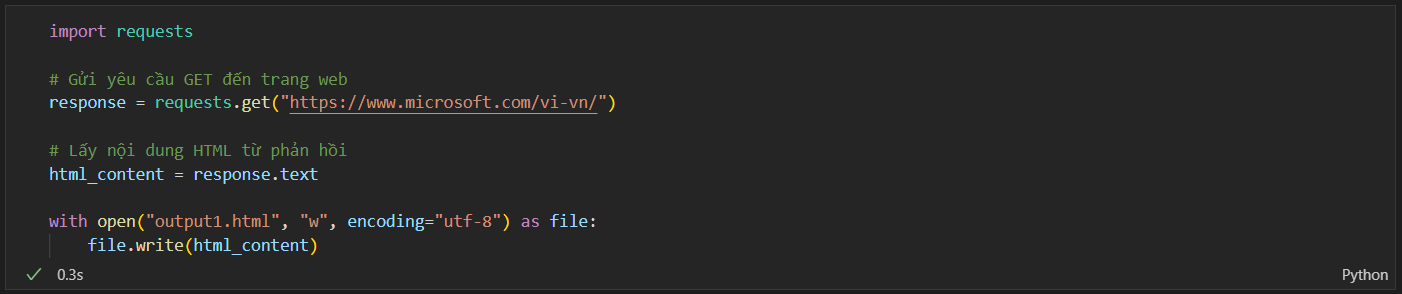
Với việc sử dụng thư viện request chúng ta sẽ nhập vào các dòng code sau vào jupter notebook.
- Code.
![image.png]()
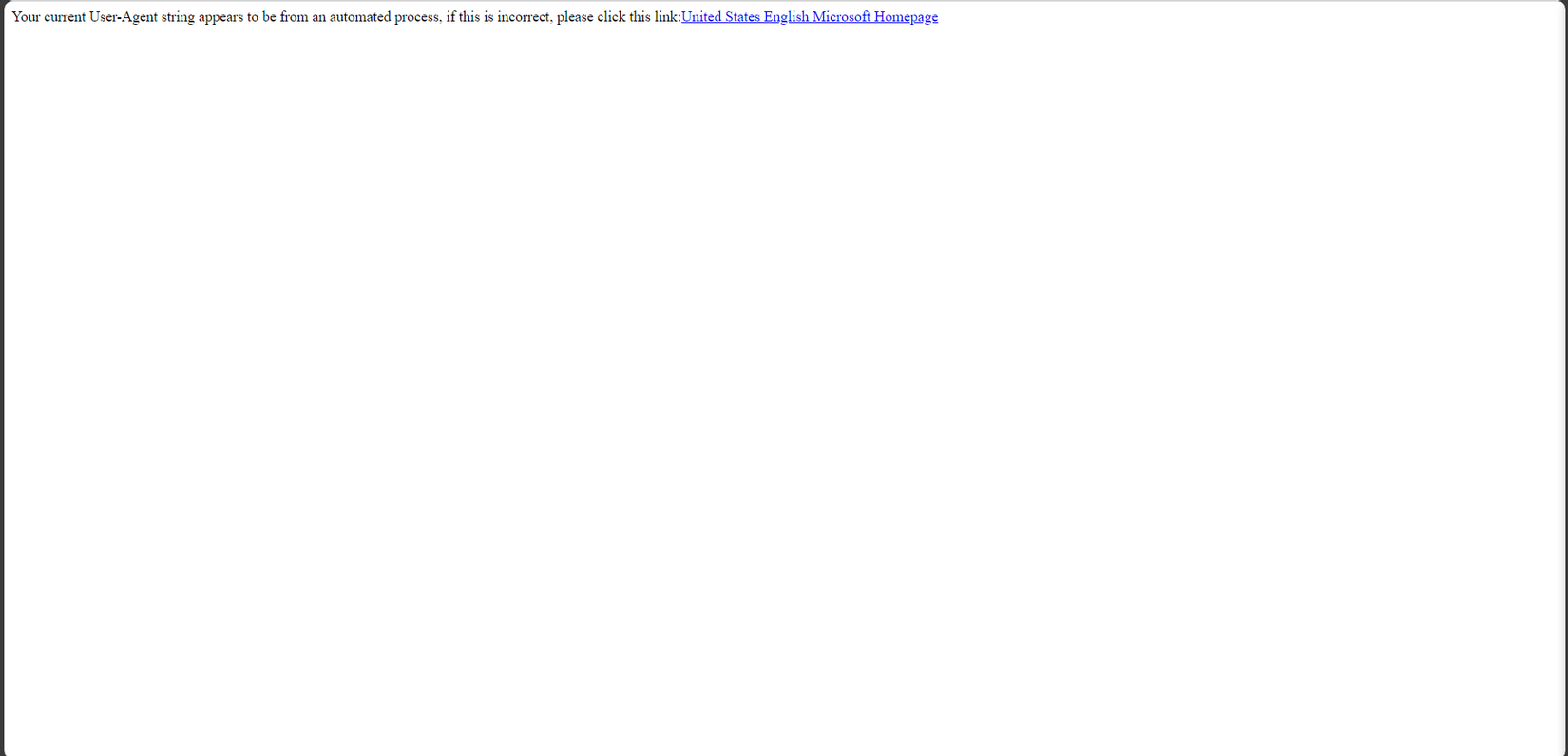
- Sau khi execute thành công chúng ta sẽ thu được một file output1.html lưu nội dung html của url, sau đó dùng Live Server tương tụ như trên và nhận được kết quả sau.
![image.png]()
- Đối chiếu với kết quả của thư viện selenium ở trên chúng ta có thể thấy rõ ràng việc xuất file html bằng thư viện selenium sẽ xuất ra file html thông tin của trang web hiệu quả hơn cách dùng thư viện request dù thời gian tương tác không nhanh bằng.
Lời kết
-
Như vậy, bài viết đã giới thiệu về phương pháp crawl data bằng thư viện Selenium. Phương pháp này có những ưu điểm như độ chính xác cao, linh hoạt, tái sử dụng và đa nền tảng.
-
Dù phương pháp này cũng có những nhược điểm như tốn nhiều tài nguyên máy tính và thời gian, yêu cầu cài đặt trình duyệt web và trình điều khiển, tuy nhiên với những ưu điểm vượt trội của mình phương pháp crawl data bằng thư viện Selenium là một lựa chọn phù hợp cho những trường hợp cần thu thập dữ liệu chính xác và đầy đủ từ các trang web.
-
Hi vọng bài viết này sẽ giúp ích cho các bạn trong quá trình crawl data.
All rights reserved
